
손동작 인식 AI 애플리케이션
이번 예제에서는 사전 훈련된 탐지 모델을 선택한 다음 TLT 3.0을 써서 손 탐지 모델로 용도를 변경하고, 동작을 인식할 목적으로 만들어진 모델과 함께 사용하는 방법을 살펴보겠습니다. 훈련이 완료된 모델은 NVIDIA Jetson에 배포합니다.
환경 설정
- Ubuntu 18.04 LTS
- python >=3.6.9 < 3.8.x
- docker-ce >= 19.03.5
- docker-API 1.40
- nvidia-container-toolkit >= 1.3.0-1
- nvidia-container-runtime >= 3.4.0-1
- nvidia-docker2 >= 2.5.0-1
- nvidia-driver >= 455.xx
NGC 계정과 API Key도 필요하며, 무료 사용이 가능합니다. 등록을 마치면 setup page를 열어 추가 지침을 확인하십시오. 하드웨어 요건은 Requirements and Installation을 참고하세요.
virtualenv 와 virtualenvwrapper를 사용하여 파이썬 환경을 설정하세요.
pip3 install virtualenv pip3 install virtualenvwrapper
shell의 설정 파일(.bashrc, .profile 등)에 다음의 줄을 추가하여 가상 환경이 만들어질 위치, 개발 프로젝트 디렉터리의 위치, 이 패키지와 함께 설치된 스크립트의 위치를 설정합니다.
export WORKON_HOME=$HOME/.virtualenvs export PROJECT_HOME=$HOME/Devel export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3 export VIRTUALENVWRAPPER_VIRTUALENV=/home/USER_NAME/.local/bin/virtualenv source ~/.local/bin/virtualenvwrapper.sh
가상 환경을 생성하세요.
mkvirtualenv tlt_gesture_demo
가상 환경을 활성화하세요.
workon tlt_gesture_demo
위에서 사용한 virtualenv 이름을 잊어버린 경우, workon을 입력하세요.
더 자세한 내용은 virtualenvwrapper 5.0.1.dev2를 참고하세요.
TLT 3.0 설정
TLT3.0에는 추상화(abstraction)가 구현되어 있습니다. 모든 훈련 작업은 launcher에서 시작됩니다. 적합한 컨테이너를 수동으로 가져오기 할 필요가 없이 tlt-launcher가 대신 담당합니다. 다음의 명령을 사용하면 pip로 tlt-launcher를 설치할 수 있습니다.
pip3 install nvidia-pyindex pip3 install nvidia-tlt
이 데모를 계속 진행하기 위해서는 Jupyter notebook도 설치해야 합니다.
pip install notebook
EgoHands 데이터세트 준비
손 탐지 모델의 훈련에는 인디애나대학교 IU Computer Vision Lab이 제공하는 공공 데이터세트인 EgoHands를 사용했습니다. EgoHands는 일인칭 기준 시점(egocentric)의 인터랙션이 담긴 48개의 영상을 포함하며 총 4,800 프레임과 15,000개가 넘는 손의 실측 정보가 픽셀 단위로 주석화되어 있습니다. TLT와 함께 사용하려면 이 데이터세트를 KITTI 형식으로 변환해야 합니다. 본 예제에서는 JK Jung의 오픈 소스 스크립트를 적용했습니다.
원본 스크립트를 약간 변화시켜 TLT와 호환이 가능하게 만듭니다. function box_to_line(box) 줄에서 score 부분을 제거하기 위해 return statement를 다음과 같이 바꿔줍니다.
return ' '.join(['hand',
'0',
'0',
'0',
'{} {} {} {}'.format(*box),
'0 0 0',
'0 0 0',
'0'])
데이터세트의 변환을 위해 prepare_egohands.py 파일을 다운로드하고 위에서 언급한 수정 내용을 적용한 다음 올바른 경로를 설정하고, 이 프로젝트의 egohands_dataset/kitti_conversion.ipynb에 있는 지침을 따르세요. 이 notebook은 변환 스크립트의 원본을 불러오기 하고 TLT의 요건에 맞춰 여러분의 데이터세트를 training과 testing 세트로 변환합니다.
탐지 모델의 훈련
TLT 3.0에는 다양한 모델의 훈련 워크플로우를 보여주는 Jupyter notebook들이 포함되어 있습니다. 이번 데모의 notebook은 GitHub 저장소에 있는 gesture_recognition_tlt_deepstream의 training_tlt 디렉터리에서 찾을 수 있습니다.
가상 환경을 활성화한 후 해당 디렉터리로 이동하여 notebook을 시작합니다. 다음으로 여러분의 브라우저에서 training_tlt/handdetect_training.ipynb notebook의 지침을 따르십시오.
cd training_tlt jupyter notebook
PeopleNet으로 초기화된 DetectNet V2에서 TLT 훈련 실행하기
사전에 훈련을 마친 PeopleNet 모델을 NGC catalog에서 선택하여 미세 조정을 시작합니다. PeopleNet 모델은 사람, 가방, 안면의 세 가지 분류에 해당하는 object를 인식하도록 훈련된 DetectNet V2 모델의 하나입니다. 훈련을 마친 후에 이 세 가지 범주를 ‘손(hands)’이라는 단일 범주로 덮어쓰기 합니다. 본 예제에서 모델의 초기화를 PeopleNet으로 진행한 이유는 손이 인간을 이루는 요소의 하나인 만큼 PeopleNet이 이 범주의 표현형을 이미 학습했을 것이기 때문입니다.
DetectNet V2가 이제 각 체크포인트에서의 재시작을 지원합니다. 훈련 작업이 중간에 중단되면 동일한 명령을 재실행하여 가장 가까운 체크포인트에서 훈련을 재개할 수 있습니다. 훈련을 재개할 때는 가장 가까운 체크포인트가 맞는지 확인하세요.
훈련을 마친 후에는 모델이 정확도 측면에서 소기의 성능을 달성할 수 있는지 평가해야 합니다. 이를 위해 TLT는 평가용 툴을 함께 제공하며 해당 notebook에 다음의 명령을 입력하여 실행할 수 있습니다.
!tlt detectnet_v2 evaluate -e $SPECS_DIR/egohands_train_resnet34_kitti.txt\ -m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tlt \ -k $KEY
파라미터는 다음과 같습니다.
- 구성 파일(훈련에 사용된 것과 동일한 파일)
- 훈련을 마친 모델 파일
- 훈련에 사용된 고유 키
모델 프루닝
모델을 미세 조정한 후에는 프루닝(pruning)을 진행하여 추론 측면에서 모델의 크기를 줄일 수 있습니다. 프루닝은 신경망에서 불필요한 연결선을 제거하여 이에 해당하는 계산의 실행 필요성을 없애는 것으로 메모리를 확보하고 모델을 가속화하는 프로세스입니다.
그러나 프루닝은 모델 정확도의 손실을 야기합니다. 대개는 정확도와 모델 크기의 균형을 유지하는 임계를 조정하는 것이 일반적입니다. 임계값이 높으면 모델의 크기는 작아지지만 정확도도 함께 낮아집니다. 사용할 임계값은 데이터세트에 따라 다릅니다. 임의의 임계값을 시작점으로 잡으세요. 재훈련의 정확도가 양호한 경우 이 값을 증가시켜 모델의 크기를 줄일 수 있습니다. 그렇지 않은 경우에는 임계값을 낮춰 정확도를 높이세요. 내부적으로 진행된 일부 연구에 따르면 DetectNet V2 모델의 양호한 출발점이 되어주는 임계값은 0.01입니다.
# Create an output directory if it doesn't exist. !mkdir -p $LOCAL_EXPERIMENT_DIR/experiment_dir_pruned !tlt detectnet_v2 prune \ -m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tlt \ -o $USER_EXPERIMENT_DIR/experiment_dir_pruned/resnet34_nopool_bn_detectnet_v2_pruned.tlt \ -eq union \ -pth 0.0000052 \ -k $KEY
프루닝을 완료한 후에는 정확도를 회복하기 위한 재훈련을 반드시 진행해야 합니다. 재훈련용(retraining) specification을 생성하여 프루닝 완료 모델을 pretrained weights로 사용하도록 합니다.
재훈련을 위해 프루닝 완료 모델의 그래프를 로딩하려면 model_config 파일의 load_graph 옵션을 true로 설정하고 해당 그래프를 로딩하세요. 재훈련을 진행한 후에 모델의 mAP가 일부 감소하는 현상이 발생했다면 원래 훈련되었던 모델의 프루닝이 다소 과도했기 때문일 수 있습니다. 프루닝 임계값을 낮춰 프루닝 비율을 줄인 다음 새 모델로 재훈련을 진행합니다.
DetectNet V2는 이제 양자화 인식 훈련(quantization aware training, QAT)을 지원하여 모델을 더욱 강력히 최적화합니다. 이 단계는 대개 프루닝 후 재훈련 과정에서 수행됩니다.
프루닝 완료 후 QAT로 재훈련
DetectNet 모델들은 프루닝 여부와 관계없이 QAT 모델로 변환될 수 있습니다. specification file의 training_config 부분에서 enable_qat 파라미터를 true로 설정하세요.
!tlt detectnet_v2 train -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -r $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat \ -k $KEY \ -n resnet34_detector_pruned_qat \ --gpus $NUM_GPUS
QAT 변환 모델의 평가
이 섹션에서는 QAT가 가능하고 프루닝과 재훈련을 거친 모델을 평가합니다. 이 모델의 mAP는 QAT 없이 프루닝과 재훈련을 진행한 모델의 mAP와 비슷해야 합니다. 그러나 양자화의 결과로 특정 데이터세트에서는 mAP값이 떨어질 수도 있습니다. 새 모델을 평가하려면 해당 notebook에서 다음의 명령을 실행하세요.
!tlt detectnet_v2 evaluate -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -m $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat/weights/resnet34_detector_pruned_qat.tlt \ -k $KEY \ -f tlt
NCG catalog에서 동작 인식 모델 확보하기
본 예제의 애플리케이션에는 NGC의 동작 인식 모델인 GestureNet으로 훈련된 손 탐지 모델을 사용합니다. wget method를 사용하여 NGC catalog에서 GestureNet 모델을 다운로드할 수 있습니다.
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tlt_gesturenet/versions/deployable_v1.0/zip -O tlt_gesturenet_deployable_v1.0.zip
또는 CLI 명령을 활용할 수도 있습니다.
ngc registry model download-version "nvidia/tlt_gesturenet:deployable_v1.0"
이 모델의 재훈련을 진행하지 않고 곧바로 배포를 진행하고 싶다면 deployable_v1.0 버전을 선택하세요.
DeepStream SDK로 NVIDIA Jetson에 배포하기
탐지 네트워크의 미세 조정과 동작 인식 모델의 다운로드가 완료됐습니다. 이제 이 모델을 엣지단(edge device)의 타깃 디바이스인 Jetson에 배포할 차례입니다. 이 섹션에서는 영상 분석 애플리케이션을 위한 다중 플랫폼 기반 확장형 프레임워크인 DeepStream SDK를 사용해 모델을 배포하는 방법을 살펴보겠습니다.
선결 조건(prerequisites)
이 선결 조건들은 Jetson 상의 배포에 한정됩니다. 이 솔루션의 용도를 변경하여 개별 GPU에서 실행하려면 DeepStream Getting Started를 참고하세요.
- CUDA 10.2
- cuDNN 8.0.0
- TensorRT 7.1.0
- JetPack >= 4.4
JetPack 버전과 함께 설치된 DeepStream SDK가 없는 경우 DeepStream Quick Start Guide의 Jetson 설정 지침을 따르세요.
모델의 배포를 위한 준비
DeepStream SDK를 사용하여 모델을 배포하는 방법은 두 가지입니다. 첫째는 TensorRT에 의존하여 모델이 TensorRT 엔진으로 변환되게 만드는 것입니다. 둘째는 Triton Inference Server에 의존하는 방법입니다. Triton Server는 독립형 솔루션으로 사용될 수 있는 서버이지만 DeepStream 애플리케이션에 통합돼 사용될 수도 있습니다. 이러한 설정은 모델의 형식을 TensorRT 형식으로 반드시 변환할 필요 없이 다양하게 수용할 수 있기 때문에 높은 수준의 유연성을 보장합니다. 이번 섹션에서는 두 가지 배포 방법을 모두 소개하기 위해 TensorRT 런타임을 사용한 손 탐지기와 Triton Server를 사용한 동작 인식 모델의 배포를 살펴보겠습니다.
TensorRT 런타임을 사용하여 DeepStream에 모델을 배포하려면 해당 모델을 TensorRT로 전환할 수 있는지 확인해야 합니다. 모델의 레이어와 운영 일체에 TensorRT가 지원되어야 합니다. 지원되는 레이어 및 운영과 관련한 더 자세한 내용은 TensorRT support matrix를 참고하세요.
모델을 TensorRT로 변환하기
엣지단(edge device)의 타깃 디바이스에서 하드웨어와 소프트웨어 가속화의 이점을 누리려면 .etlt 모델을 NVIDIA TensorRT 엔진으로 변환해야 합니다. TensorRT는 고성능의 딥 러닝 추론용 SDK입니다. 딥 러닝 추론 optimizer와 런타임을 포함하고 있어 딥 러닝 추론 애플리케이션들의 latency는 줄이고 처리량은 늘립니다.
여러분의 모델을 TensorRT 엔진으로 변환하는 방법은 두 가지입니다. DeepStream을 사용해 직접 변환하거나 tlt-converter utility를 사용할 수도 있습니다. 지금부터 이 두 가지 방법 모두를 살펴보도록 하겠습니다.
훈련을 마친 탐지 모델은 최초 실행 시에 DeepStream에 의해 자동 변환됩니다. 추후의 실행에서는 해당 DeepStream config에 생성된 엔진으로의 경로를 지정할 수 있습니다. 본 프로젝트와 함께 NVIDIA의 DeepStream config가 제공됩니다.
GestureNet 모델은 상당히 새롭기 때문에 이 데모에 사용된 DeepStream 5.0 버전은 변환을 지원하지 않습니다. 그러나 업데이트된 tlt-converter를 사용하면 변환이 가능합니다. tlt-converter를 다운로드하려면 여러분의 JetPack 버전을 선택하세요.
각종 하드웨어, 소프트웨어와 tlt-converter를 병용하는 방법에 대한 더 자세한 내용은 Transfer Learning Toolkit Get Started를 참고하세요.
Jetson에 설치된 tlt-converter가 있는 경우 다음의 명령을 사용하여 GestureNet 모델을 변환하십시오.
./tlt-converter -k nvidia_tlt \
-t fp16 \
-p input_1,1x3x160x160,1x3x160x160,2x3x160x160 \
-e /EXPORT/PATH/model.plan \
/PATH/TO/YOUR/GESTURENET/model.etlt
현재 GestureNet 모델을 따로 수정하지 않은 채 그대로 사용하고 있으므로 모델의 key는 NGC에 지정된 것과 동일하게(nvidia_tlt) 유지됩니다.
배포가 가능한 모델을 위한 INT8 calibration file이 없기 때문에 모델을 FP16 형식으로 변환하게 됩니다. 여러분의 모델 경로와 export 경로에 올바른 값을 제공했는지 확인하세요.
GestureNet을 Triton Inference Server용으로 구성하기
Triton Inference Server를 사용하여 모델을 배포하려면 모델 저장소를 지정된 형식에 맞춰 준비하십시오. 저장소의 구조는 다음과 같아야 합니다.
└── trtis_model_repo
└── hcgesture_tlt
├── 1
│ └── model.plan
└── config.pbtxt
이 구조에서 model.plan은 tlt-converter로 생성된 .plan 파일이며 config.pbtxt는 다음의 내용을 포함합니다.
name: "hcgesture_tlt"
platform: "tensorrt_plan"
max_batch_size: 1
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: [ 3, 160, 160 ]
}
]
output [
{
name: "activation_18"
data_type: TYPE_FP32
dims: [ 6 ]
}
]
dynamic_batching { }
Triton Server 저장소의 구성에 대한 더 자세한 내용은 Model Repository를 확인하십시오.
deepstream-app의 커스터마이징
샘플 deepstream-app은 구성이 유연합니다. 1차적 탐지기 혹은 분류기로 구성할 수도 있고 더 나아가 탐지기와 분류기 등의 몇 가지 모델을 연속적으로 구성할 수도 있습니다. 이 경우 탐지기는 관심 물체를 잘라내 분류기에 전달하는 역할을 합니다. 이 프로세스가 DeepStream 파이프라인에서 진행되면서 Jetson 디바이스의 하드웨어가 주는 이점 또한 충분히 누릴 수 있게 됩니다.
Figure 5는 이 애플리케이션의 파이프라인을 보여줍니다.
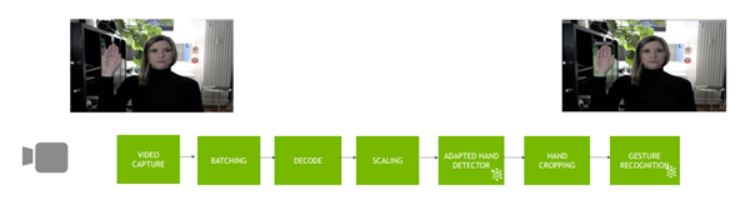
이번 포스팅에서 여러분이 사용하고 있는 GestureNet 모델은 관심 영역(ROI) 주변에 커다란 여백을 둔 이미지들로 훈련을 진행했습니다. 반면 훈련을 마친 탐지 모델은 관심 물체(이 경우에는 손) 주변에 좁은 상자를 표시합니다. 처음에는 이것이 분류기로 전달된 물체와 분류기가 학습한 표현형이 다르다는 문제로 이어집니다. 두 가지 방법으로 이를 해결할 수 있었습니다.
- 해당 설정을 반영한 새로운 데이터세트로 재훈련하기
- 잘라낸 ROI를 확대해 적절한 영역 부여하기
본 예제에서는 GestureNet 모델을 있는 그대로 사용하고자 했기 때문에 두 번째 방법을 선택했습니다. 이를 위해 원본 애플리케이션의 수정이 필요했습니다.
탐지기가 반환한 메타데이터를 수정하여 경계 상자를 더 크게 자르려면 다음의 함수를 실행하세요.
#define CLIP(a,min,max) (MAX(MIN(a, max), min))
int MARGIN = 200;
static void
modify_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
object_meta->rect_params.left = CLIP(object_meta->rect_params.left - MARGIN, 0, frame_width - 1);
object_meta->rect_params.top = CLIP(object_meta->rect_params.top - MARGIN, 0, frame_height - 1);
object_meta->rect_params.width = CLIP(object_meta->rect_params.left + object_meta->rect_params.width + MARGIN, 0, frame_width - 1);
object_meta->rect_params.height = CLIP(object_meta->rect_params.top + object_meta->rect_params.height + MARGIN, 0, frame_height - 1);
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
}
원래의 경계 상자를 표시하려면 다음의 함수를 실행하십시오. 메타 경계 상자를 원래의 크기로 복원해줍니다.
static void
restore_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
// reduce the bounding boxes for output (copy the reserve value from detector_bbox_info)
object_meta->rect_params.left = object_meta->detector_bbox_info.org_bbox_coords.left;
object_meta->rect_params.top = object_meta->detector_bbox_info.org_bbox_coords.top;
object_meta->rect_params.width = object_meta->detector_bbox_info.org_bbox_coords.width;
object_meta->rect_params.height = object_meta->detector_bbox_info.org_bbox_coords.height;
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
또한 다음의 보조 함수를 실행하여 buffer에서 프레임의 width와 height를 가져옵니다.
static void
get_frame_width_and_height (int * frame_width, int * frame_height, GstBuffer * buf) {
GstMapInfo map_info;
memset(&map_info, 0, sizeof(map_info));
if (!gst_buffer_map (buf, &map_info, GST_MAP_READ)){
g_print("Error: Failed to map GST buffer");
} else {
NvBufSurface *surface = NULL;
surface = (NvBufSurface *) map_info.data;
*frame_width = surface->surfaceList[0].width;
*frame_height = surface->surfaceList[0].height;
gst_buffer_unmap(buf, &map_info);
}
}
애플리케이션 구축하기
사용자 지정 애플리케이션을 구축하려면 deployment_deepstream/deepstream-app-bbox를 /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps에 복사하세요.
요구되는 dependency를 설치합니다.
sudo apt-get install libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev \ libgstrtspserver-1.0-dev libx11-dev libjson-glib-dev
실행이 가능하게 만드세요.
cd /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps/deepstream-app-bbox make
DeepStream 파이프라인 구성하기
애플리케이션의 실행에 앞서 configuration file을 제공해야 합니다. configuration 파라미터에 대한 더 자세한 내용은 Application Architecture를 참고하세요. 이 데모의 configuration file은 deployment_deepstream/egohands-deepstream-app-trtis/에서 찾을 수 있습니다. 모델에 필요한 label file도 동일한 디렉터리에 포함돼 있습니다.
마지막으로 애플리케이션이 여러분의 모델을 검색할 수 있도록 만들어야 합니다. configs에 따르면 모델 스토리지를 위한 deployment_deepstream/egohands-deepstream-app-trtis/의 디렉터리 구조는 다음과 같습니다.
├── tlt_models
│ ├── tlt_egohands_qat
│ │ ├── calibration_qat.bin
│ │ └── resnet34_detector_qat.etlt
└── trtis_model_repo
└── hcgesture_tlt
├── 1
│ └── model.plan
└── config.pbtxt
config 의 config_infer_primary_peoplenet_qat.txt에 지정된 resnet34_detector_qat.etlt_b16_gpu0_int8.engine 파일이 현재의 설정에서는 보이지 않을 수 있습니다. 이는 최초 실행 시에 생성되며 추후의 실행에서는 직접 사용됩니다.
애플리케이션 실행하기
일반적인 실행 명령은 다음의 형태를 취합니다.
./deepstream-app-bbox -c <config-file>
제공된 configs에 따르면 이 경우의 실행 명령은 다음의 형태를 취합니다.
./deepstream-app-bbox -c source1_primary_detector_qat.txt
애플리케이션이 실행되는지 확인하세요.
결론
이번 포스팅에서는 NGC catalog가 제공하는 사전 훈련된 모델을 사용하여 미세 조정과 최적화를 진행하고 동작 인식 애플리케이션을 DeepStream SDK로 배포하는 방법을 살펴봤습니다.
본 예제에 사용된 PeopleNet과 GestureNet 모델 외에도 대화형 AI, 음성과 언어 이해 등 다른 use case를 위한 여러 모델들을 NGC catalog에서 만나볼 수 있습니다. 자세한 내용은 다음의 리소스를 참고하세요.
- 본 예제를 위한 샘플 Jupyter notebook
- EgoHands: 손과 관련하여 일인칭 기준 시점의 복잡한 인터랙션을 다루는 데이터세트(A Dataset for Hands in Complex Egocentric Interactions)
- Hand Detection Tutorial prepare_egohands.py script