
NVIDIA는 최근 생성형 AI 추론에 대한 업계 표준 테스트에서 세계에서 가장 빠른 플랫폼임을 입증했습니다.
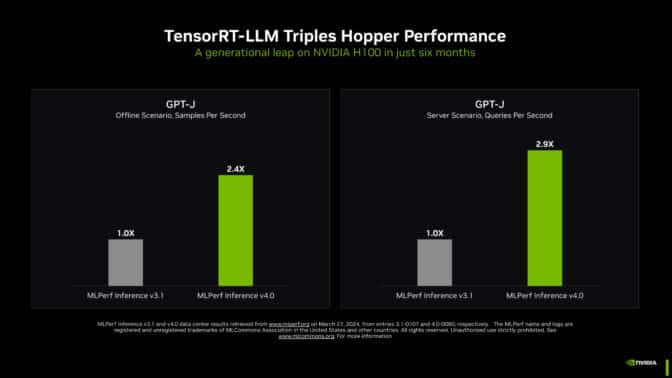
거대 언어 모델에서 복잡한 추론 작업을 가속화하고 간소화하는 소프트웨어인 NVIDIA TensorRT-LLM은 최근에 진행된 MLPerf 벤치마크에서 GPT-J LLM의 NVIDIA Hopper 아키텍처 GPU 성능을 불과 6개월 전보다 3배 가까이 향상시켰습니다.
이러한 극적인 속도 향상은 칩, 시스템 및 소프트웨어로 구성된 NVIDIA의 풀스택 플랫폼이 생성형 AI 구현의 까다로운 요구 사항을 처리할 수 있음을 보여주는 것입니다.
선도적인 기업들은 TensorRT-LLM을 사용하여 모델을 최적화하고 있습니다. 또한 TensorRT-LLM과 같은 추론 엔진을 포함하는 추론 마이크로서비스 세트인 NVIDIA NIM을 통해 기업은 그 어느 때보다 쉽게 NVIDIA의 추론 플랫폼을 구축할 수 있습니다.
생성형 AI의 기준을 높이다
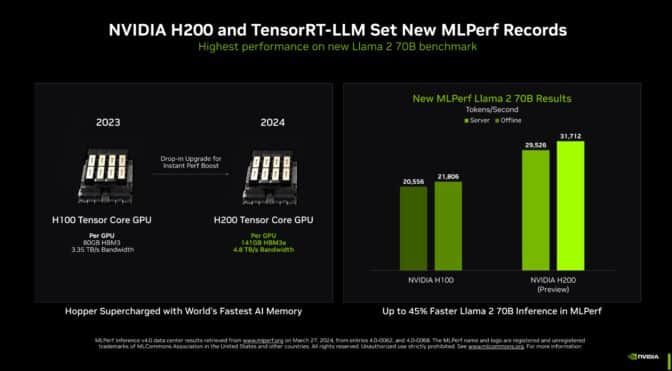
메모리 성능이 강화된 Hopper GPU인 NVIDIA H200 Tensor 코어 GPU에서 실행되는 TensorRT-LLM은 MLPerf의 역대 최대 규모의 생성형 AI 테스트에서 가장 빠른 추론 성능을 기록했습니다.
이 새로운 벤치마크는 700억 개의 매개변수가 포함된 최첨단 거대 언어 모델인 Llama 2의 가장 큰 버전을 사용했는데요, 이 모델은 지난 9월 벤치마크에서 처음 사용된 GPT-J LLM보다 10배 이상 큰 규모입니다.
메모리가 강화된 H200 GPU는 MLPerf 데뷔에서 TensorRT-LLM을 사용해 초당 최대 31,000개의 토큰을 생성했으며, 이는 MLPerf의 Llama 2 벤치마크에서 달성한 기록입니다.
H200 GPU의 결과에는 맞춤형 열 솔루션으로 최대 14%의 이득이 포함되어 있습니다. 이는 표준 공랭식 냉각을 넘어선 혁신의 한 예로, 시스템 빌더들이 Hopper GPU의 성능을 새로운 차원으로 끌어올리기 위해 NVIDIA MGX 디자인을 적용하고 있습니다.
NVIDIA Hopper GPU를 위한 메모리 부스트
NVIDIA는 고객들에게 H200 GPU를 샘플링하여 2분기에 출시할 예정입니다. 약 20개의 주요 시스템 빌더 및 클라우드 서비스 제공업체에서 곧 출시될 예정입니다.
H200 GPU는 4.8TB/s로 실행되는 141GB의 HBM3e를 탑재하고 있습니다. 이는 H100 GPU에 비해 76% 더 많은 메모리가 43% 더 빠르게 작동하는데요, 이 가속기는 동일한 보드 및 시스템에 연결되며 H100 GPU와 동일한 소프트웨어를 사용합니다.
HBM3e 메모리를 사용하면 단일 H200 GPU로 최고의 처리량으로 전체 Llama 2 70B 모델을 실행할 수 있어 추론을 보다 간소화하고 속도를 높일 수 있습니다.
더 많은 메모리를 제공하는 GH200
더 많은 메모리(최대 624GB의 고속 메모리, 144GB의 HBM3e 포함)가 하나의 모듈에 Hopper 아키텍처 GPU와 전력 효율적인 NVIDIA Grace CPU를 결합한 NVIDIA GH200 슈퍼칩에 탑재되어 있습니다. 또한 NVIDIA 가속기는 HBM3e 메모리 기술을 사용한 최초의 제품입니다.
초당 5TB에 가까운 메모리 대역폭을 제공하는 GH200 슈퍼칩은 추천 시스템과 같은 메모리 집약적인 MLPerf 테스트에서 뛰어난 성능을 발휘했습니다.
모든 MLPerf 테스트 스윕
Hopper GPU는 가속기별로 최신 MLPerf 업계 벤치마크에서 모든 AI 추론 테스트들을 휩쓸었습니다.
이 벤치마크는 생성형 AI, 추천 시스템, 자연어 처리, 음성 및 컴퓨터 비전 등 오늘날 가장 인기 있는 주요 AI 워크로드와 시나리오들을 모두 다루고 있습니다. NVIDIA는 2020년 10월 MLPerf의 데이터센터 추론 벤치마크가 시작된 이래 최신 라운드와 모든 라운드에서 모든 워크로드에 대한 결과를 제출한 유일한 회사입니다.
지속적인 성능 향상은 추론 비용 절감으로 이어지며, 이는 전 세계에 배포된 수백만 개의 NVIDIA GPU의 일상 업무에서 점점 더 큰 비중을 차지하고 있습니다.
가능성의 발전
가능성의 한계를 뛰어넘기 위해 NVIDIA는 최첨단 AI 방법을 테스트하기 위해 만들어진 벤치마크의 특별 섹션인 오픈 디비전에서 세 가지 혁신적인 기술을 시연했습니다.
NVIDIA의 엔지니어들은 계산을 줄이는 방법인 구조화된 희소성(Structured sparsity)이라는 기술을 사용했으며, 이는 NVIDIA A100 텐서 코어 GPU에 처음 도입되어 Llama 2에서 추론 속도를 최대 33%까지 향상시켰습니다.
두 번째 오픈 디비전 테스트에서는 추론 처리량을 높이기 위해 AI 모델(이 경우 LLM)을 단순화하는 방법인 프루닝을 사용해 최대 40%의 추론 속도 향상을 확인했습니다.
마지막으로, DeepCache라는 최적화를 통해 Stable Diffusion XL 모델에서 추론에 필요한 수학을 줄여 성능을 무려 74%까지 가속화했습니다.
이 모든 결과는 NVIDIA H100 Tensor GPU에서 실행되었습니다.
사용자가 신뢰할 수 있는 소스
MLPerf의 테스트는 투명하고 객관적이므로 사용자는 그 결과를 바탕으로 정보에 입각한 구매 결정을 내릴 수 있습니다.
NVIDIA의 파트너들은 MLPerf가 AI 시스템 및 서비스를 평가하는 고객에게 유용한 도구라는 것을 알고 있기 때문에 MLPerf에 참여하고 있습니다. 이번 라운드에서 NVIDIA AI 플랫폼에 대한 결과를 제출한 파트너사에는 ASUS, Cisco, Dell Technologies, Fujitsu, GIGABYTE, Google, Hewlett Packard Enterprise, Lenovo, Microsoft Azure, Oracle, QCT, Supermicro, VMware(최근 Broadcom에서 인수), 그리고 Wiwynn이 포함되었습니다.
테스트에 사용된 모든 소프트웨어는 MLPerf 리포지토리에서 확인할 수 있습니다. 이러한 최적화는 GPU 애플리케이션을 위한 NVIDIA의 소프트웨어 허브인 NGC와 NIM 추론 마이크로서비스가 포함된 안전한 지원 플랫폼인 NVIDIA AI Enterprise에서 사용할 수 있는 컨테이너에 지속적으로 접혀 있습니다.
더 넥스트 빅 씽(The Next Big Thing)
생성형 AI의 활용 사례, 모델 크기 및 데이터 세트는 계속 확장되고 있습니다. 그렇기 때문에 MLPerf는 계속해서 진화하고 있으며, Llama 2 70B 및 Stable Diffusion XL과 같은 인기 모델을 통한 실제 테스트를 지속적으로 추가하고 있습니다.
LLM 모델 크기의 폭발적인 증가에 발맞춰 NVIDIA 젠슨 황 CEO는 GTC 2024에서 NVIDIA Blackwell 아키텍처 GPU가 수조 개의 파라미터를 가진 AI 모델에 필요한 새로운 수준의 성능을 제공할 것이라고 발표했습니다.
거대 언어 모델을 위한 추론은 어렵기 때문에 전문 지식이 필요하며, NVIDIA는 Hopper 아키텍처 GPU와 TensorRT-LLM을 통해 MLPerf에서 풀스택 아키텍처를 시연했습니다. 앞으로 더 많은 것들이 업데이트될 예정입니다.
MLPerf 벤치마크와 이 추론 라운드의 기술적 세부 사항에 대해 자세히 알아보세요.