파트너사인 델(Dell), 후지쯔(Fujitsu), 기가바이트(GIGABYTE), 인스퍼(Inspur), 레노버(Lenovo), 네트릭스(Nettrix), 슈퍼마이크로(Supermicro)가 A100 Tensor Core GPU를 통해 MLPerf 벤치마크 테스트에서 업계 최고의 결과를 기록했습니다.
이번 벤치마크 테스트에서 8개의 워크로드를 모두 실행한 기업은 NVIDIA와 NVIDIA의 파트너사 뿐이었으며, 제출한 작업물은 전체 제출물의 4분의 3이상을 차지했습니다. 또한, 작년에 보여준 테스트 점수와 대비해 최대 3.5배 이상 더 뛰어난 성능을 보였죠. NVIDIA는 가장 많은 성능이 필요한 대규모 작업을 위해, 테스트 제출물 중에서 가장 많은 4,096개의 GPU을 사용해 리소스를 모았습니다.
MLPerf가 중요한 이유
2018년 5월에 설립된 MLPerf 훈련 테스트에 NVIDIA는 네 번째로 참여했으며, 가장 강력한 성능을 기록했는데요. MLPerf는 사용자가 테스트 결과를 토대로 구매를 결정하도록 도와줍니다. 벤치마크는 컴퓨터 비전, 자연어 처리, 추천 시스템, 강화 학습과 같이, 현재 가장 인기있는 AI 워크로드와 시나리오를 측정합니다. 또한, 알리바바(Alibaba), 암(Arm), 바이두(Baidu), 구글(Google), 인텔(Intel), NVIDIA 등의 수십 개의 선도업계가 지원하여, 투명하고 객관적인 테스트를 제공합니다.
이는 사용자들이 가장 궁금해하는 새로운 AI 모델 훈련 시간에 중점을 둡니다. AI 모델 사용자는 보통 다양한 AI 모델을 신속하게 생산에 도입하는데요. 시장 출시 기간을 단축하고 데이터 사이언스 팀의 업무 효율성을 극대화할 수 있는 유연하면서도 강력한 시스템이 필요하죠.
뛰어난 AI 성능
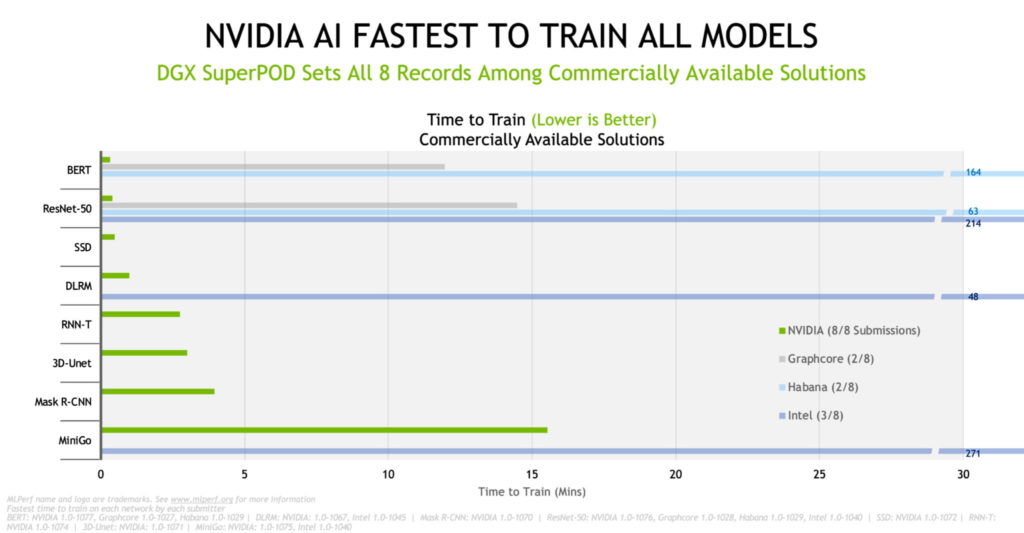
NVIDIA는 슈퍼컴퓨터 세계 상위 500대 중에서 가장 빠른 상용 AI 슈퍼컴퓨터인 셀린(Selene)에서 테스트를 실행했습니다. 셀린은 상위 500대에 있는 다른 12 개의 시스템에서 탑재된 DGX SuperPOD 아키텍처를 기반으로 합니다. 셀린은 상용 시스템의 8개 벤치마크 모두에서 기록을 세웠습니다.
대규모 클러스터로 확장할 수 있는 능력은 가장 어려운 AI 과제이자, NVIDIA의 핵심 강점 중 하나입니다. 성능이 향상되면 더 빠르게 반복해 데이터 사이언스팀의 생산성을 높이고, AI 기반 제품과 서비스 출시 기간을 단축할 수 있습니다.
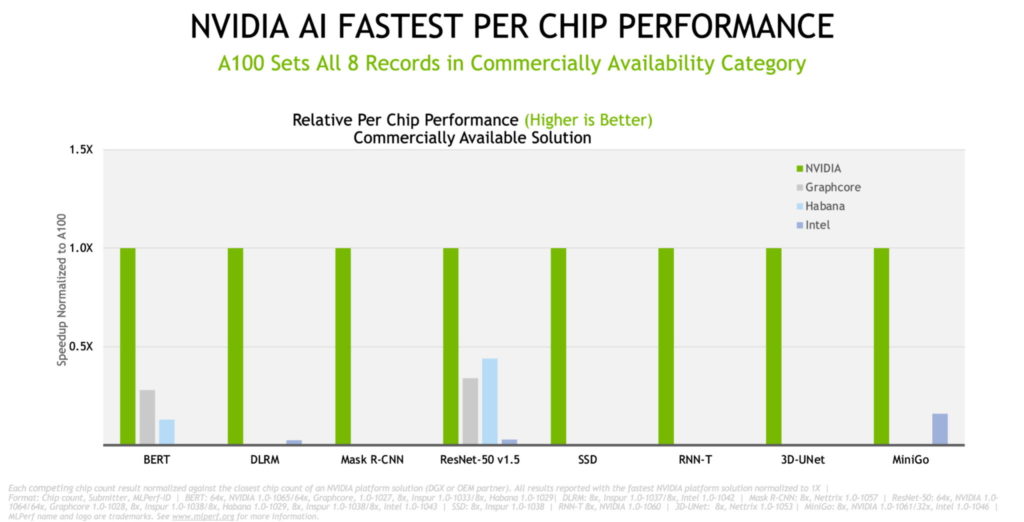
NVIDIA와 파트너사들은 상용 시스템의 칩 성능을 비교하는 최신 테스트에서 8개의 벤치마크에서 기록을 세웠습니다. 2년 반 만에 성능이 최대 6.5배 상승됐으며, 이는 풀 스택 NVIDIA 플랫폼에서 모두 적용됩니다.
최고의 선택을 제공하는 NVIDIA 생태계
MLPerf 결과는 새롭고 혁신적인 시스템을 탑재한 NVIDIA 기반 AI 플랫폼의 성능을 보여줬습니다. NVIDIA AI 플랫폼은 엔트리 레벨 엣지 서버에서 수천 개의 GPU를 탑재한 AI 슈퍼 컴퓨터에 이르기까지 다양합니다.
이번 벤치마크 테스트에 참여한 파트너사 7곳은 온라인 인스턴스, 서버, PCIe 카드 관련 제품이나 계획을 갖고 있는 20여 곳의 클라우드 업체와 OEM에 포함됩니다. 해당 업체들은 40개의 NVIDIA-Certified Systems을 포함해 NVIDIA A100 GPU를 사용 중입니다.
NVIDIA 생태계는 고객에게 대여 가능한 인스턴스부터 온프레미스 서버와 관리형 서버에 이르기까지 다양한 가격대에서 구축 모델을 선택할 수 있도록 지원합니다. 궁극적으로 고객의 인프라 투자 대비 수익은 최적의 활용률을 확보하는데 달렸는데요. 이는 성숙하고 지속적으로 개선되는 소프트웨어에서 다양한 워크로드를 실행할 수 있는 능력에서 비롯되죠. 모든 MLPerf 테스트 결과는 NVIDIA 플랫폼의 다양성을 입증하며, 이는 계속 증가하는 성능으로 모든 유형의 AI 훈련 워크로드를 가속화합니다.
성능이 향상된 비결
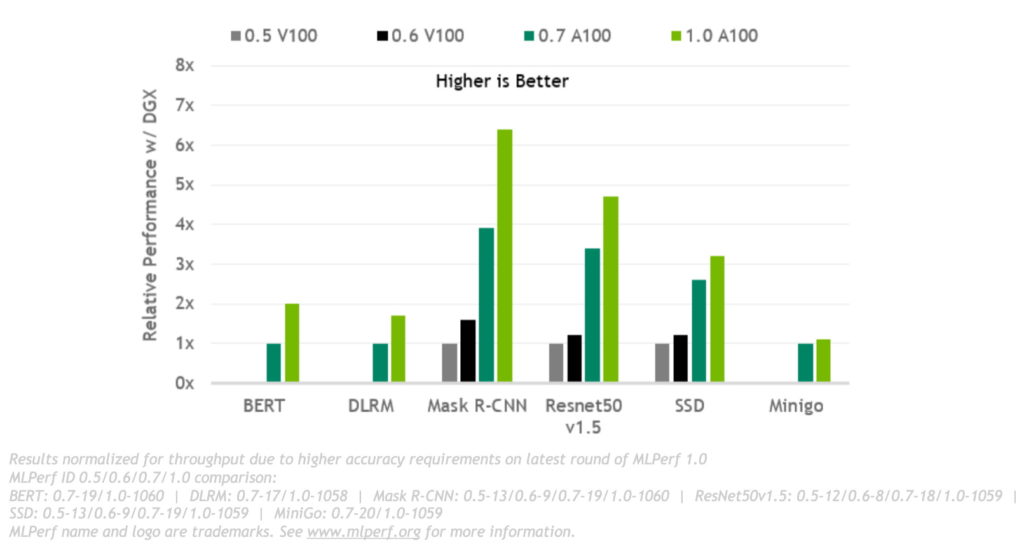
이번 벤치마크는 NVIDIA의 A100 GPU에 대한 두 번째 MLPerf 테스트입니다. GPU, 시스템, 네트워킹, AI 소프트웨어 전반에 걸쳐 성능이 향상됐기에 이와 같은 테스트 결과가 나올 수 있었습니다. NVIDIA 엔지니어들은 NVIDIA CUDA와 소프트웨어 패키지인 CUDA Graphs를 사용해, 전체 신경망 모델을 시작하는 방법을 찾았습니다. 커널(kernel)을 통해 과거의 테스트에서 보여준 CPU 병목 현상을 제거할 수 있었습니다.
또한, 대규모 테스트에서는 네트워크 스위치 내부의 여러 통신작업을 통합하는 소프트웨어인 NVIDIA SHARP를 사용해, 네트워크 트래픽과 CPU 대기 시간을 줄였습니다. CUDA Graphs와 샤프를 함께 사용함으로써, 기록적으로 최대 개수의 GPU에 액세스하면서 데이터센터의 훈련 작업을 할 수 있었습니다. 이런 성능은 AI 모델이 수십억 개의 매개변수를 사용하도록 성장하고 있는 자연어 처리와 같은 많은 영역에서 필요합니다. 성능 향상의 또 다른 비결은 메모리 대역폭이 2TB/s 이상까지 약 30% 증가된 최신 A100 GPU의 확장된 메모리입니다.
MLPerf 벤치마크에 대한 인용문
나노기술에서 기후연구에 이르기까지 다양한 연구를 하는 스웨덴의 샬머스 대학(Chalmers Univ.)의 대변인은 “MLPerf 벤치마크는 여러 AI 플랫폼을 투명하고 세밀하게 비교해, 다양한 실제 사용사례에서 실제 성능을 보여줍니다”라고 밝혔는데요.
벤치마크는 사용자가 세계 최대 규모의 최첨단 공장의 요건을 충족하는 AI 제품을 찾는 데 도움을 줍니다. 예를 들어, 세계 최대의 반도체 파운드리 업체인 TSMC는 머신 러닝을 사용해 광학근접보정(OPC)과 식각(etch) 시뮬레이션을 향상시키고 있습니다.
TSMC의 광학근접보정 부장 단핑 펭(Danping Peng)은 “모델 훈련과 추론에서 머신 러닝의 잠재력을 완전히 실현하기 위해 NVIDIA 엔지니어링 팀과 협력하여 맥스웰(Maxwell) 시뮬레이션과 역 리소그래피(inverse lithography) 기술 엔진을 GPU에 포트(port)하고 매우 빠른 속도 향상을 확인하고 있습니다. MLPerf 벤치마크는 저희가 의사 결정을 내리는 데 중요한 역할을 합니다”라고 말했습니다.
독일의 암 연구 센터 DKFZ의 의료 영상 컴퓨팅 책임자인 클라우스 마이어-하인(Klaus Maier-Hein)은 “우리는 NVIDIA와 긴밀히 협력하여 3DUNet과 같은 혁신기술을 의료 시장에 도입했습니다. 산업 표준 MLPerf 벤치마크는 IT 조직과 개발자들에게 필요한 성능에 관한 데이터를 제공하여, 특정 프로젝트나 애플리케이션을 가속화하는 데 적합한 솔루션을 찾을 수 있도록 돕습니다”라고 말했죠.
NVIDIA가 이번 벤치마크에 제출한 모든 소프트웨어는 MLPerf 저장소에서 이용 가능하여, 누구나 벤치 마크 결과를 재현해 볼 수 있습니다. NVIDIA는 GPU 애플리케이션을 위한 소프트웨어 허브인 NGC에서 이용가능한 딥 러닝 프레임워크와 컨테이너에 이 코드를 지속적으로 추가하고 있습니다. NGC는 최신 MLPerf 벤치마크에서 입증된 풀 스택 AI 플랫폼의 일부로, 현재 실질적인 AI 작업을 지원하는 다양한 파트너사들로부터 관련 제품을 이용할 수 있습니다.