
편집자 주: 본 게시물은 RTX PC 사용자를 위한 새로운 하드웨어, 소프트웨어, 도구, 가속화를 보여주는 동시에 기술의 접근성을 높여 AI를 쉽게 이해하도록 돕기 위해 작성된 NVIDIA의 AI Decoded 시리즈의 일부입니다.
생성형 AI가 발전하고 산업 전반에 널리 보급됨에 따라 로컬 PC 및 워크스테이션에서 생성형 AI 애플리케이션을 실행하는 것이 중요해지고 있습니다. 로컬 기반 추론은 소비자의 지연 시간을 줄이고 네트워크 종속성을 제거하며 데이터를 더 잘 제어할 수 있게 합니다.
NVIDIA GeForce 및 NVIDIA RTX GPU는 생성형 AI를 로컬에서 실행할 수 있는 성능을 제공하는 전용 AI 하드웨어 가속기인 Tensor 코어를 제공합니다.
Stable Video Diffusion은 NVIDIA TensorRT 소프트웨어 개발 키트에 최적화되어 있습니다. 이 소프트웨어 개발 키트는 RTX GPU를 장착한 1억 대 이상의 Windows PC 및 워크스테이션에서 최고 성능의 생성형 AI를 구현합니다. 최적화된 Stable Video Diffusion 1.1 이미지-영상 모델은 Hugging Face에서 다운로드할 수 있습니다.
이제 Automatic1111의 인기 있는 Stable Diffusion WebUI용 TensorRT 확장은 ControlNet에 대한 지원을 추가합니다. 이 도구는 사용자가 다른 이미지를 참고용으로 추가하여 생성형 출력을 개선할 수 있는 더 많은 제어권을 제공합니다.
TensorRT 가속화는 새로운 UL Procyon AI 이미지 생성 벤치마크에서 테스트할 수 있으며, 내부 테스트 결과 실제 성능을 정확하게 재현하는 것으로 나타났습니다. 이는 가장 빠른 비 TensorRT 구현에 비해 GeForce RTX 4080 SUPER GPU에서 속도를 50% 향상했으며 가장 유사한 경쟁 제품보다 2배 이상 빠릅니다.
더 효율적이고 정밀한 AI
개발자는 TensorRT를 통해 완전히 최적화된 AI 경험을 제공하는 하드웨어에 액세스할 수 있습니다. AI 성능이 다른 프레임워크에서 애플리케이션을 실행하는 것에 비해 일반적으로 두 배 높아집니다.
또한 Stable Diffusion 및 SDXL과 같이 가장 인기 있는 생성형 AI 모델을 가속화합니다. Stability AI의 이미지-영상 생성형 AI 모델인 Stable Video Diffusion은 TensorRT를 통해 <몇 배의 속도 향상>을 경험할 수 있습니다.
또한 Stable Diffusion WebUI용 TensorRT 확장은 성능을 최대 2배 향상하여 Stable Diffusion 워크플로우를 크게 간소화합니다.
확장 프로그램의 최신 업데이트를 통해 TensorRT 최적화가 ControlNet으로 확장됩니다. ControlNet은 조건을 추가하여 확산 모델의 출력을 안내하는 데 도움이 되는 AI 모델 세트입니다. TensorRT를 사용하면 ControlNet이 40% 더 빨라집니다.
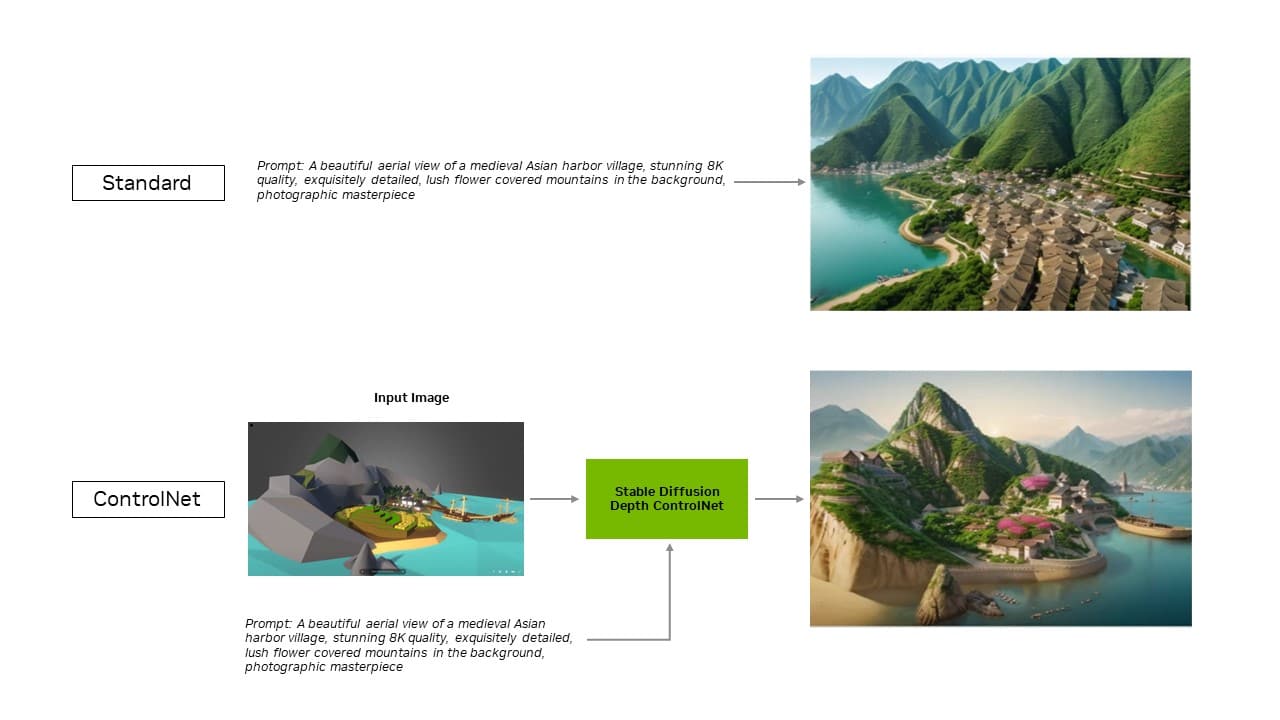
사용자는 입력 이미지와 일치하도록 출력의 여러 측면을 안내할 수 있으므로 최종 이미지를 더 잘 제어할 수 있습니다. 또한 여러 ControlNet을 함께 사용하여 제어를 강화할 수도 있습니다. ControlNet은 특히 깊이 맵, 엣지 맵, 일반 맵 또는 키포인트 감지 모델 등이 될 수 있습니다.
지금 GitHub 에서 Stable Diffusion WebUI용 TensorRT 확장을 다운로드하세요.
TensorRT로 가속화되는 인기 있는 앱
Blackmagic Design은 DaVinci Resolve의 업데이트 18.6에서 NVIDIA TensorRT 가속화를 적용했습니다. Magic Mask, Speed Warp 및 Super Scale과 같은 AI 도구는 Mac에 비해 RTX GPU에서 50% 이상, 최대 2.3배 빠르게 실행됩니다.
또한 TensorRT 통합을 통해 Topaz Labs의 사진 노이즈 제거, 샤프닝, 사진 업스케일링, 영상 슬로우 모션, 영상 업스케일링, 영상 안정화 등과 같은 사진 AI 및 영상 AI 앱의 성능이 최대 60% 향상됐으며, 모두 RTX에서 실행됩니다.
Tensor 코어를 TensorRT 소프트웨어와 결합하여 로컬 PC 및 워크스테이션에 비교할 수 없는 생성형 AI 성능을 제공합니다. 또한 로컬에서 실행하면 다음과 같은 몇 가지 이점을 누릴 수 있습니다.
- 성능: 전체 모델이 로컬에서 실행되면 지연 시간이 네트워크 품질의 영향을 받지 않으므로 사용자는 더 짧은 지연 시간을 경험합니다. 이는 게이밍이나 화상 회의와 같은 실시간 사용 사례에 중요할 수 있습니다. NVIDIA RTX는 초당 1,300조의 AI 연산(TOPS) 이상으로 확장되는 가장 빠른 AI 가속기를 제공합니다.
- 비용: 사용자는 대규모 언어 모델 추론을 위해 클라우드 서비스, 클라우드 호스팅 애플리케이션 프로그래밍 인터페이스 또는 인프라 비용을 지불할 필요가 없습니다.
- 상시 액세스: 사용자는 고대역폭 네트워크 연결에 의존하지 않고 어디에서나 LLM 기능에 액세스할 수 있습니다.
- 데이터 개인 정보 보호: 개인 및 독점 데이터는 항상 사용자의 디바이스에 유지됩니다.
LLM에 최적화
TensorRT가 딥 러닝에 제공하는 것을 NVIDIA TensorRT-LLM은 최신 LLM에 제공합니다.
LLM 추론을 가속화하고 최적화하는 오픈 소스 라이브러리인 TensorRT-LLM에는 Phi-2, Llama2, Gemma, Mistral 및 Code Llama를 포함한 인기 커뮤니티 모델에 대한 기본 지원이 포함되어 있습니다. 개발자와 크리에이터부터 엔터프라이즈 직원 및 일반 사용자에 이르기까지 누구나 NVIDIA AI Playground에서 TensorRT-LLM 최적화 모델을 실험할 수 있습니다. 또한 NVIDIA ChatRTX 기술 데모를 통해 사용자는 Windows PC에서 로컬로 실행되는 다양한 모델의 성능을 확인할 수 있습니다. ChatRTX는 RTX GPU의 성능을 최적화하기 위해 TensorRT-LLM을 기반으로 구축되었습니다.
Windows용 TensorRT-LLM은 클라우드와 로컬 RTX 시스템에서 실행 중인 LLM 애플리케이션 사이를 쉽게 전환할 수 있는 새로운 래퍼를 통해 OpenAI의 인기 있는 채팅 API와 호환됩니다.
NVIDIA는 LlamaIndex 및 LangChain 등 인기 애플리케이션 프레임워크에 대한 기본 TensorRT-LLM 커넥터를 개발하기 위해 오픈 소스 커뮤니티와 협력하고 있습니다.
이러한 혁신을 통해 개발자는 TensorRT-LLM을 애플리케이션과 함께 쉽게 사용하고 RTX를 통해 최고의 LLM 성능을 경험할 수 있습니다.
AI Decoded 뉴스레터를 구독하고 매주 새로운 소식을 이메일로 받아보세요.