세계적 권위를 자랑하는 MICCAI 2021 의료 이미징 컨퍼런스의 뇌종양 세그멘테이션(segmentation) 챌린지 검증 단계에서 NVIDIA의 연구자들이 10위권 내에 3개 팀이 포함되는 우수한 성적을 거뒀습니다.
10주년을 맞이한 이번 BraTS 챌린지에서 다중 파라미터 자기공명영상(mpMRI) 자료에 나타난 뇌종양의 한 종류인 이종 교모세포종의 하위 영역을 분할해줄 최첨단 AI 모델을 제시하는 것이 과제였는데요. 이는 극도로 까다로운 작업에 해당하죠.
이와 더불어 MGMT 촉진제의 메틸화 상태를 예측하기 위한 분류법이 두 번째 과제로 주어졌습니다.
의료 이미지 컴퓨팅과 CAI 협회(Medical Image Computing and Computer Assisted Interventions society), 북미영상의학회(Radiological Society of North America), 미국신경영상의학회지(American Society of Neuroradiology)가 공동으로 주관하는 이 챌린지에는 2,000개가 넘는 AI 모델들이 제출됐습니다.
NVIDIA 개발자들은 챌린지 검증 단계에서 1위와 2위, 7위에 올랐습니다. 이들 각각은 AI 모델로 종양 세그멘테이션을 진행하는 다채로운 접근법을 선보였는데요. 구체적으로 살펴보면, Optimized U-Net 모델, 자동 하이퍼파라미터 최적화 기능을 갖춘 SegResNet 모델, 컴퓨터 비전을 위한 트랜스포머 기반 접근법인 Swin UNETR 모델입니다.
NVIDIA 수상자들은 모두 오픈 소스의 파이토치(PyTorch) 프레임워크인 모나이(Medical Open Network for AI, MONAI)를 활용했는데요. 모나이는 헬스케어 이미징 부문 딥 러닝의 모범 사례를 표준화하고자 학계와 업계의 지도자들이 구축한 커뮤니티 지원 이니셔티브로, 현재 무료로 제공되고 있습니다.
1위를 차지한 뇌종양 세그멘테이션을 위한 Optimized U-Net
BraTS 검증 단계에서 1위를 차지한 Optimized U-Net 모델은 인코더-디코더 방식의 합성곱 네트워크 아키텍처로, 신속하고 정확한 이미지 세그멘테이션을 지원합니다. 이 모델의 통계상 순위 정규화 값은 0.267점입니다.
Optimized U-Net 모델 설계의 출발점은 2020년에 BraTS에서 우승을 차지한 솔루션인 ‘뇌종양 세그멘테이션을 위한 nnU-Net’이었습니다. 이 팀의 목표는 U-Net 아키텍처와 더불어 트레이닝 스케줄까지 최적화하는 것이었죠. 최적의 모델 아키텍처를 찾기 위해 광범위한 제거 연구(ablation study)를 수행했고, 기본 U-Net과 딥 슈퍼비전(deep supervision)이 최상의 결과를 낸다는 사실을 발견했습니다.
이 U-Net 모델은 포어그라운드 복셀(foreground voxel)용 원핫 (one-hot) 인코딩으로 인풋에 추가 채널을 더해 최적화를 촉진하고, 인코더 뎁스 1레벨과 합성곱 채널의 수를 동시에 증가시켰습니다. 더 낮은 디코더 수준에서 아웃풋 헤드 2개를 추가해 그래디언트 플로우(gradient flow)와 예측 정확도를 개선하고, 딥 슈퍼비전으로 트레이닝의 품질과 속도를 높였죠. 모나이는 데이터 정리와 디노이징(denoising) 작업이 진행되는 데이터 전처리 과정과 모델의 추론에 투입됐습니다. 이때 데이터세트의 크기를 인공적으로 확장하는 기법인 데이터 증강(Data augmentation)을 적용하고 NVIDIA Data Loading Library(DALI)로 구동했는데요. DALI는 데이터 증강 작업을 GPU에 오프로드해 CPU 병목현상 문제를 해결합니다.
최신 버전의 파이토치와 cuDNN, CUDA를 갖춘 NVIDIA PyTorch 컨테이너로 U-Net 모델을 최적화하고 트레이닝 속도를 높였습니다. 자동 혼합 정밀도(AMP)로 AI 모델의 메모리 공간을 2배 줄이면서 트레이닝 속도를 개선했죠. 트레이닝은 NVIDIA A100 GPU 8개에서 1,000에포크(epoch)로 진행됐으며, V100 GPU 대비 2배 빠른 속도를 달성했습니다. GPU가 100% 가까이 사용됐다는 사실은 GPU의 효율성 확보를 위한 네트워크 최적화가 이뤄졌음을 보여줍니다. 이 3D U-Net 모델은 MRI와 CT 등 3D 기법 일체에서 사용이 가능합니다. 더 자세한 정보는 GPU 효율적 nnU-Net 구현하기(GPU efficient nnU-Net implementation)를 확인하세요.
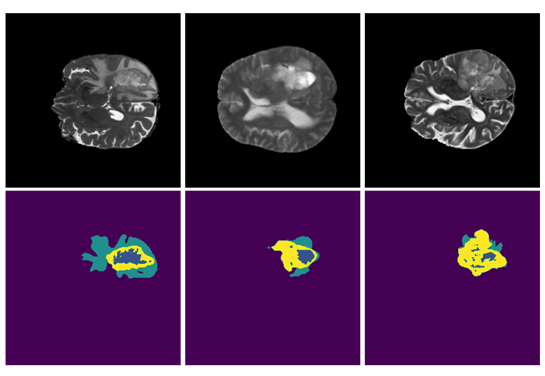
2위를 차지한 SegResNet: 3D 뇌 MRI의 시맨틱 세그멘테이션(Semantic Segmentation)에서 리던던시 감소
BraTS 챌린지에서 2위를 차지했고 모나이에서도 제공될 예정인 이 접근법은 모나이 구성 요소를 기반으로 애플리케이션의 유용성과 유연성을 입증하는 것이 목표입니다. 주요 모델은 모나이의 SegResNet 아키텍처로, U-Net과 유사한 표준 인코더-디코더 기반 합성곱 신경망(CNN)입니다. 이 접근법은 모나이 자동화(AutoML) 이니셔티브의 일환이며, 이때 하이퍼파라미터는 하이퍼파라미터 최적화와 조정을 통해 자동으로 선택됩니다.
이 기법은 검증 단계의 순위표에서 최고 성능을 기록(NVAUTO 팀)했으며, 사례별 랭킹과 섭동 분석(perturbation analysis)에 기반한 합산 순위에서 0.272위를 달성했습니다. 주최측에 따르면, 이 순위는 1위에 오른 솔루션과 통계적으로 유의미한 차이가 없으며, 두 기법은 통계적으로 유사한 것으로 간주됩니다.
이 작업의 경우 성능 강화를 위해 2개 사항을 새롭게 추가했습니다. 첫째, 학습된 피처의 표현형에 특정한 속성이 적용되도록 트레이닝 절차를 수정했습니다. 자기지도(self-supervised) 연구에서 아이디어를 차용해 피처의 차원을 정규화하고 서로 다른 해부학적 영역 사이에서 리던던시(redundancy)를 최소화했습니다. 이와 동시에 해부학적으로 동일한 구조의 영역들은 서로 비슷해지도록 유도했습니다. 이를 통해 네트워크의 작동과 일반화 기능을 강화할 수 있습니다. 둘째, 적응형 앙상블(adaptive ensembling) 기법을 사용해 앙상블에 사용될 모델의 하위 집합을 능동적으로 선별했습니다. 그 결과 모델의 일부 예측에서 잠재적 이상치(outliers)를 피하고 최종 앙상블 성능을 더욱 향상시킬 수 있었습니다.
이 기법은 파이토치를 기반으로 모나이에 구현됐으며, NVIDIA V100 GPU 4개에서 300에포크로 다이스 손실 함수(Dice loss function)를 사용해 16시간 동안 트레이닝을 진행했습니다. 이 팀은 NVIDIA가 제공하는 파이토치 컨테이너와 AMP로 하이퍼파라미터 최적화가 진행되는 도중에 신속한 트레이닝을 달성했죠. 이 기법은 5중 교차 검증으로 트레이닝했고, 각 회당 최고의 성능을 보인 체크포인트는 그대로 유지했습니다. 전체적으로 25개의 모델 체크포인트가 저장됐지만 적응형 앙상블을 활용해 절반만이 최종 예측에 사용됐죠. 이 접근법은 CNN을 기반으로 하기 때문에 추론이 신속하고, 슬라이딩 윈도우(sliding windows)가 없이도 전체 인풋 이미지에서 원스텝 실행이 가능합니다. 단일 모델의 추론에는 1초도 채 걸리지 않아 높은 처리량과 실시간에 가까운 결과를 얻을 수 있는데요. 이는 임상 환경에서 아주 중요한 지점입니다.
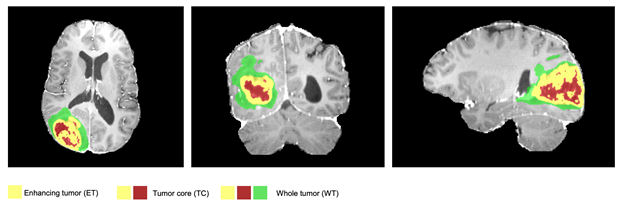
7위를 차지한 Swin UNETR: 뇌종양의 3D 시맨틱 세그멘테이션을 위한 시프티드 윈도우 트랜스포머
BraTS 챌린지에서 7위를 차지한 Swin UNETR는 CNN 대신 트랜스포머를 기반으로 하는 모델입니다. 모나이에 도입된 뒤 종양과 종양 코어, 증강된 종양 세그멘테이션 전반에서 평균 92.94%의 다이스 스코어(Dice score)와 하우스도르프 거리(Hausdorff distance) 1.7을 달성했죠.
트랜스포머는 시퀀스 간 예측 작업에 사용되는 새로운 차원의 딥 러닝 기반 모델입니다. 기본형은 인코더와 디코더로 구성되는데요. 인코더는 다중 헤드의 셀프 어텐션(self-attention) 레이어와 그 뒤를 잇는 다중 레이어 퍼셉트론(perceptron)으로 이루어집니다. 이 모듈의 각각에 들어가는 인풋은 잔여 블록을 통해 아웃풋에 추가되고 정규화됩니다. 셀프 어텐션 레이어는 히든 레이어에서 계산된 값의 가중치 합을 학습하고, 주어진 인풋 시퀀스의 중요한 피처에 강조 표시를 해줄 수 있습니다. 이 레이어는 원래 자연어 처리 분야의 기계 번역 작업용으로 소개되었지만 컴퓨터 비전과 단백질 의약품 생성 등 다른 분야에도 성공적으로 도입됐고, 다양한 벤치마크에서 최신의 성능을 입증했습니다. 컴퓨터 비전의 여러 벤치마크에서도 트랜스포머는 신기록을 세우고 있습니다. Swin UNETR는 발전을 거듭하는 GPU의 아키텍처와 성능을 십분 활용해 모델을 구축하는 새로운 방법입니다.
Swin 트랜스포머는 표현형이 시프티드 윈도우(Swin)로 계산되는 계층형 트랜스포머입니다. 이들은 오브젝트 감지나 이미지 분류, 시맨틱 세그멘테이션 등의 컴퓨터 비전 작업에 적합합니다. Swin 트랜스포머는 오브젝트의 규모나 이미지 내 픽셀의 해상도 등 두 도메인 간의 차이를 보다 효율적으로 모델링할 수 있으며, 시각을 위한 범용 파이프라인의 역할을 하기도 합니다. NVIDIA Swin UNETR 모델은 Swin 트랜스포머 인코더를 통해 인풋 데이터의 3D 패치를 곧장 사용하며, 피처의 추출을 CNN에 의존하지 않습니다. 이에 따라 Swin UNETR가 인풋 데이터의 맥락적 멀티모달 정보에 액세스하고 이들을 토큰화된 임베딩으로 처리한 뒤 트랜스포머 인코더에 넣어 효율을 높입니다. 그런 다음 Swin UNETR의 트랜스포머 기반 인코더가 스킵 연결(skip connection)로 U자형 아키텍처의 CNN 디코더에 연결되어 최종적인 세그멘테이션 예측을 진행합니다.
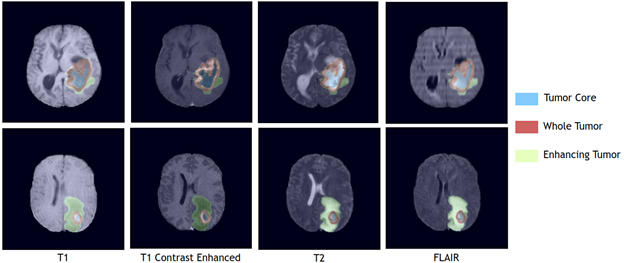
NVIDIA의 Swin UNETR 모델은 GPU 8개가 탑재된 NVIDIA DGX-1 클러스터에서 초기 학습률 0.0008로 AdamW 최적화 알고리즘을 병용해 트레이닝됐습니다. 128*128*128 인풋 데이터의 무작위 패치와 무작위 액시스 미러 플립(axis mirror flip), 강도 조정 등의 데이터 증강 전략이 사용됐죠. 각 트레이닝은 1회 완료에 24시간이 소요됩니다. 흔히 사용되는 CNN 기반 세그멘테이션 모델과 비교해 Swin UNETR는 플롭스(FLOP) 수치 측면에서 더 효율적입니다. 또한 트레이닝 가능한 파라미터의 수 측면에서 볼 때 모델의 복잡성도 적당한 수준이죠. 이 모델은 트레이닝과 추론에 효율적 응용이 가능합니다. 모델 최적화를 위해 포괄적인 소프트 다이스 손실 함수로 학습을 진행하고, 다양한 뇌종양 영역을 각 범주별로 별도 배정해둔 아웃풋 채널에 분할했습니다. 이 모델은 전체 BRATS21 트레이닝 세트에서 5중 교차 검증 체계를 사용해 트레이닝했는데요. 이 경우 최종 세그멘테이션 아웃풋은 2개의 서로 다른 5중 교차 검증에서 10개 모델을 확인한 평균 아웃풋으로 계산됩니다.
BraTS 참가팀들의 전체 순위표는 여기에서 확인하세요.
