
특정 주제에 관한 책 한 권을 읽는다고 전문가가 되는 것은 아닙니다. 또 비슷한 주제에 대한 책을 여러 권 읽는다고 전문가가 되는 것도 아니죠. 한 가지 기술을 완벽히 익히거나 어떤 지식에 정통한 전문가가 되기 위해서는 다양한 출처에서 얻은 많은 정보를 습득해야 합니다.
자율주행과 그 밖의 AI 기반 기술도 마찬가지입니다.
자율주행 기능을 구현하는 딥 뉴럴 네트워크는 혹독한 훈련을 거쳐야 합니다. 일상적인 주행 중에 마주칠 수 있는 상황과 아무도 겪지 않길 바라는 흔치 않은 상황을 모두 학습해야 하죠. 학습을 성공적으로 마치기 위해서는 적절한 데이터를 학습하는 것이 중요합니다.
그렇다면 적절한 데이터란 무엇일까요? 새롭거나 불확실한 상황에 대한 데이터가 바로 적절한 데이터라고 할 수 있습니다. 다시 말해, 똑같은 시나리오를 반복해서 학습하지 않는 것입니다.
능동적 학습이란 이와 같은 다양한 데이터를 자동으로 찾는 머신 러닝을 위한 학습용 데이터 선택 방식을 말합니다. 그래서 사람이 직접 큐레이션(curation)하는데 걸리는 시간 보다 훨씬 짧은 시간 안에 더 좋은 데이터 세트를 구축하는 것입니다.
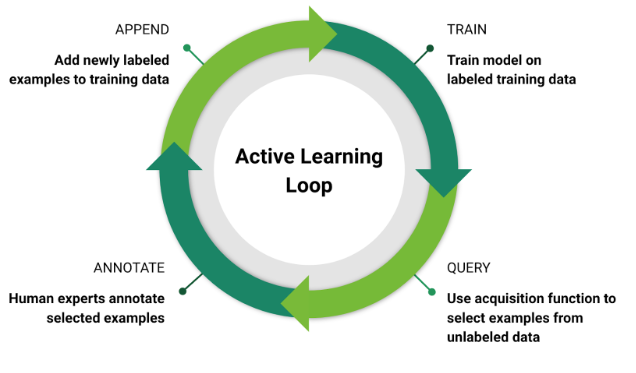
능동적 학습은 이렇게 이뤄집니다. 학습을 완료한 모델을 통해 수집된 정보를 확인한 후, 그 정보 중에서 인지하기 어려운 프레임을 표시하도록 합니다. 그리고 그 프레임들을 학습용 데이터에 추가합니다. 이 과정을 반복하면 좀 더 복잡한 상황에서 모델이 물체를 정확하게 인지하는 능력이 향상됩니다.
데이터의 모래사장에서 바늘 찾기
자율주행 자동차를 훈련하기 위해서는 방대한 데이터가 필요합니다. 미국 국방·안보분야 싱크탱크인 랜드(RAND) 연구소의 전문가들은 자율주행 자동차가 110억 마일(약 177억 km)을 주행해야만 사람보다 20% 나은 성능을 발휘할 수 있다고 합니다. 이는 100대의 차량을 500년간 쉬지 않고 주행해야 하는 거리입니다.
모든 주행데이터가 유효한 것도 아닙니다. 자율주행 자동차의 안전한 주행을 보장하기 위해서는, 학습용 데이터에 다채롭고 어려운 주행조건이 반드시 포함되어야 합니다.
이런 시나리오를 찾기 위해 작업자가 이 검증 데이터에 주석을 직접 달기 위해서는, 100만 명 이상의 라벨링 작업자가 차량의 모든 카메라의 프레임을 관리하면서 100대의 차량이 하루 8시간 주행한 기록을 담은 데이터를 처리해야 합니다. 정말이지 막대한 노력이 필요한 일이죠. 인건비만 드는 게 아닙니다. DNN(딥 뉴럴 네트워크)가 이 데이터를 학습하는데 필요한 컴퓨트와 저장 리소스를 구비하는 것도 불가능한 일입니다.
데이터 주석(data annotation)과 큐레이션을 함께 해야 한다는 것이 자율주행 자동차 개발의 가장 큰 걸림돌이 되고 있습니다. 하지만 이 과정에 AI를 적용하면 학습에 걸리는 시간과 비용은 절감하면서, 네트워크의 정확도는 높일 수 있습니다.
왜 능동적 학습인가
자율주행 DNN 학습 데이터를 선택하는 방법은 대체로 3가지가 있습니다. 랜덤 샘플링(random sampling)은 데이터 풀에서 동일한 간격으로 프레임을 추출해 가장 일반적인 시나리오를 포착합니다. 하지만 드물게 등장하는 패턴은 제외하는 경우가 있습니다.
메타데이터 기반 샘플링(metadata-based sampling)을 이용하면 기본 태그(예: 비, 야간 등)를 사용해 데이터를 선택해 자주 접할 수 있는 어려운 상황을 쉽게 찾을 수 있지만, 트랙터 트레일러나 의족을 착용하고 길을 건너는 사람처럼 쉽게 분류하기 어려운 특수한 프레임은 놓칩니다.

마지막으로, 수동 큐레이션(manual curation)을 이용하면 메타데이터 태그도 사용하고, 동시에 주석 작업자들이 직접 보고 확인하는 작업을 거칩니다. 이 방식은 오류가 발생하기 쉽고, 확장하기 어렵고, 또 많은 시간이 소요되는 작업입니다.
능동적 학습으로 중요한 데이터 지점을 선택할 때 그 선택 프로세스를 자동화할 수 있습니다. 우선, 전용 DNN에 라벨링 작업이 완료된 데이터를 학습시킵니다. 그러면 네트워크가 라벨링 작업이 되지 않은 데이터를 분류해 인식하지 못하는 프레임을 선택합니다. 그 결과로 자율주행 자동차 알고리즘이 인지하기 쉽지 않은 데이터를 찾는 것입니다.
그 다음 주석 작업자가 이 데이터를 검토하고 라벨링 한 뒤에 학습용 데이터 풀에 추가합니다.
능동적 학습은 수동 큐레이션 대비 자율주행 DNN의 감지 정확성을 향상시킬 수 있다는 것을 이미 입증했습니다. 엔비디아 자체 조사 결과, 능동적 학습 데이터를 이용해 학습을 할 경우 수동으로 선택한 데이터 대비 보행자 감지 정확성은 3배, 자전거 감지 정확성은 4.4배 향상된다는 것을 알 수 있었습니다.
능동적 학습과 같은 고급 학습방법, 또 전이 학습(transfer learning)과 연합 학습(federated learning)은 모두 강력하고 확장 가능한 AI 인프라에서 실행될 때 가장 효과적으로 작동합니다. 이 학습방법들을 통해 방대한 양의 데이터를 동시에 관리할 수 있어 개발 주기가 단축됩니다.
엔비디아는 이 학습 도구와 엔비디아 GPU 클라우드 컨테이너 레지스트리(NVIDIA GPU Cloud container registry)의 자율주행 딥 뉴럴 네트워크 라이브러리에 대한 액세스를 개발자들에게 제공할 예정입니다.