많은 사용자가 개인 정보 보호와 제어력을 위해 구독 없이도 거대 언어 모델(LLM)을 로컬에서 실행하고 싶어하지만, 최근까지 이 방법은 출력 품질의 저하를 감수해야 했습니다. OpenAI의 gpt-oss, Alibaba의 Qwen 3 등 새로 출시된 오픈 웨이트 모델은 PC에서 직접 실행 가능하며, 특히 로컬 Agentic AI를 위한 유용한 고품질 출력을 제공합니다.
이를 통해 학생, 취미 사용자 및 개발자가 생성형 AI 애플리케이션을 로컬에서 탐구할 수 있는 새로운 기회를 열어 줍니다. NVIDIA RTX PC는 이러한 경험을 가속화하여 사용자에게 빠르고 민첩한 AI를 제공합니다.
RTX PC에 최적화된 로컬 LLM 시작 가이드
NVIDIA는 RTX PC용 LLM 애플리케이션을 최적화하여 RTX GPU에서 Tensor 코어의 최대 성능을 끌어내었습니다.
PC에서 AI를 시작하는 가장 쉬운 방법 중 하나는, LLM을 실행하고 상호 작용하기 위한 간단한 인터페이스를 제공하는 오픈 소스 도구인 Ollama를 사용하는 것입니다. PDF를 드래그앤 드롭해 프롬프트로 불러오는 기능, 텍스트와 이미지를 함께 이해하는 멀티 모달 대화형 워크플로우를 지원합니다.
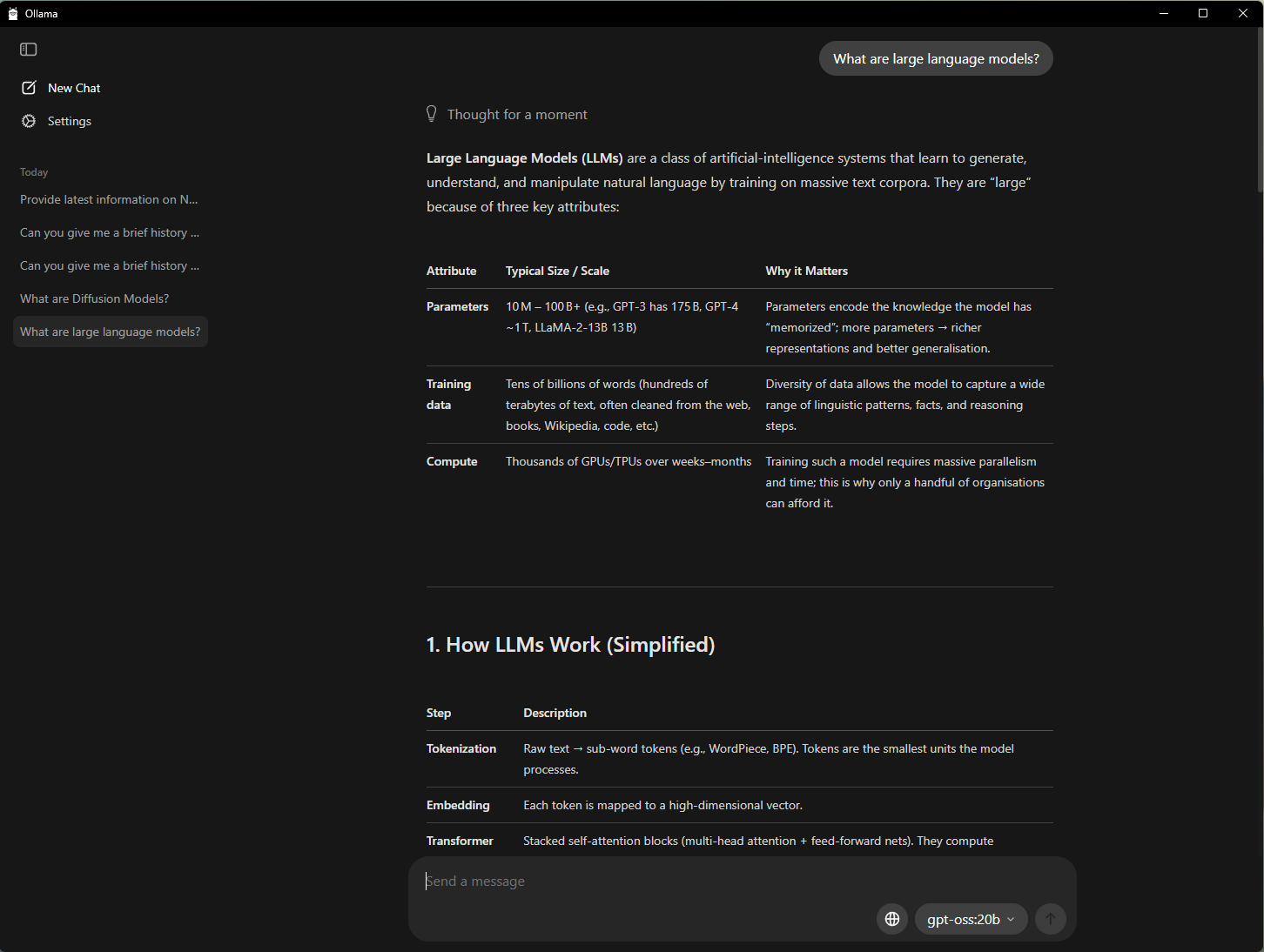
NVIDIA는 Ollama와 협력하여 성능과 사용자 경험을 개선했습니다. 최근 주요 개선 사항은 다음과 같습니다.
- OpenAI의 gpt-oss-20B 모델 및 Google의 Gemma 3 모델을 위한 GeForce RTX GPU의 성능 개선
- 초고효율 RAG를 위한 새로운 Gemma 3 270M 및 EmbeddingGemma 모델 지원
- 메모리 사용률을 극대화하고 정확히 보고할 수 있도록 모델 스케줄링 시스템 개선
- 안정성과 다중 GPU 처리 성능 향상
Ollama는 다른 애플리케이션과 함께 사용할 수 있는 개발자 프레임워크입니다. 예를 들어 AnythingLLM은 사용자가 모든 LLM을 기반으로 자신만의 AI 어시스턴트를 구축할 수 있는 오픈 소스 앱으로, Ollama 기반에서 실행되어 모든 가속 성능을 그대로 누릴 수 있습니다.
애호가들은 인기 있는 llama.cpp 프레임워크 기반 앱인 LM Studio를 사용하여 로컬 LLM을 시작할 수 있습니다. 이 앱은 모델을 로컬로 실행하기 위한 사용자 친화적인 인터페이스를 제공하여, 사용자가 다른 LLM을 로드하고 실시간으로 채팅할 수 있으며, 사용자 지정 프로젝트에 통합하기 위한 로컬 애플리케이션 프로그래밍 인터페이스(API) 엔드포인트 역할을 할 수 있습니다.
NVIDIA는 llama.cpp와 협력하여 NVIDIA RTX GPU에서 성능을 최적화했습니다. 최신 업데이트는 다음과 같습니다.
- 새로운 hybrid-mamba 아키텍처를 기반으로 하는 최신 NVIDIA Nemotron Nano v2 9B 모델 지원
- 이제 Flash Attention이 기본적으로 켜져 있어 Flash Attention이 꺼진 상태에 비해 최대 20%의 성능 향상 제공
- RMS Norm과 빠른 나눗셈 기반 모듈로에 대한 CUDA 커널 최적화를 통해 최대 9%의 성능 향상 달성
- 개발자가 향후 버전을 쉽게 적용할 수 있도록 시맨틱 버전 관리 도입
RTX에서 gpt-oss와, NVIDIA가 LM Studio와 협력하여 RTX PC에서 LLM 성능을 가속화한 방법에 대해 자세히 알아보세요.
AnythingLLM으로 나만의 AI 학습 도우미 만들기
LLM을 로컬에서 실행하면 개인 정보 보호와 성능 향상 외에도 로드할 수 있는 파일의 개수나 사용 가능한 기간에 대한 제한이 사라져 맥락을 이해하는 AI 대화를 더 오래 할 수 있습니다. 이를 통해 대화형 및 생성형 AI 기반 어시스턴트를 더욱 유연하게 구축할 수 있습니다.
학생들에게는 수많은 강의 슬라이드, 필기, 실험 자료, 과거 시험지를 관리하는 것이 벅찰 수 있습니다. 로컬 LLM을 통해 개인 학습 스타일에 맞춰 적응하는 맞춤형 튜터를 만들 수 있습니다.
아래 데모는 학생들이 로컬 LLM을 사용하여 생성형 AI 기반 학습 도우미를 만드는 방법을 보여줍니다.
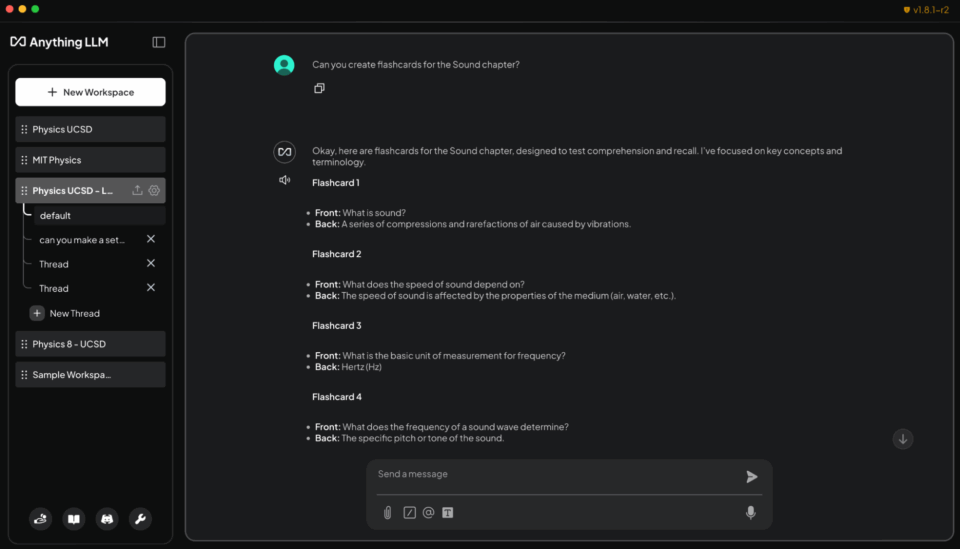
이를 위한 간단한 방법은 AnythingLLM을 사용하는 것입니다. AnythingLLM은 사용자가 문서와 데이터에 연결하여 사용자 지정 AI 챗봇과 에이전트를 구축할 수 있도록 지원하는 애플리케이션입니다. 문서 업로드, 사용자 지정 지식 기반, 대화 인터페이스를 지원합니다. 따라서 연구, 프로젝트 또는 일상적인 작업을 지원하는 맞춤형 AI를 만들고 싶은 모든 사용자에게 유연한 도구입니다. 또한 RTX 가속화를 통해 사용자는 더욱 빠른 응답 속도를 경험할 수 있습니다.
RTX PC에서 AnythingLLM에 강의 계획서, 과제, 교과서를 로드하여 학생들은 적응력이 뛰어난 상호 작용형 학습 파트너를 얻을 수 있습니다. 학생들은 일반 텍스트나 음성을 사용하여 에이전트에게 다음과 같은 작업을 요청할 수 있습니다.
- 강의 슬라이드에서 플래시 카드 생성: “사운드 챕터 강의 슬라이드에서 플래시 카드를 생성하세요. 한쪽에는 핵심 용어를, 다른 한쪽에는 정의를 두세요.”
- 자료 기반 문맥 질문하기: “물리학 8 노트를 사용하여 운동량 보존을 설명하세요.”
- 시험 준비를 위한 퀴즈 만들기 및 채점: “화학 교과서의 5~6장을 기반으로 10개 질문으로 구성된 객관식 퀴즈를 만들고 답변을 채점하세요.”
- 어려운 문제 단계별 풀이: “코딩 숙제에서 4번 문제를 해결하는 방법을 단계별로 보여주세요.”
교실 밖에서 취미 활동가와 전문가가 AnythingLLM을 사용하여 새로운 분야의 자격증 준비나 유사한 학습 목적에 사용할 수 있습니다. 또한 RTX GPU에서 로컬로 실행되면, 구독 비용이나 사용 제한 없이 빠르고 비공개로 응답을 제공합니다.
Project G-Assist 이제 노트북 설정 제어가 가능합니다.
Project G-Assist는 실험적인 AI 어시스턴트로, 사용자가 메뉴를 탐험할 필요 없이 간단한 음성 또는 텍스트 명령을 통해 게이밍 PC를 조정, 제어, 최적화할 수 있도록 지원합니다. 다음날부터 새로운 G-Assist 업데이트가 NVIDIA App의 홈 화면을 통해 출시됩니다.
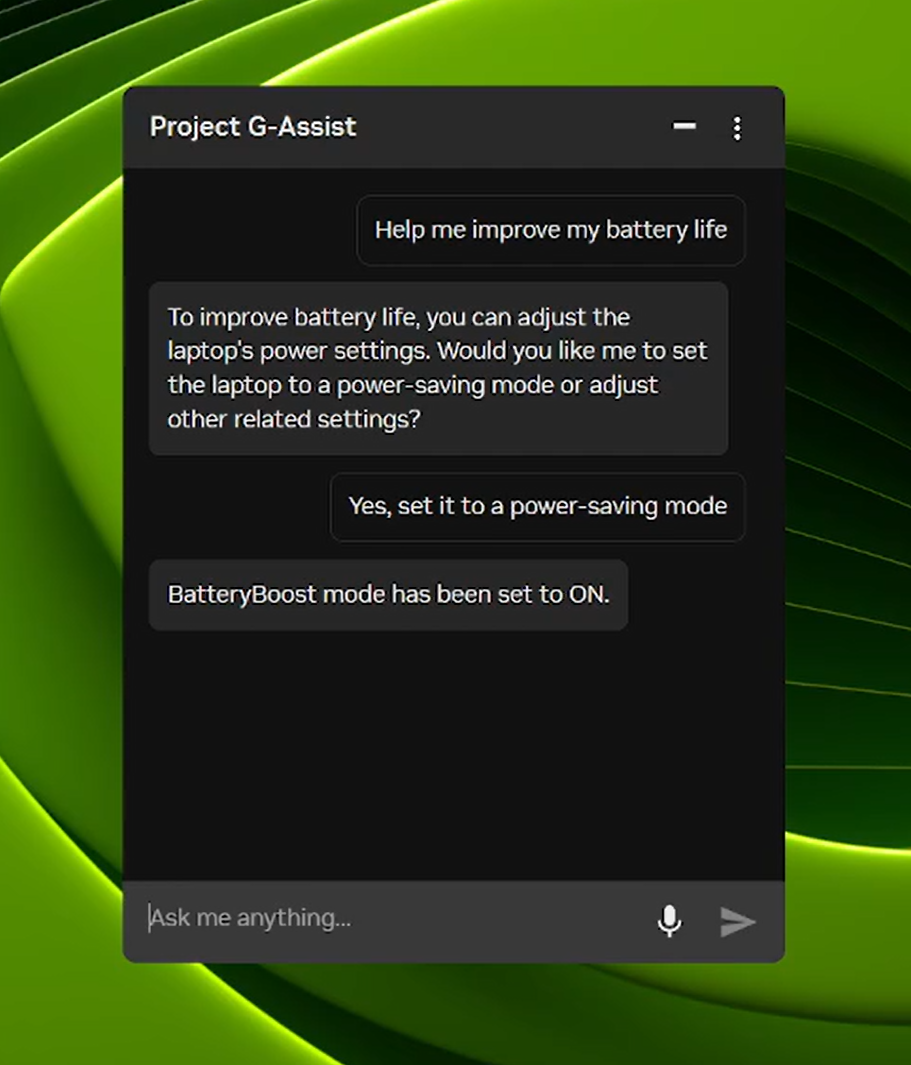
새롭고 더 효율적인 AI 모델과 8월에 출시된 대부분의 RTX GPU에 대한 지원을 기반으로, 이번 G-Assist 업데이트는 노트북 설정을 조정하는 명령을 추가합니다.
- 노트북에 최적화된 앱 프로필: 노트북이 충전기에 연결되어 있지 않을 때 효율성, 품질, 밸런스를 위해 게임 또는 앱을 자동으로 조정합니다.
- BatteryBoost 제어: BatteryBoost를 활성화하거나 조정하여 프레임 레이트를 원활하게 유지하면서 배터리 수명을 연장합니다.
- WhisperMode 제어: 필요할 때 팬 소음을 최대 50%까지 줄이고, 그렇지 않을 때 전체 성능으로 돌아갑니다.
Project G-Assist는 확장이 가능합니다. G-Assist 플러그인 빌더를 사용하면 사용자가 새로운 명령을 추가하거나 외부 도구를 쉽게 연결할 수 있는 플러그인을 통해 G-Assist 기능을 만들고 사용자 지정할 수 있습니다. 또한 G-Assist 플러그인 허브를 통해 사용자는 플러그인을 쉽게 검색하고 설치하여 G-Assist 기능을 확장할 수 있습니다.
NVIDIA의 G-Assist GitHub 저장소에서 샘플 플러그인, 단계별 지침, 사용자 지정 기능 구축을 위한 문서 등 시작 방법에 대한 자료를 확인해 보세요.
#놓치지 마세요 — RTX AI PC의 최신 혁신
🎉Ollama, RTX에서 주요 성능 향상
최신 업데이트에는 OpenAI의 gpt-oss-20B 성능이 최적화되고, 더 빠른 Gemma 3 모델 및 더 스마트한 모델 스케줄링이 포함되어 메모리 문제를 줄이고 멀티 GPU 효율성을 개선합니다.
🚀 Llama.cpp 및 GGML 에RTX 최적화
최신 업데이트는 NVIDIA Nemotron Nano v2 9B 모델, 기본 활성화된 Flash Attention, CUDA 커널 최적화를 통해 RTX GPU에서 더 빠르고 효율적인 추론 성능을 제공합니다.
⚡ Project G-Assist 업데이트 배포
NVIDIA App을 통해 G-Assist v0.1.18 업데이트를 다운로드하세요. 이번 업데이트에는 노트북 사용자를 위한 새로운 명령과 개선된 응답 품질이 포함되어 있습니다.
⚙️ RTX용 NVIDIA TensorRT가 통합된 Windows ML 정식 출시
Microsoft는 RTX 가속화를 위해 NVIDIA TensorRT와 함께 Windows ML을 출시했으며, Windows 11 PC에서 최대 50% 더 빠른 추론을 제공하고, 배포와 LLM, 확산 및 기타 모델 유형을 지원합니다.
🌐 NVIDIA Nemotron, AI 개발 가속화
NVIDIA Nemotron 오픈 모델, 데이터 세트, 기법은 일반화된 추론부터 산업별 애플리케이션에 이르기까지 AI 분야의 혁신을 가속화하고 있습니다.
Facebook, Instagram, TikTok, X에서 NVIDIA AI PC와 연결하고 RTX AI PC 뉴스레터를 구독하여 최신 정보를 받아보세요.
LinkedIn 및 X에서 NVIDIA 워크플로우 스테이션을 팔로우하세요.
소프트웨어 제품 정보는 공지를 참조해 주세요.