
인기 보드게임 중 하나인 ‘젠가’를 해 본적 있나요? 그렇다면 ‘인공지능 희소성(AI sparsity)’이라는 개념을 쉽게 이해할 수 있을 겁니다.
젠가는 나무 블록을 층별로 십자형 방향으로 교차해 기둥 모양으로 높게 쌓아 올린 뒤 게임 참여자가 한 명씩 돌아가며 나무 블록 기둥이 쓰러지지 않도록 블록 한 개씩 조심스럽게 빼내는 게임이죠.
젠가는 시작할 때는 쉬워 보여도 어느 누가 블록 하나를 잘못 빼내 나무 블록 탑이 무너질 때까지 아슬아슬하고 긴장감 있게 진행되는 게임입니다.
수년간 연구자들은 희소성을 이용해 AI를 가속화하는 연구를 하면서 숫자를 이용한 일종의 젠가 게임을 해왔습니다. AI의 오묘한 정확성을 흐트러뜨리지 않으면서 신경망에서 불필요한 변수를 최대한 제거하기 위해 노력해왔죠.
연구자들의 목표는 딥 러닝에 필요한 행렬 곱셈(matrix multiplication)의 양을 최대한 줄여 좋은 결과물을 얻는 시간을 단축하는 것이었습니다. 하지만 아직까지 의미 있는 결과를 도출한 사람은 없었는데요.
현재까지 연구자들은 다양한 기술을 시도해 신경망의 가중치(weight)를 최대 95%까지 줄이려고 노력했습니다. 하지만 정제된 모델의 정확성을 다시 높이기 위해 이미 절약한 시간보다 더 많은 시간을 들여 과감한 조치를 취해야 했습니다. 게다가 한 모델에 효과적이었던 조치가 다른 모델에는 효과적이지 않은 경우도 있었죠.
그런데 이것도 이제는 과거의 얘기가 됐습니다.
숫자에 기반한 희소성
엔비디아 암페어 아키텍처(NVIDIA Ampere architecture)는 네트워크 가중치(network weights)의 미세한 희소성(fine-grained sparsity)을 활용하는 엔비디아 A100 GPU에 3세대 텐서 코어(Tensor Core)를 도입했습니다. 3세대 텐서 코어는 딥 러닝의 핵심인 행렬 곱셈 누적연산(matrix multiply-accumulate jobs)의 정확도를 떨어뜨리지 않으면서 밀도 연산(dense math)의 처리량을 최대 2배 가속화합니다.
테스트 결과 이렇게 희소성을 활용할 경우 이미지 분류, 객체 감지, 번역 등 다양한 AI 작업을 할 때 밀도 연산의 정확성을 유지할 수 있는 것으로 나타났습니다. 이 접근법은 다양한 합성곱 및 순환 신경망(convolutional and recurrent neural networks)과 어텐션 기반 트랜스포머(attention-based transformers)에서도 테스트된 바 있습니다.
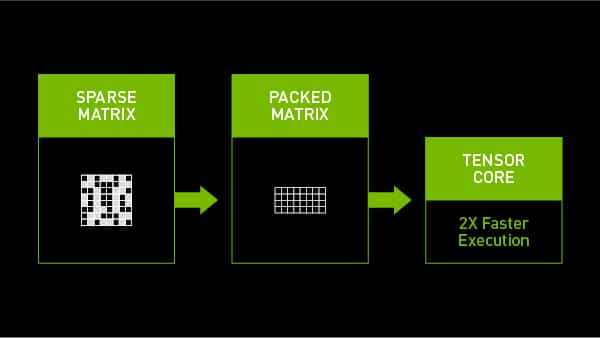
이렇게 가속화된 내부 연산은 애플리케이션 단계에 상당한 영향을 미치는데요. A100 GPU는 희소성을 사용해 정밀 연산 대비 50% 빠른 최첨단 자연어 처리 모델 버트(BERT)를 실행할 수 있습니다.
엔비디아 암페어 아키텍처는 신경망에서 주로 숫자가 작은 값을 볼 수 있다는 점을 최대한 많은 AI 애플리케이션에 도움이 될 수 있는 방향으로 활용하죠. 구체적으로 말해 암페어 아키텍처는 소위 희소성 50%라 말하는 가중치가 50%인 신경망의 학습방법을 정의합니다.
제대로 하면 적을수록 좋다
일부 연구자들은 중요하지 않는 변수를 가진 연결선을 제거하는 프루닝(pruning, 가지치기) 방식을 응용한 거칠고 투박한 (coarse-grained) 프루닝 기술을 사용해 신경망층에서 채널(channel) 전체를 떼어내다가 결국 네트워크 정확성을 떨어뜨리는 경우가 많았습니다. 엔비디아 암페어 아키텍처에는 정확성을 크게 떨어뜨리지 않는 미세한(fine-grained) 프루닝 기술로 구조화된 희소성이 적용됐습니다. 사용자는 자신의 모델을 재훈련하면서 이 점을 확인할 수 있죠.
네트워크가 용도에 맞게 프루닝 작업을 잘 마치고 나면 A100 GPU가 나머지 작업을 자동화합니다.
A100 GPU의 텐서 코어는 희소 행렬을 효율적으로 압축해 적절한 밀도 연산을 구현합니다. 행렬에서 사실상 값이 0인 위치(location)를 생략해 연산량을 단축하고 전력 소비 뿐 아니라 시간도 절약하죠. 희소 행렬을 압축하면 소중한 메모리와 대역폭 사용량도 줄일 수 있습니다.
최신 GPU에서 희소성이 어떤 역할을 하는지 전체적으로 이해하고 싶다면 엔비디아 젠슨 황 CEO의 기조연설을 보세요. 더 자세한 정보를 얻고 싶은 분들은 희소성에 대한 웨비나에 등록하거나 엔비디아 암페어 아키텍처를 상세하게 설명한 블로그(원문)를 읽어보세요.
AI와 HPC 성능을 한 단계 끌어올린 엔비디아 암페어 아키텍처에 새롭게 추가된 다양한 기능 중 하나인 엔비디아이 희소성 지원에 대해 보다 상세히 알고 싶다면 아래 블로그를 확인하세요.
- TF32 블로그: 엔비디아 A100 GPU의 AI 성능이 달라진 이유는
- 배정밀도 텐서 코어 블로그: 엔비디아 HPC의 획기적 변신의 정체는?
- 멀티 인스턴스 GPU 블로그: AI 생산성 극대화 돕는 멀티 인스턴스 GPU 지원 엔비디아 ‘암페어’
- 엔비디아 홈페이지: 엔비디아 A100 텐서 코어 GPU