음성 AI는 콜센터 업무 지원, 가상 어시스턴트의 음성 인터페이스, 화상 회의 중 실시간 자막 등 다양한 애플리케이션에 활용됩니다. 음성 AI에는 자동 음성 인식(ASR)과 문자 음성 변환(TTS) 프로그램이 포함되는데요. ASR 파이프라인은 원시 오디오를 텍스트로 변환하고, TTS 파이프라인은 텍스트를 오디오로 변환하죠.
이 같은 실시간 음성 AI 서비스의 개발과 운영은 복잡하고 까다롭습니다. 음성 AI 애플리케이션을 구축하려면 수십만 시간 분량의 오디오 데이터, 사용자의 특수한 활용 사례에 맞춰 모델의 구축과 커스터마이징을 진행할 툴, 규모별 배포 기능이 필요합니다. 이때 사용자와의 실시간 인터랙션이 자연스럽게 이뤄지기 위해서는 실행에 걸리는 시간 또한 300 밀리초(ms)를 크게 밑돌아야 하죠. NVIDIA Riva는 음성 AI 서비스 개발의 엔드 투 엔드 프로세스를 간소화하고, 인간과 유사한 인터랙션을 달성하기 위한 실시간 성능을 제공합니다.
Riva SDK
NVIDIA Riva는 음성 AI 애플리케이션 개발을 위한 GPU 가속 SDK입니다. 대화형 AI의 여러 기능에 쉽고 빠르게 액세스하도록 지원하죠. 몇몇 명령어만으로 API를 운영해 고성능 서비스에 액세스하고, 데모를 체험할 수 있습니다.
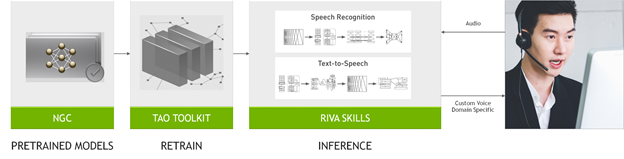
Riva SDK에는 사전 훈련된 음성/언어 모델과 이 모델을 커스텀 데이터세트에서 미세 조정할 NVIDIA TAO Toolkit, 그리고 음성 인식과 언어 이해, 음성 합성에 최적화된 엔드 투 엔드 기능들이 포함돼 있습니다.
Riva를 활용하면 최첨단 모델들을 사용자의 데이터에서 손쉽게 미세 조정해 특수한 맥락의 이해에 깊이를 더할 수 있습니다. 추론의 최적화를 통해 CPU 전용 플랫폼에서 25초가 걸리는 실시간 서비스의 실행 시간을 150 밀리초로 단축하기도 합니다.
작업별 AI 서비스와 gRPC 엔드포인트(endpoint)는 즉시 사용이 가능하고 성능 또한 월등한 자동 음성 인식과 자연어 처리(NLP), 문자 음성 변환 프로그램을 제공합니다. 이러한 AI 서비스들은 수천 시간 분량의 공공/개별 데이터세트로 훈련되어 높은 정확도를 자랑하죠. 사전 훈련 모델로 작업을 시작한 뒤 사용자의 데이터세트로 미세 조정을 진행해 모델의 성능을 더욱 개선할 수도 있습니다.
Riva는 NVIDIA Triton Inference Server 로 다중 모델을 지원해 리소스 할당의 효율성을 강화하는 한편, 처리량과 정확도 개선, 지연시간 단축의 측면에서 우수한 성능을 달성합니다.
Riva 기능 개괄
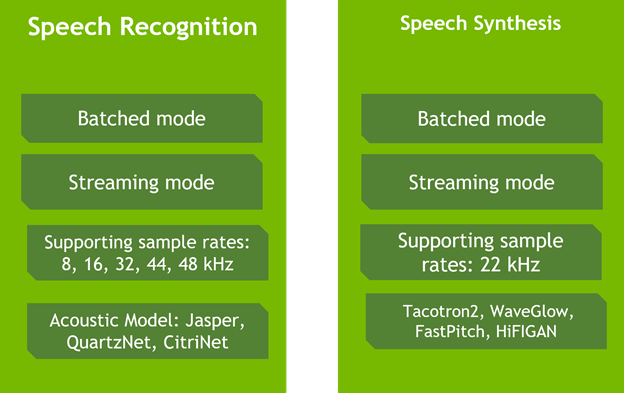
Riva는 실시간 전사(transcription)와 가상 어시스턴트 등의 활용 사례에 필요한 음성 인식과 음성 합성에 고도로 최적화된 서비스를 제공합니다. Riva의 음성 인식 기능은 실세계의 여러 영역별 데이터세트에서 훈련과 평가를 거치는데요. 통신, 팟캐스트(podcast), 헬스케어 분야의 어휘들도 함께 학습해 프로덕션급 활용 사례에서 세계적 수준의 정확도를 제공합니다.
Riva의 문자 음성 변환이나 음성 합성 기능의 경우, 비자기회귀형(non-autoregressive) 모델을 사용해 인간과 유사한 음성을 생성합니다. NVIDIA V100 GPU 기반 Tacotron 2/WaveGlow 모델과 비교할 때, Riva의 비자기회귀형 모델들은 NVIDIA A100 GPU상에서 12배 향상된 성능을 제공하죠. 더 나아가 30분 분량의 성우 목소리 데이터를 바탕으로 단 하루만에 각종 브랜드와 가상 어시스턴트에 활용할 자연스러운 커스텀 음성을 생성할 수 있습니다.
GPU의 컴퓨팅 파워를 최대한 활용하고자 Riva는 NVIDIA Triton Inference Server에 기반을 두고 신경망과 앙상블 파이프라인(ensemble pipeline)이 NVIDIA TensorRT와 함께 효율적으로 실행되도록 지원합니다.
Riva의 서비스들은 gRPC 엔드포인트로 액세스가 가능한 API를 통해 노출되므로 복잡성이 전면에 드러나지 않습니다. 그림 3은 Riva 시스템의 서버 측면을 보여줍니다. gRPC API는 도커(Docker) 컨테이너에서 실행되는 API 서버가 노출합니다. 이들은 송수신되는 음성/NLP 데이터 일체의 처리를 담당하죠.
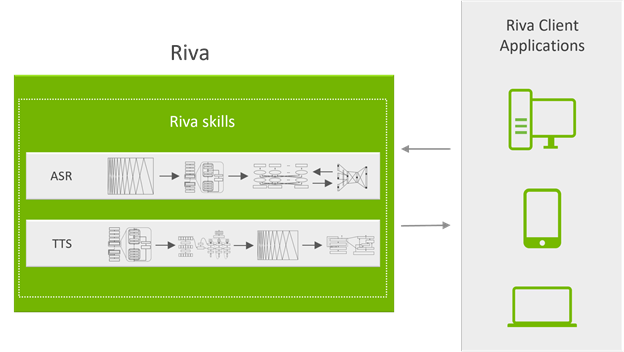
해당 API 서버는 NVIDIA Triton에 추론 요청을 보내고 결과를 수신합니다.
NVIDIA Triton은 다중 GPU에서 여러 신경망과 앙상블 파이프라인을 대상으로 다중의 추론 요청을 동시에 처리하는 백엔드(backend) 서버입니다.
대화형 AI 애플리케이션의 경우, 지연시간을 특정한 임계값 미만으로 유지하는 것이 매우 중요합니다. 이는 추론 요청이 도착하자마자 실행되는 상황을 의미하죠. GPU를 최대한 활용하고 성능을 향상시키려면 배치 사이즈(batch size)를 늘리는 한편, 더 많은 요청이 수신되고 더 큰 배치가 형성될 때까지 추론 실행을 늦춰야만 합니다.
또한 NVIDIA Triton은 추론 요청 간 상태와 네트워크의 맥락 전환을 책임집니다.
Riva는 NGC에서 적합한 모델과 컨테이너를 다운로드하는 간단한 스크립트를 통해 베어메탈(bare-metal)에 직접 설치하거나, 함께 제공되는 헬름 차트(Helm chart)로 쿠버네티스에 배포할 수 있습니다.
지금부터 Riva와 인터랙션하는 방법을 간략히 살펴보겠습니다. 파이썬(Python) 인터페이스는 간단한 파이썬 API 운영을 통해 클라이언트 측면에서 Riva 서버와의 통신을 더 용이하게 해줍니다. 예를 들어 기존 TTS Riva 서비스의 요청을 생성하는 3단계 과정은 다음과 같습니다.
먼저 Riva API를 가져오기 합니다:
import src.riva_proto.riva_tts_pb2 as rtts import src.riva_proto.riva_tts_pb2_grpc as rtts_srv import src.riva_proto.riva_audio_pb2 as ri
다음으로 Riva 엔드포인트에 gRPC 채널을 생성합니다:
channel = grpc.insecure_channel('localhost:50051')
riva_tts = rtts_srv.RivaSpeechSynthesisStub(channel)
이제 TTS 요청을 생성합니다:
req = rtts.SynthesizeSpeechRequest() req.text = "We know what we are, but not what we may be?" req.language_code = "en-US" req.encoding = ri.AudioEncoding.LINEAR_PCM req.sample_rate_hz = 22050 req.voice_name = "ljspeech" resp = riva_tts.Synthesize(req) audio_samples = np.frombuffer(resp.audio, dtype=np.float32)
사용자의 데이터로 모델 커스터마이징하기
NVIDIA TAO Toolkit는 커스텀 모델을 Riva에서 사용할 수 있게 해줍니다(그림 4). 이때 코딩이 없이도 영역별 데이터세트에서 모델을 미세 조정할 수 있죠.
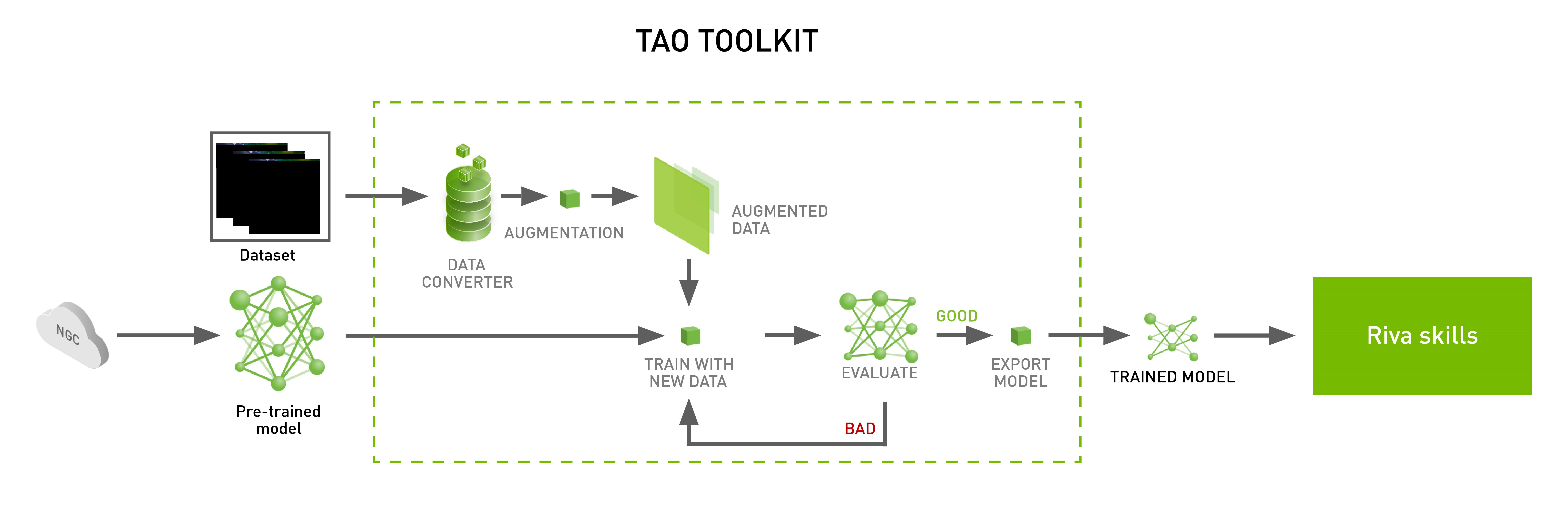
가령 ASR로 전사되는 텍스트의 가독성과 정확성을 개선하고 싶은 경우, 해당 ASR 시스템에 구두법과 대문자화 커스텀 모델을 추가해 관련 피처가 제시되지 않는 상황에서도 텍스트가 제대로 생성되도록 유도할 수 있습니다.
사전 훈련된 BERT 모델을 활용하기 위한 1단계는 데이터세트의 준비입니다. 훈련용 데이터세트의 모든 단어에 있어 목표는 다음 내용의 예측입니다.
- 해당 단어 뒤에 더해져야 할 구두점.
- 해당 단어의 대문자화 여부.
데이터세트가 준비되면 사전에 제공된 스크립트를 실행해 훈련을 진행합니다. 훈련이 완료되고 최종 정확도가 바람직한 수준에 도달하면 함께 포함된 스크립트를 써서 NVIDIA Triton용 모델 저장소를 생성합니다.
NVIDIA Riva Speech Skills 다큐멘테이션에는 다른 모델들의 훈련과 미세 조정 방법이 자세히 소개돼 있습니다. 본 포스팅은 TAO Toolkit를 활용한 커스터마이징의 다양한 가능성 중 한 사례를 소개한 것일 뿐입니다.
Riva에서 모델 배포하기
Riva는 규모별 대화형 AI에 맞춰 설계됩니다. 각 모델이 다양한 서버 전반에서 효율적으로 응용될 수 있도록 헬름 차트를 활용한 버튼식 모델 배포가 함께 지원됩니다(그림 5).
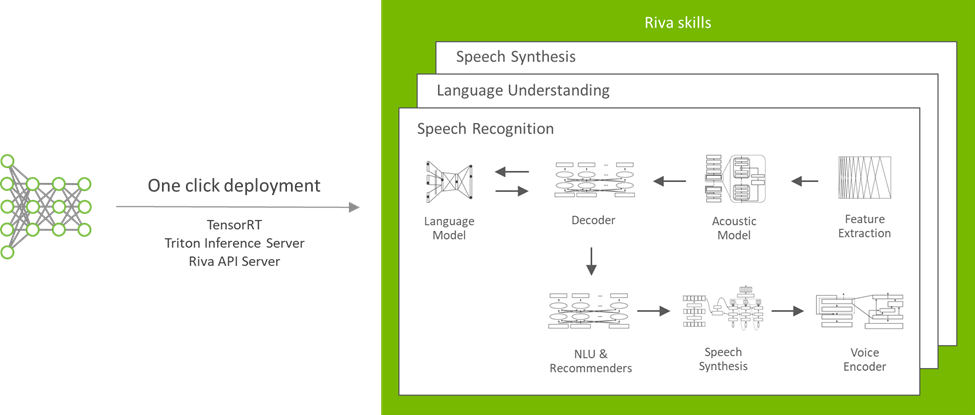
NGC 카탈로그의 헬름 차트 구성은 고유의 활용 사례에 맞춰 수정이 가능합니다. 배포할 모델과 이를 저장할 위치, 서비스의 노출 방식과 관련한 설정들을 변경할 수 있습니다.
결론
Riva는 NVIDIA Developer Program의 참여자들에게 오픈 베타로 제공되어 실시간 전사와 가상 어시스턴트, 커스텀 음성의 구현을 지원합니다. 대규모 배포가 필요한 경우라면 AI 전문가들의 지원이 함께 제공되는 Riva Enterprise를 활용할 수 있습니다.
더 자세한 정보는 Riva Getting Started에서 확인하세요.