NVIDIA Megatron과 딥스피드(DeepSpeed) 기반 Megatron-Turing Natural Language Generation(MT-NLG)은 지금껏 트레이닝된 모델 중 가장 크고 강력합니다. 이 단일형 트랜스포머 (transformer) 언어 모델은 파라미터의 수만 5,300억 개에 달하죠. 이는 자연어 생성용 최첨단 AI의 발전을 목표로 NVIDIA와 마이크로소프트가 공동으로 기울인 노력의 산물이기도 합니다.
Turing NLG 17B와 Megatron-LM의 후속 모델인 MT-NLG는 현존하는 가장 대규모의 동일 유형 모델과 비교해도 파라미터의 수가 3배 많습니다. 또한 다음처럼 광범위한 자연어 태스크에서 유례없는 정확도를 보여줍니다.
- 완성형 예측
- 독해
- 상식 추론
- 자연어 추론
- 어휘 중의성 해소
트랜스포머 기반 MT-NLG는 105개의 레이어로 이루어져 있으며 제로샷(zero-shot)과 원샷(one-shot), 퓨샷(few-shot) 설정 측면에서 기존의 최첨단 모델들을 개선해 규모와 품질 모두에서 대규모 언어 모델의 새로운 표준을 제시합니다.
대규모 언어 모델
최근 몇 년 사이 자연어 처리(NLP) 분야에서 트랜스포머 기반 언어 모델은 트레이닝에 활용될 대규모 연산과 데이터세트, 고급 알고리즘과 소프트웨어에 힘입어 급격한 성장을 거듭했습니다.
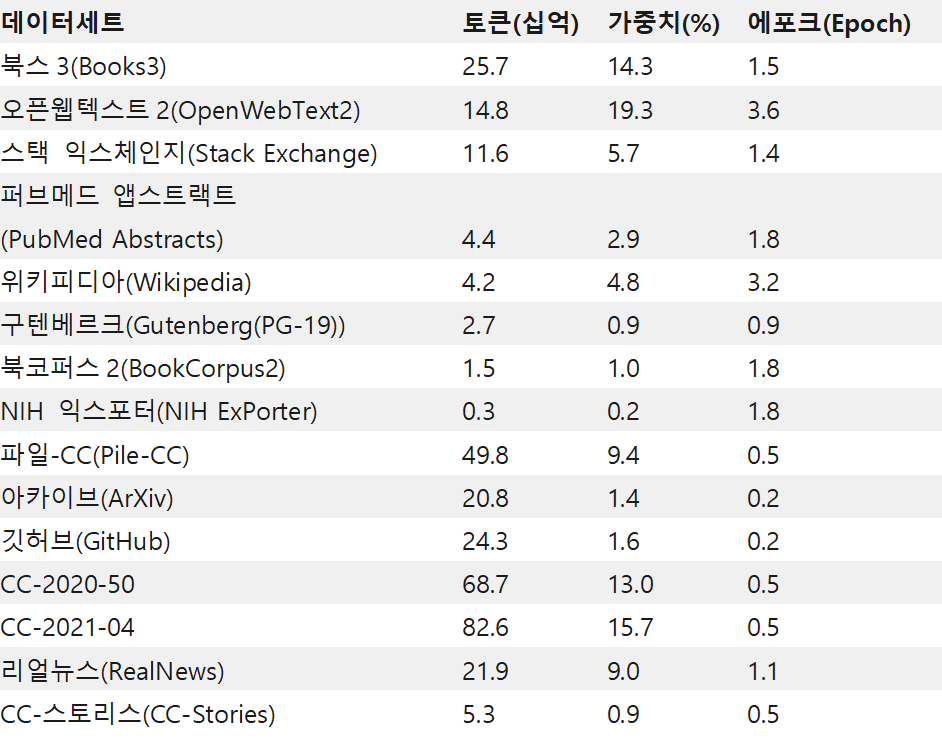
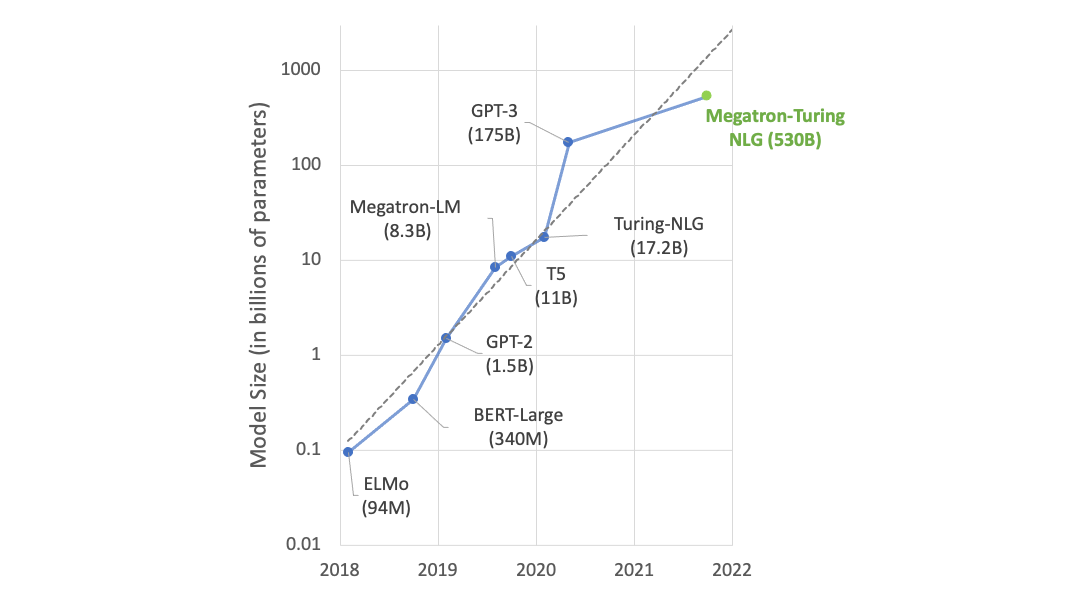
파라미터와 데이터, 트레이닝 시간을 늘린 언어 모델은 언어의 풍부한 함의와 미묘한 뉘앙스까지 이해할 수 있게 됩니다. 이에 따라 효과적인 제로샷 또는 퓨샷 학습자로서 일반화를 훌륭히 수행할 뿐 아니라, 다양한 NLP 태스크와 데이터세트에서 고도의 정확도를 달성하죠. 이를 다운스트림 방식으로 응용하면 요약, 자동 대화 생성, 번역, 시멘틱 검색(semantic search), 코드 자동 완성 등 흥미로운 기능들을 구축할 수 있습니다. 최첨단 NLP 모델의 파라미터가 기하급수적으로 증가한 것도 그리 놀라운 일은 아닌 셈입니다(그림1참조).
그러나 최첨단 모델의 트레이닝에는 다음과 같은 어려움이 따릅니다.
- 현존하는 GPU의 메모리로는 이 모델들의 파라미터를 더 이상 감당할 수 없습니다.
- 대규모의 컴퓨팅 작업이 요구되다 보면 트레이닝에 비정상적으로 긴 시간이 소요될 수 있습니다. 이를 피하려면 알고리즘과 소프트웨어, 하드웨어 스택 일체의 최적화에 각별한 관심을 기울여야 합니다.
MT-NLG의 트레이닝은 AI 전반에서 이룩한 수많은 혁신과 중요한 발견 덕분에 실현이 가능했습니다. 예를 들어 NVIDIA와 마이크로소프트는 긴밀한 협업 하에 최첨단 GPU 가속 트레이닝 인프라와 최신 분산 학습(distributed learning) 소프트웨어 스택을 융합해 전례 없는 트레이닝 효율을 달성했습니다. 또한 수천억 개의 토큰(token)으로 고품질의 자연어 트레이닝 코퍼스(corpus)들을 구축하는 한편, 트레이닝레시피를 공동 개발해 최적화의 효율성과 안정성을 개선했죠.
이번 포스팅에서는 MT-NLG 트레이닝의 면면을 자세히 살펴보면서 관련 기법과 결과를 탐구합니다.
대규모 트레이닝 인프라
NVIDIA A100 Tensor Core GPU와 HDR InfiniBand 네트워킹을 기반으로 하는 NVIDIA Selene, 마이크로소프트 애저(Azure) NDv4 등의 최첨단 슈퍼컴퓨팅 클러스터는 수조 개의 파라미터를 가진 모델을 합리적인 시간 범위 내에 트레이닝하기에 충분한 컴퓨팅 성능을 갖추고 있습니다. 하지만 슈퍼컴퓨터가 이 같은 잠재력을 최대한 발휘하려면, GPU 수천 개에 걸친 병렬화를 통해 메모리와 컴퓨팅 모두에서 효율성과 확장 가능성을 확보해야 하죠.
이때 기존의 데이터/파이프라인 병렬화나 텐서 슬라이싱(tensor-slicing) 등의 병렬화 전략은 따로 떼어 사용할 시 메모리와 컴퓨팅 효율 측면에서 그에 상응하는 손실을 감수해야 하며, MT-NLG 정도의 규모를 가진 모델의 트레이닝에는 활용할 수 없다는 문제가 있습니다.
- 데이터 병렬화는 우수한 컴퓨팅 효율을 달성합니다. 하지만 모델의 상태를 되풀이하고 분산 메모리 집계를 사용할 수 없습니다.
- 텐서 슬라이싱의 경우, GPU 간에 상당한 통신이 요구되므로 단일 노드에 고대역폭 NVLink가 제공되지 않으면 컴퓨팅 효율에 제약이 발생합니다.
- 파이프라인 병렬화는 노드 간 효율적 확장이 가능합니다. 그러나 컴퓨팅 효율을 높이려면 대규모 배치 사이즈(batch size)와 큰 크기의 그레인 병렬화(coarse grain parallelism), 완벽한 로드 밸런싱(load balancing)이 필요한데요. 이는 대규모로는 달성이 불가능합니다.
소프트웨어 디자인
이러한 과제를 해결하기 위해 NVIDIA Megatron-LM과 마이크로소프트 딥스피드(DeepSpeed)가 협업을 진행한 결과, 데이터와 파이프라인, 텐서 슬라이싱 기반 병렬화를 한데 결합할 수 있는 효율적이고 확장 가능한 3D 병렬 시스템이 탄생했습니다.
텐서 슬라이싱과 파이프라인 병렬화를 합치면 이들을 운영하는 체제의 효율성을 극대화할 수 있습니다. 다시 말해 노드 내 모델 확장에는 Megatron-LM의 텐서 슬라이싱을, 노드 간 모델 확장에는 딥스피드의 파이프라인 병렬화를 사용할 수 있게 되죠.
가령 파라미터가 5,300억 개인 MT-NLG 모델의 경우 각 모델의 복제본이 280개의 NVIDIA A100 GPU에 걸쳐 있으며, 노드 내 8방향 텐서 슬라이싱과 노드 간 35방향 파이프라인 병렬화가 실행됩니다. 그런 다음 딥스피드의 데이터 병렬화를 활용해 수천 개의 GPU로 추가 확장이 진행되죠.
하드웨어 시스템
모델의 트레이닝은 NVIDIA DGX SuperPOD 기반 Selene 슈퍼컴퓨터에서 혼합 정밀도(mixed precision)로 실시합니다. 이때 Selene은 완전 팻 트리(fat tree) 구조로 HDR InfiniBand를 통해 연결되는 DGX A100 서버 560대로 구동됩니다. 각 DGX A100에는 8개의 NVIDIA A100 80GB Tensor Core GPU가 탑재되며, 이들은 NVLink와 NVSwitch로 완벽히 연결됩니다. 이와 유사한 참조(reference) 아키텍처를 마이크로소프트 애저 NDv4 클라우드 슈퍼컴퓨터에서도 찾아볼 수 있습니다.
시스템 처리량
우리는 5,300억 파라미터 모델용 시스템의 엔드-투-엔드 처리량을 살펴보기 위해 Selene의 DGX A100 서버 280대, 350대, 420대에서 배치 사이즈 1920을 적용했습니다. 반복 작업(iteration) 시간은 각각 60.1초, 50.2초, 44.4초로 관찰됐는데요. 이는 GPU 당 126과 121, 113 테라플롭스에 해당합니다.
트레이닝용 데이터세트와 모델 구성
우리가 사용한 트랜스포머 디코더의 아키텍처는 5,300억 개의 파라미터로 구성된 레프트-투-라이트(left-to-right) 생성적 트랜스포머 기반 언어 모델입니다. 레이어와 히든 디멘션(hidden dimension), 어텐션 헤드(attention head)의 수는 각각 105개, 20480개, 128개입니다.
이때 8방향 텐서 슬라이싱과 35방향 파이프라인 병렬화를 적용했습니다. 시퀀스 길이는 2048, 전체 배치 사이즈는 1920입니다. 최초 120억 개였던 트레이닝용 토큰의 경우, 32로 시작한 배치 사이즈를 32씩 점진적으로 늘려 최종 사이즈인 1920에 도달했습니다. 트레이닝 중 학습률의 워밍업 차원에서 사용한 토큰은 10억 개입니다.
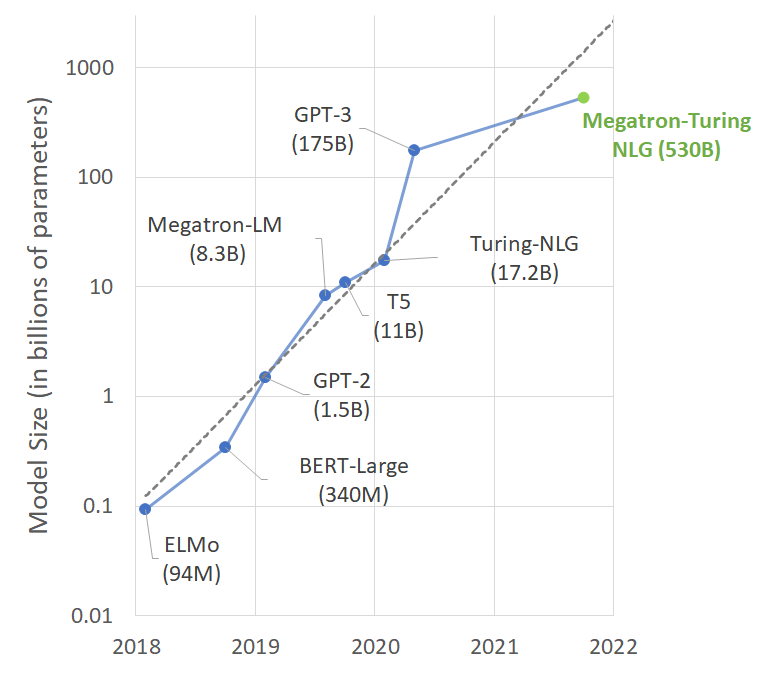
트레이닝용 데이터세트는 이전에 진행한 작업인 ‘더 파일(The Pile)’을 주요 기반으로 구축했습니다. 먼저 상대적 품질이 가장 높다고 판단한 ‘더 파일’에서 데이터세트의 하위 집합(Table 1의 상위 11개 행)을 선택했습니다. 그런 다음 파일-CC(Pile-CC)의 생성에 사용한 것과 유사한 접근법에 의거, 커먼 크롤(Common Crawl, CC)의 최신 스냅샷 2개를 다운로드, 필터링했습니다.
CC 데이터의 경우에는 원시 HTML 파일의 텍스트 추출, 고품질 데이터로 트레이닝을 마친 분류기를 통한 추출 문서 평가, 이때 획득한 점수에 따른 문서 필터링 등의 절차를 진행했습니다. 트레이닝의 다양화를 위해 리얼뉴스(RealNews)와 CC 스토리스(CC-Stories) 데이터세트도 수집했죠.
동일한 콘텐츠가 서로 다른 데이터세트의 여러 문서에 존재할 수 있으므로 트레이닝용 데이터세트를 구축할 때는 문서의 중복 제거(deduplication)가 필수적입니다. 우리는 문서 수준에서 최소 해시(min-hash) LSH를 사용하는 퍼지(fuzzy) 중복 제거 프로세스로 희소 문서 그래프와 그 안의 연결 요소를 계산해 중복 문서를 식별했습니다.
다음으로 데이터세트의 품질에 기반한 우선 순위를 활용해 각각의 연결 요소 내 중복 문서에서 표현형을 선정했습니다. 마지막으로 n-그램(n-gram) 기반 필터링을 통해 트레이닝용 데이터세트에서 다운스트림 태스크 데이터를 제거해 데이터 오염을 방지했습니다.
그 결과 총 3,390억 개의 토큰으로 구성된 데이터세트 15개를 확보하게 되었는데요. 트레이닝을 진행하는 동안 Table 1의 가변적 샘플링 가중치에 따라 데이터세트들을 이질적인 배치로 혼합해 고품질의 데이터세트를 만들기로 결정했습니다. 해당 모델은 2,700억 개의 토큰으로 트레이닝을 진행했습니다.