
MLPerf 벤치마크에서 엔비디아 GH200 그레이스 호퍼 슈퍼칩(NVIDIA GH200 Grace Hopper Superchip)이 우수한 성능을 입증했다는 소식입니다! MLPerf에서 처음으로 선보인 엔비디아 GH200 그레이스 호퍼 슈퍼칩은 모든 데이터센터 추론 테스트를 성공적으로 수행하며 엔비디아 H100 텐서 코어 GPU(H100 Tensor Core GPUs)의 뛰어난 성능을 확장했습니다.
아울러 전반적인 평가 결과에서 클라우드부터 네트워크 엣지까지 엔비디아 AI 플랫폼의 뛰어난 성능과 다용성이 입증되었는데요.
이와는 별도로 엔비디아는 성능, 에너지 효율성, 총소유비용을 획기적으로 개선할 수 있는 추론 소프트웨어를 발표했습니다.
MLPerf에서 활약한 GH200 슈퍼칩
GH200은 하나의 슈퍼칩에 호퍼 GPU와 그레이스 CPU를 연결합니다. 이 조합은 더 많은 메모리와 대역폭을 제공하고, CPU와 GPU 간 자동으로 전력을 전환해 성능을 최적화하는데요,
이와는 별도로, 8개의 H100 GPU를 탑재한 엔비디아 HGX H100 시스템(HGX H100 systems)은 이번 라운드의 모든 MLPerf 추론 테스트에서 가장 높은 처리량을 기록했습니다.
그레이스 호퍼 슈퍼칩과 H100 GPU는 컴퓨터 비전, 음성 인식, 의료 영상 추론은 물론, 추천 시스템과 생성형 AI에 사용되는 대규모 언어 모델(LLMs)의 더욱 복잡한 사용 사례 등 MLPerf의 모든 데이터센터 테스트에서 선두를 차지했습니다.
이번 결과는 2018년 MLPerf 벤치마크가 시작된 이래 모든 라운드에서 AI 훈련과 추론 분야에서 선도적인 성능을 입증해온 엔비디아의 기록을 이어가고 있는데요.
최신 MLPerf 라운드에는 추천 시스템에 대한 업데이트된 테스트와 함께 AI 모델의 대략적인 규모를 측정하는 60억 개의 파라미터로 구성된 대규모 언어 모델 GPT-J의 첫 번째 추론 벤치마크가 포함되었습니다.
추론을 가속화하는 텐서RT-LLM(TensorRT-LLM)
엔비디아는 모든 규모의 복잡한 워크로드를 처리하기 위해 추론을 최적화하는 생성형 AI 소프트웨어 텐서RT-LLM(TensorRT-LLM)을 개발했습니다. 이 오픈 소스 라이브러리는 고객이 이미 구매한 H100 GPU의 추론 성능을 두 배 이상 향상시키는 데 추가 비용 없이 이용 가능하답니다.
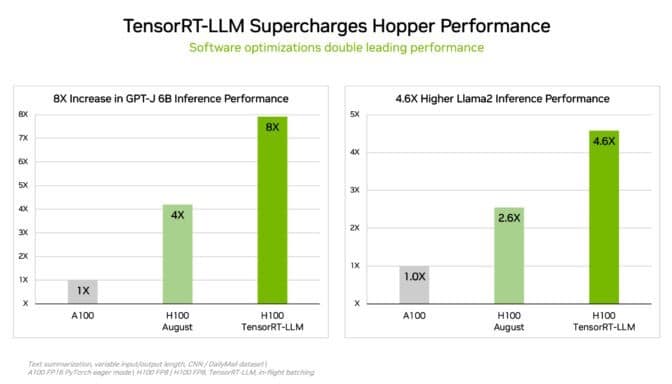
엔비디아의 내부 테스트에 따르면 H100 GPU에서 텐서RT-LLM을 사용하면 GPT-J 6B를 실행하는 이전 세대 GPU에 비해 최대 8배의 성능 속도가 향상되는 것으로 나타났습니다.
이 소프트웨어는 메타(Meta), 애니스케일(AnyScale), 코히어(Cohere), 데시(Deci), 그래머리(Grammarly), 미스트럴 AI(Mistral AI), 모자이크ML(MosaicML), 옥토ML(OctoML), 탭나인(Tabnine), 투게더AI(Together AI) 등 주요 기업들과 함께 대규모 언어 모델 추론의 가속화와 최적화를 위한 엔비디아의 연구에서 출발했는데요,
현재 데이터브릭스(Databricks)에 인수된 모자이크ML은 기존의 서비스 스택에 텐서RT-LLM에 필요한 기능을 추가하고 이를 통합했습니다. 데이터브릭스의 엔지니어링 담당 부사장 나빈 라오(Naveen Rao)는 “텐서RT-LLM은 사용이 간편하고, 다양한 기능을 갖추고 있으며 효율적이다. 이 솔루션은 엔비디아 GPU를 사용해 대규모 언어 모델 서비스를 위한 최첨단 성능을 제공하며, 고객에게 비용 절감 효과를 전달합니다”고 밝혔습니다.
한편 텐서RT-LLM은 엔비디아의 풀스택 AI 플랫폼에서 지속적인 혁신을 보여주는 최신 기술인데요, 이러한 소프트웨어의 발전은 사용자에게 추가 비용 없이 계속해서 향상된 성능을 제공하며, 오늘날의 광범위한 AI 워크로드에서 다용도로 활용할 수도 있습니다.
메인스트림 서버에서 추론을 향상시키는 L4
최신 MLPerf 벤치마크에서 엔비디아 L4 GPU(L4 GPUs)는 모든 워크로드를 실행하며 전반적으로 뛰어난 성능을 선보였습니다.
일례로, 소형 72W 어댑터 카드에서 실행되는 L4 GPU는 약 5배 높은 전력 소비를 요구하는 CPU보다 최대 6배 이상의 성능을 제공하는데요,
또한 엔비디아 테스트에서는 전용 미디어 엔진이 탑재된 L4 GPU가 쿠다(CUDA) 소프트웨어와 결합해 컴퓨터 비전 속도를 최대 120배까지 향상시키는 것으로 확인되었습니다.
L4 GPU는 구글 클라우드(Google Cloud)를 비롯한 많은 시스템 빌더에서 사용할 수 있다. 또한 개인용 인터넷 서비스부터 신약 개발까지 다양한 산업 분야의 고객에게 서비스를 제공하고 있습니다.
엣지에서의 성능 향상
이와 별개로 엔비디아는 새로운 모델 압축 기술을 통해 L4 GPU에서 버트(BERT) 대규모 언어 모델을 실행해 4.7배의 성능 향상을 시연했습니다. 그 결과 새로운 기능을 선보이는 MLPerf의 오픈 디비전 부문에서 우수한 평가를 받았습니다.
이 기술은 모든 AI 워크로드에서 활용될 것으로 예상되는데, 특히 크기와 전력 소비에 제약이 있는 엣지 디바이스에서 모델을 실행할 때 유용하게 사용될 수 있습니다.
엣지 컴퓨팅의 선도적인 입지를 보여주는 또 다른 예로, 엔비디아 젯슨 오린 시스템 온 모듈(Jetson Orin system-on-module)이 있습니다. 이는 엣지 AI와 로봇 시나리오에서 흔히 사용되는 컴퓨터 비전 사용 사례인 물체 감지 분야에서 이전 라운드에 비해 최대 84%의 성능 향상을 선보이기도 했습니다.
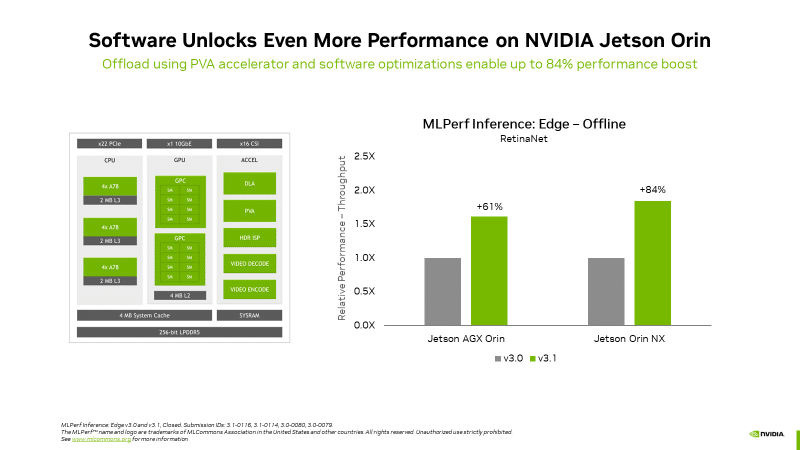
젯슨 오린의 발전에는 프로그래머블 비전 가속기, 엔비디아 암페어 아키텍처 GPU(Ampere architecture GPU), 전용 딥 러닝 가속기 등과 같은 최신 버전의 칩 코어를 이용하는 소프트웨어가 활용되었습니다.
다양한 성능, 광범위한 에코시스템
MLPerf 벤치마크는 공정하고 객관적이기 때문에 사용자는 그 결과를 바탕으로 정보에 입각한 구매 결정을 내릴 수 있습니다. 광범위한 사용 사례와 시나리오를 다루어 사용자는 신뢰 가능하고 유연하게 배포할 수 있는 성능을 확인합니다.
이번 라운드에 참여한 파트너로는 클라우드 서비스 제공업체인 마이크로소프트 애저(Microsoft Azure), 오라클 클라우드 인프라스트럭처(Oracle Cloud Infrastructure), 시스템 제조업체인 에이수스(ASUS), 커넥트 테크(Connect Tech), 델 테크놀로지스(Dell Technologies), 후지쯔(Fujitsu), 기가바이트(GIGABYTE), 휴렛팩커드 엔터프라이즈(Hewlett Packard Enterprise), 레노버(Lenovo), QCT, 슈퍼마이크로(Supermicro) 등이 있습니다.
MLPerf는 알리바바(Alibaba), Arm, 시스코(Cisco), 구글(Google), 하버드 대학교, 인텔(Intel), 메타, 마이크로소프트(Microsoft), 토론토 대학교를 포함한 70개 이상의 조직이 후원하고 있습니다.
여기에서 최근 성과에 대한 자세한 내용을 확인할 수 있습니다.
또한 엔비디아 벤치마크에 사용된 모든 소프트웨어는 MLPerf 레포지토리에서 제공돼 누구나 세계 최고 수준의 결과를 얻을 수 있습니다. 엔비디아는 이러한 최적화를 GPU 애플리케이션을 위한 엔비디아 NGC 소프트웨어 허브에서 사용할 수 있는 컨테이너에 지속적으로 반영하고 있습니다.