
정부 기관 연구실에 있는 고성능 컴퓨터에만 국한되어 있던 가속 컴퓨팅이 이제 주류가 되었습니다.
은행, 자동차 제조업체, 공장, 병원, 소매업체 등이 처리하고 이해해야 하는 데이터의 산더미 같은 문제를 해결하기 위해 AI 슈퍼컴퓨터를 도입하고 있습니다.
이 강력하고 효율적인 시스템은 컴퓨팅의 슈퍼 고속도로라 할 수 있습니다. 슈퍼컴퓨터는 데이터와 연산을 병렬로 처리하여 실행 가능한 결과를 신속하게 도출할 수 있습니다.
GPU와 CPU 프로세서는 이 과정에서 리소스를 제공하며, 온램프(onramps)는 빠른 인터커넥트입니다. 가속화된 컴퓨팅을 위한 인터커넥트의 표준이 바로 NVLink입니다.
NVLink란 무엇인가요?
NVLink는 강력한 소프트웨어 프로토콜에 의해 형성된 GPU와 CPU를 위한 고속 연결로, 일반적으로 컴퓨터 보드에 있는 여러 쌍의 전선을 이용합니다. 이를 통해 프로세서는 공유 메모리 풀에서 초고속으로 데이터를 주고받을 수 있습니다.

이제 4세대에 접어든 NVLink는 호스트와 가속화된 프로세서를 최대 초당 900기가바이트(GB/s)의 속도로 연결합니다.
이는 기존 x86 서버에 사용되는 인터커넥트인 PCIe Gen 5의 7배가 넘는 대역폭입니다. 또한 NVLink는 비트당 1.3피코줄만 소비하는 데이터 전송 덕분에 PCIe Gen 5 대비 5배의 에너지 효율을 자랑합니다.
NVLink의 역사
NVIDIA P100 GPU와의 GPU 인터커넥트로 처음 소개된 NV링크는 새로운 NVIDIA GPU 아키텍처가 등장할 때마다 함께 발전해 왔습니다.

2018년, NVLink는 세계에서 가장 강력한 두 대의 슈퍼컴퓨터인 Summit과 Sierra에서 GPU와 CPU를 연결하여 고성능 컴퓨팅 분야에서 많은 주목을 받았습니다.
오크리지 및 로렌스 리버모어 국립연구소에 설치된 이 시스템은 신약 개발, 자연재해 예측 등의 분야에서 과학적인 한계를 뛰어넘으려 하고 있습니다.
대역폭이 두 배로 증가했다가 다시 증가
2020년, 3세대 NVLink는 GPU당 최대 대역폭을 600GB/s로 두 배로 늘려 모든 NVIDIA A100 Tensor 코어 GPU에 12개의 인터커넥트를 탑재했습니다.
A100은 전 세계 엔터프라이즈 데이터센터, 클라우드 컴퓨팅 서비스 및 HPC 랩에서 AI 슈퍼컴퓨터를 구동하고 있습니다.
현재 18개의 4세대 NVLink 인터커넥트가 단일 NVIDIA H100 Tensor 코어 GPU에 내장되어 있습니다. 그리고 이 기술은 현존하는 가장 강력한 CPU와 가속기를 가능하게 하는 새롭고 전략적인 역할을 맡게 되었습니다.
칩 투 칩 링크(A Chip-to-Chip Link)
NVIDIA NVLink-C2C는 두 개의 프로세서를 단일 패키지 안에 결합하여 슈퍼칩을 만드는 보드 레벨의 인터커넥트 버전입니다. 예를 들어, 두 개의 CPU 칩을 연결하여 클라우드, 엔터프라이즈 및 HPC 사용자에게 에너지 효율적인 성능을 제공하도록 설계된 프로세서인 NVIDIA Grace CPU 슈퍼칩에 144개의 Arm Neoverse V2 코어를 제공합니다.
또한 NVIDIA NVLink-C2C는 그레이스 CPU(Grace CPU)와 호퍼 GPU(Hopper GPU)를 결합하여 그레이스 호퍼(Grace Hopper) 슈퍼칩을 만듭니다. 이 칩은 세계에서 가장 까다로운 HPC 및 AI 작업을 위한 가속 컴퓨팅을 단일 칩에 담았습니다.
스위스 국립 컴퓨팅 센터에서 계획 중인 AI 슈퍼컴퓨터인 알프스가 그레이스 호퍼를 가장 먼저 사용할 예정입니다. 오는 연말, 본격적으로 온라인 상태가 되면 이 고성능 시스템은 천체 물리학에서 양자 화학에 이르는 다양한 분야의 거대 과학 문제를 처리할 것입니다.

그레이스와 그레이스 호퍼는 까다로운 클라우드 컴퓨팅 워크로드에 에너지 효율성을 제공하는 데도 적합합니다.
예를 들어, 그레이스 호퍼는 추천 시스템에 이상적인 프로세서입니다. 이러한 인터넷의 경제 엔진은 매일 수십억 명의 사용자에게 수조 개의 결과를 제공하기 위해 많은 데이터에 빠르고 효율적으로 액세스할 수 있어야 합니다.
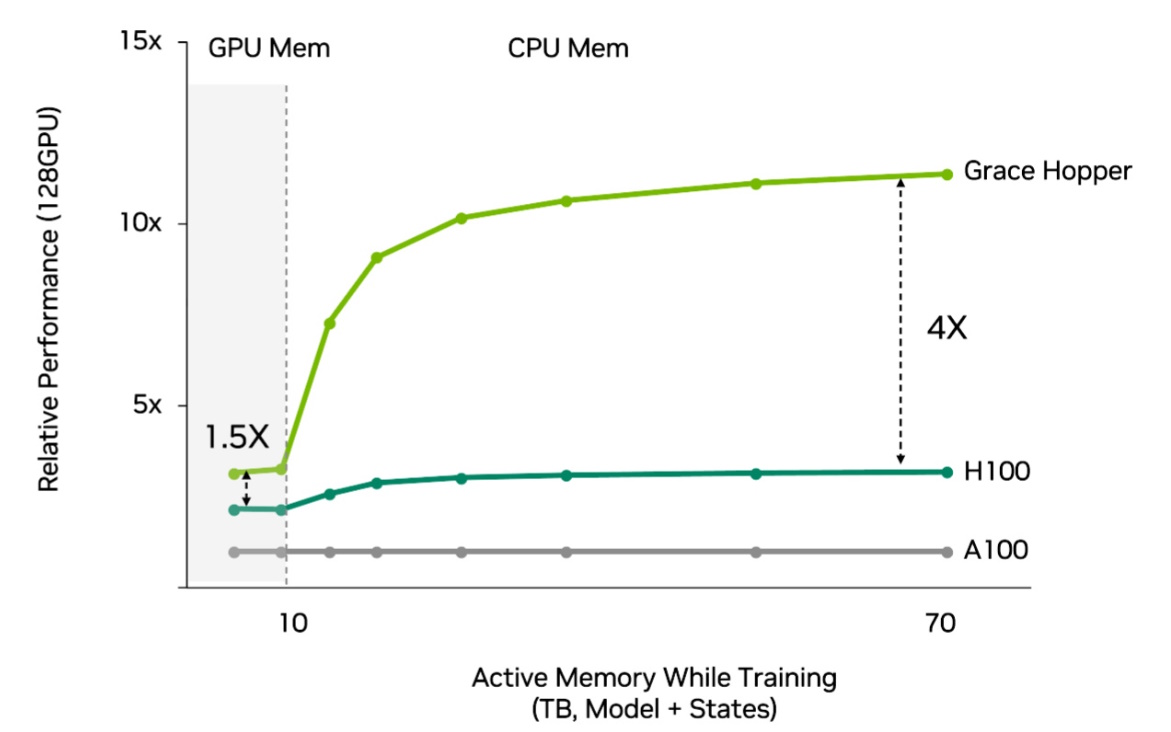
또한 NVLink는 자동차 제조업체를 위한 강력한 시스템 온 칩에 사용되며, 여기에는 엔비디아 호퍼, 그레이스와 에이다 러브레이스(Ada Lovelace) 프로세서가 포함됩니다. 엔비디아 드라이브 토르(NVIDIA DRIVE Thor)는 디지털 계기판, 인포테인먼트, 자율 주행, 주차 등과 같은 지능형 기능을 단일 아키텍처로 통합하는 차량용 컴퓨터입니다.
컴퓨팅의 레고 링크
NV링크는 또한 레고 조각에 찍혀 있는 소켓과 같은 역할을 합니다. 이는 가장 큰 HPC 및 AI 작업을 처리하기 위한 슈퍼시스템 구축에 있어서는 기초 뼈대와 같습니다.
예를 들어, 엔비디아 DGX 시스템의 모든 8개의 GPU에 있는 NVLink는 NVSwitch 칩을 통해 빠른 직접 연결을 공유합니다. 이를 통해 서버의 모든 GPU가 단일 시스템의 일부가 되는 NVLink 네트워크를 구현할 수 있습니다.
더 높은 성능을 얻기 위해 DGX 시스템을 32대의 서버로 구성된 모듈식 유닛으로 스택하여 강력하고 효율적인 컴퓨팅 클러스터를 만들 수 있습니다.

사용자는 32개의 DGX 시스템으로 구성된 모듈식 블록을 하나의 AI 슈퍼컴퓨터에 연결할 수 있으며, DGX 내부의 NV링크 네트워크와 이들 사이의 엔비디아 퀀텀-2(NVIDIA Quantum-2) 스위치 인피니밴드 패브릭을 조합하여 사용할 수 있습니다. 예를 들어, 엔비디아 DGX H100 SuperPOD는 256개의 H100 GPU를 팩킹하여 최대 엑사플롭의 최고 AI 성능을 제공합니다.
더 높은 성능을 얻으려면 Microsoft Azure가 수만 개의 A100과 H100 GPU로 구축 중인 클라우드의 AI 슈퍼컴퓨터를 활용할 수 있습니다. 이 서비스는 OpenAI와 같은 조직에서 세계 최대 규모의 생성형 AI 모델을 훈련하는 데 사용됩니다.
이것이 바로 가속 컴퓨팅의 힘을 보여주는 또 하나의 예입니다.