
엔비디아가 임베디드 모듈 시스템 젯슨(Jetson) TX1 및 TX2용 리눅스(Linux) 기반 소프트웨어 제품군인 제트팩(JetPack) 3.1을 공개했습니다.
텐서RT(TensorRT) 2.1 및 cuDNN 6.0으로 업그레이드된 제트팩 3.1은 가속화된 배치 사이즈 1을 활용할 수 있는 비전 가이드 내비게이션 및 모션 컨트롤과 같은 실시간 애플리케이션에서 딥 러닝 성능을 최대 2배 가량 향상시키는데요. 제트팩 3.1의 개선된 기능은 젯슨이 배포할 수 있는 인텔리전스 수준을 이전보다 비약적으로 향상시켜, 배달 로봇, 원격현실감(telepresence), 동영상 분석 등 새로운 세대의 자동화 기계(autonomous machines) 구현이 가능해질 전망입니다.
최근 엔비디아는 로봇공학의 발전을 촉진하기 위해 첨단 인공지능의 트레이닝 및 실전 배포용 올인원 플랫폼인 아이작 이니셔티브(Isaac Initiative)를 공개한 바 있습니다.

엣지에 적용되는 인공지능
올해 초 엔비디아가 발표한 엣지 컴퓨팅용 플랫폼인 젯슨 TX2(Jetson TX2)는 기능 면에서 상당한 발전을 달성했습니다.
그림 1의 웨이브 글라이더 플랫폼에서 단적으로 드러난 것처럼, 네트워크 엣지에 위치한 원격 사물인터넷(IoT) 장치에서는 네트워크 범위(network coverage), 지연율(latency) 및 대역폭(bandwidth)이 저하되는 현상이 발생하는데요.
보통 사물인터넷 장치가 데이터를 클라우드로 중계하는 게이트웨이 역할을 하는 것에 비해, 엣지 컴퓨팅은 보안이 적용된 온보드 연산 리소스에 접근하기 때문에 사물인터넷의 가능성을 새롭게 정의할 수 있습니다. 엔비디아의 젯슨 임베디드 모듈은 초당 1테라플롭(TELOP)의 서버급 성능을 구현하며, 젯슨 TX2에서는 10와트 미만의 전력에서 2배의 인공지능 성능을 전달합니다.
제트팩 3.1
테그라(Tegra)용 리눅스(L4T) R28이 포함된 제트팩 3.1은 장기적인 지원을 제공하는 젯슨 TX1 및 TX2용 소프트웨어 제품군입니다. TX1 및 TX2용 L4T 보드 지원 패키지(BSPs)는 고객 제품화에 적합하며, 공유된 리눅스 커널 4.4 코드 기반 두 제품 간의 호환성 및 원활한 포팅을 제공합니다. 제트팩 3.1부터 개발자들은 TX1과 TX2에서 전부 동일한 라이브러리, API 및 도구 버전을 이용할 수 있습니다.
cuDNN 5.1에서 6.0으로 업그레이드 및 CUDA 8로 유지보수 업데이트가 이루어진 것 외에도, 제트팩 3.1에는 스트리밍 애플리케이션 구축을 위한 최신 비전 및 멀티미디어 API가 포함되어 있는데요. 호스트 PC로 제트팩 3.1을 다운로드하면 젯슨에 최신 BSP 및 도구를 적용할 수 있습니다.
텐서RT 2.1을 활용한 저지연 추론
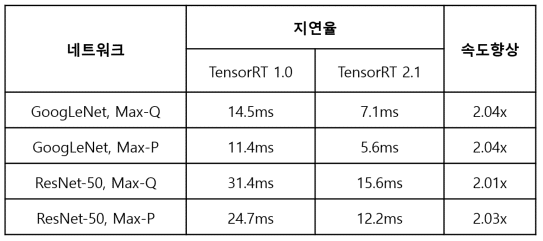
최신 버전의 텐서RT가 포함된 제트팩 3.1은 젯슨에 최적화된 런타임 딥 러닝 추론을 배포할 수 있습니다. 텐서RT는 네트워크 그래프 최적화, 커널 퓨전, 반정밀도 FP16을 지원함으로써 추론 성능을 향상시킵니다. 텐서RT 2.1에는 멀티 가중치 배칭 등 젯슨 TX1 및 TX2의 딥 러닝 성능과 효율성은 대폭 향상시키고 지연율은 감소시키는 핵심 기능 및 기능 개선이 포함되어 있습니다.
배치 사이즈 1의 현격히 개선된 성능은 GoogLeNet의 지연율을 5ms로 감소시키는데요. 지연율에 민감한 애플리케이션의 경우, 각 프레임이 시스템에 도착하는 즉시 처리되기 때문에 배치 사이즈 1은 가장 낮은 지연율을 제공하게 됩니다. 텐서RT 2.1은 GoogLeNet 및 ResNet 이미지 인식 추론을 위한 처리량에 있어서 텐서RT 1.0 대비 2배 이상을 달성할 수 있습니다.

텐서RT 2를 적용하면, 젯슨 TX2는 Max-P 성능 프로파일에서 GoogLeNet의 지연율이 5ms를, Max-Q 효율성 프로파일에서는 지연율이 7ms를 기록하게 됩니다. ResNet은 보통 이미지 분류에서 텐서RT 2.1을 통해 2배 이상 개선된 런타임 성능을 구현하는 GoogLeNet를 능가하는 정확도 향상을 위해 사용됩니다. 또한 젯슨 TX2의 8GB 메모리 용량 덕분에, ResNet과 같은 복잡한 네트워크에서조차 최대 128까지 대형 배치 사이즈 실행이 가능하답니다.
이처럼 지연율이 감소되면, 고속 드론, 선박의 충돌 방지, 자동화 내비게이션 등 실시간에 가까운 반응성을 요구하는 애플리케이션에서도 딥 러닝 추론 접근 방식이 활용될 수 있습니다.
맞춤형 레이어
텐서RT 2.1은 사용자 플러그인 API를 통해 맞춤형 네트워크 레이어를 지원, ResNet, 리커런트 뉴럴 네트워크(RNN), You Only Look Once(YOLO) 및 Faster-RCNN 등 확장된 지원을 제공하는 첨단 네트워크 및 기능을 구동할 수 있습니다.
#include “NvInfer.h”
using namespace nvinfer1;
class MyPlugin : IPlugin
{
public:
int getNbOutputs() const;
Dims getOutputDimensions(int index, const Dims* inputs,
int nbInputDims);
void configure(const Dims* inputDims, int nbInputs,
const Dims* outputDims, int nbOutputs,
int maxBatchSize);
int initialize();
void terminate();
size_t getWorkspaceSize(int maxBatchSize) const;
int enqueue(int batchSize, const void* inputs,
void** outputs, void* workspace,
cudaStream_t stream);
size_t getSerializationSize();
void serialize(void* buffer);
protected:
virtual ~MyPlugin() {}
};
제시된 코드처럼 사용자는 코드를 통해 사용자 정의 ‘IPlugin’으로 고유한 공유 객체를 구성할 수 있으며, 사용자의 ‘enqueue()’ 함수 내부에 CUDA 커널을 이용한 맞춤형 프로세싱을 적용할 수 있습니다.
텐서RT 2.1은 이 기능을 이용해 객체 감지 강화를 위한 Faster-RCNN 플러그인을 구현할 수 있습니다. 뿐만 아니라, 텐서RT는 LSTM(Long Short Term Memory) 유닛을 위한 새로운 RNN 레이어와 시계열 시퀀스의 메모리 기반 인식 향상을 위한 GRU(Gated Recurrent Unit)을 제공합니다.
이처럼 강력하고 새로운 레이어 유형들을 통해 임베디드 엣지 애플리케이션에서 첨단 딥 러닝 애플리케이션을 배포하는 작업을 가속화할 수 있습니다.

엔비디아 아이작 이니셔티브(NVIDIA Isaac Initiative)
엣지에서의 인공지능 역량이 빠르게 증가하면서, 엔비디아는 로봇공학 및 인공지능 분야에서 최첨단 기술을 선도하기 위한 아이작 이니셔티브를 도입한 바 있는데요. 아이작은 시뮬레이션, 자율 내비게이션 스택, 배포용 임베디드 젯슨 등 인텔리전트 시스템의 개발 및 구축을 위한 엔드-투-엔드 로봇기술 플랫폼입니다.
자율 인공지능 개발을 위해 시작된 아이작은 로보틱스 레퍼런스 플랫폼(Robotic Reference Platform)들을 지원합니다. 이러한 젯슨 기반 플랫폼으로는 드론, 무인육상차량(UGV), 무인선박(USV) 및 인간지원로봇(HSR) 등이 있습니다. 레퍼런스 플랫폼은 실전에서 실험이 가능한 젯슨 기반의 기본 기술을 제공하며, 아이작 프로그램은 앞으로 새로운 플랫폼 및 로봇을 포함하는 방향으로 확대될 예정입니다.

인공지능 배포를 시작하려면
제트팩 3.1에는 cuDNN 6 및 텐서RT 2.1이 구성되어 있습니다. 본 패키지의 젯슨 TX1 및 젯슨 TX2용 모두 엔비디아 공식 개발자 페이지를 통해 이용 가능합니다. 싱글 배치 추론의 저지연 성능이 2배 가량 향상되고, 맞춤형 레이어 등 새로운 네트워크를 지원하는 젯슨 플랫폼은 엣지 컴퓨팅에 가장 최적화되어 있습니다. 엔비디아 개발자 페이지를 통해 인공지능 개발을 시작하는 입문자들은 이미지 인식, 객체 감지 및 세분화 등 딥 러닝 비전 기초요소의 트레이닝 및 배포를 주제로 한 Two Days to a Demo 시리즈를 참고할 수 있습니다. 제트팩 3.1을 이용하면 이와 같은 딥 비전 기초요소의 성능을 상당히 개선시킬 수 있답니다.
관련된 보다 자세한 사항은 엔비디아 온디맨드 웨비나에서 확인해 보세요.