
실세계의 여러 애플리케이션에서 연합학습(FL, Federated learning)은 이제 하나의 현실로 자리잡고 있습니다. 연합학습 덕분에 세계적 규모의 다국적 협업이 가능해져 더욱 강력하고 일반화 가능한 머신 러닝과 AI 모델을 구축할 수 있게 됐죠. 보다 자세한 내용은 코로나19 환자의 임상 결과 예측을 위한 연합학습(Federated learning for predicting clinical outcomes in patients with COVID-19)을 참고하세요.
NVIDIA FLARE v2.0은 오픈소스 FL SDK입니다. 협업을 진행하는 데이터 사이언티스트들이 개인 소유의 데이터 대신 모델의 가중치(weights)만을 공유해 강력하고 일반화가 가능한 AI 모델을 손쉽게 개발할 수 있도록 지원합니다.
이 같은 기능은 환자나 질병의 유형별로 데이터가 희소한 경우가 있거나 측정 기기의 종류, 성별, 지역에 따라 데이터의 다양성 부족 문제가 발생하는 헬스케어 애플리케이션에서 특히 유용합니다.
NVIDIA FLARE
NVIDIA FLARE는 연합학습 애플리케이션 런타임 환경(Federated Learning Application Runtime Environment)의 약자입니다. NVIDIA Clara Train FL 소프트웨어의 기반 엔진으로 의료 이미징, 유전자 분석, 종양학, 코로나19 연구용 AI 애플리케이션에 사용되죠. 연구와 데이터 사이언스 분야에서 이 SDK를 활용하면, 기존의 머신 러닝과 딥 러닝 워크플로우를 분산 패러다임에 맞춰 조정할 수 있습니다. 플랫폼 개발 시에는 곳곳에 분산되어 있는 여러 기관의 협업을 위해 안전하고 프라이버시가 보장되는 시스템을 구축할 수 있죠.
파이썬(Python)으로 구현된 NVIDIA FLARE는 유연하고 확장 가능한 경량형 분산 학습 프레임워크로 사용자의 기본 트레이닝 라이브러리에 불특정(agnostic) 방식으로 접근합니다. 파이토치(PyTorch)나 텐서플로(TensorFlow), 더 나아가 넘파이(NumPy)로 구현된 사용자 고유의 데이터 사이언스 워크플로우를 가져오기 해 연합학습 환경에 적용하도록 지원합니다.
널리 활용되는 연합 평균화(FedAvg) 알고리즘의 구현을 원하는 사용자도 있을 텐데요. 이때 각 FL 클라이언트는 최초의 글로벌 모델을 시작으로 로컬 데이터에서 일정 시간 동안 모델을 트레이닝하고, 업데이트 사항을 서버로 보내 종합합니다. 서버는 종합한 업데이트로 다시 글로벌 모델을 업데이트한 뒤 다음 회차의 트레이닝을 진행하죠. 이 과정은 모델의 수렴 시까지 여러 번 반복됩니다.
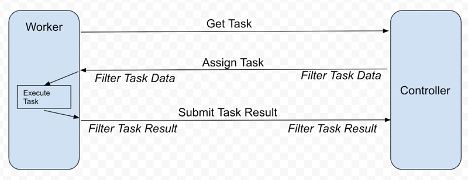
NVIDIA FLARE는 커스터마이징이 가능한 컨트롤러 워크플로우를 통해 FedAvg를 비롯한 다른 FL 알고리즘들, 가령 주기적 가중치 전송(cyclic weight transfer) 등의 구현을 지원합니다. 딥 러닝 트레이닝 같은 다양한 작업이 관련 FL 클라이언트에서 실행되도록 스케줄을 조율하죠. 이 워크플로우를 활용해 각 클라이언트로부터 모델 업데이트 등의 결과를 수집, 종합하고 글로벌 모델을 업데이트한 뒤 이 모델을 되돌려 보내 트레이닝을 계속할 수 있습니다. 그림 1은 이 원리를 보여줍니다.
각 FL 클라이언트는 모델의 트레이닝 등 다음 작업을 실행하도록 요청하는 워커(worker) 역할을 합니다. 컨트롤러가 제공한 작업을 실행하고 결과를 컨트롤러로 반환하죠. 각 통신에는 동형암호화(homomorphic encryption)와 복호화(decryption), 차등 프라이버시처럼 작업 데이터나 결과를 프로세스하는 필터링 옵션이 적용될 수 있습니다.
FedAvg 구현 작업이 CIFAR-10용 분류 모델을 트레이닝하는 간단한 파이토치 프로그램의 형태를 띠는 경우도 있습니다. 이때 로컬 트레이너는 다음의 코드 예제와 유사한 형식일 수 있는데요. 이번 블로그에서는 전체 트레이닝 루프(loop)는 건너뛰고 개략적 내용만 살펴보겠습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable
from nvflare.apis.executor import Executor
from nvflare.apis.fl_constant import ReturnCode
from nvflare.apis.fl_context import FLContext
from nvflare.apis.shareable import Shareable, make_reply
from nvflare.apis.signal import Signal
from nvflare.app_common.app_constant import AppConstants
class SimpleNetwork(nn.Module):
def __init__(self):
super(SimpleNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class SimpleTrainer(Executor):
def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN):
super().__init__()
self._train_task_name = train_task_name
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.model = SimpleNetwork()
self.model.to(self.device)
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.criterion = nn.CrossEntropyLoss()
def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable:
"""
This function is an extended function from the superclass.
As a supervised learning-based trainer, the train function will run
training based on model weights from `shareable`.
After finishing training, a new `Shareable` object will be submitted
to server for aggregation."""
if task_name == self._train_task_name:
epoch_len = 1
# Get current global model weights
dxo = from_shareable(shareable)
# Ensure data kind is weights.
if not dxo.data_kind == DataKind.WEIGHTS:
self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.")
return make_reply(ReturnCode.EXECUTION_EXCEPTION) # creates an empty Shareable with the return code
# Convert weights to tensor and run training
torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()}
self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal)
# compute the differences between torch_weights and the now locally trained model
model_diff = ...
# build the shareable using a Data Exchange Object (DXO)
dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff)
dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len)
self.log_info(fl_ctx, "Local training finished. Returning shareable")
return dxo.to_shareable()
else:
return make_reply(ReturnCode.TASK_UNKNOWN)
def local_train(self, fl_ctx, weights, epoch_len, abort_signal):
# Your training routine should respect the abort_signal.
...
# Your local training loop ...
for e in range(epoch_len):
...
if abort_signal.triggered:
self._abort_execution()
...
def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable:
return make_reply(return_code)사용자가 구현한 내용을 바탕으로 다양한 작업을 수행할 수 있습니다. 각 클라이언트에 대한 요약 통계를 계산해 (프라이버시 제한에 유의하며) 서버와 공유하거나, 로컬 데이터의 전처리를 수행하거나, 트레이닝을 마친 모델을 평가할 수 있죠.
FL 트레이닝 시 각 회차의 도입부에 글로벌 모델의 성능을 표시할 수 있습니다. 이 사례를 살펴보고자 CIFAR-10의 불균질 데이터 스플릿에서 8개의 클라이언트를 활용해 실험했는데요. 그림 2는 NVIDIA FLARE 2.0에서 기본으로 사용이 가능한 여러 구성을 보여줍니다.
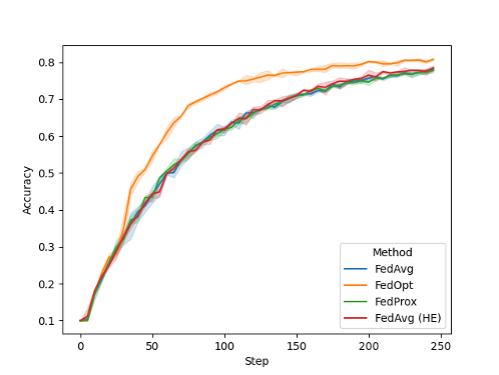
위의 그래프에서 FedAvg와 FedAvg HE, FedProx는 서로 비슷한 성능을 기록했습니다. 반면 SGD를 활용해 서버의 글로벌 모델을 업데이트하는 FedOpt 설정을 사용하면 컨버전스(convergence)를 개선할 수 있죠.
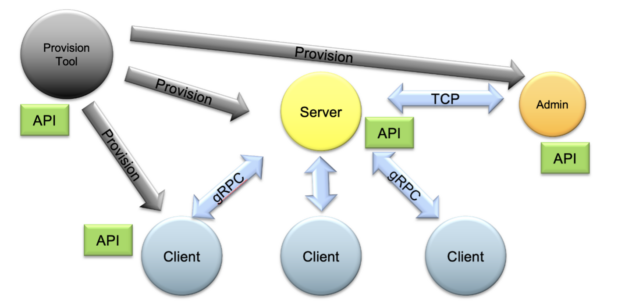
전체 FL 시스템은 관리자 API(admin API)로 제어해 자동으로 시작하고 설정된 작업과 워크플로우에 맞춰 달리 운영할 수 있습니다. NVIDIA는 또한 포괄적 프로비저닝 시스템을 통해 FL 애플리케이션이 실제 환경에서 원활하고 안전하게 배포될 수 있도록 지원하는 한편, 로컬 FL 시뮬레이션 실행을 위한 개념 증명(proof-of-concept) 연구도 함께 제공합니다.
시작하기
NVIDIA FLARE는 연합학습의 응용 범주를 넓혀줍니다. 에너지 기업의 지진과 유정 보어(wellbore) 데이터 분석, 제조업체의 공장 운영 최적화, 금융 회사의 부정 탐지 모델 개선 등의 활용 사례에 적용이 가능할 것으로 기대를 모으고 있습니다.
더 자세한 정보와 단계별 예제는 깃허브(GitHub)의 NVIDIA/NVFlare에서 확인하세요.