
의료 분야에서 도출되는 진단 정보, 인터랙티브 게임 속 캐릭터의 대사, 고객 서비스 에이전트의 자율적인 문제 해결과 같은 AI 기반 상호작용은 동일한 지능 단위인 ‘토큰’을 기반으로 구축되죠.
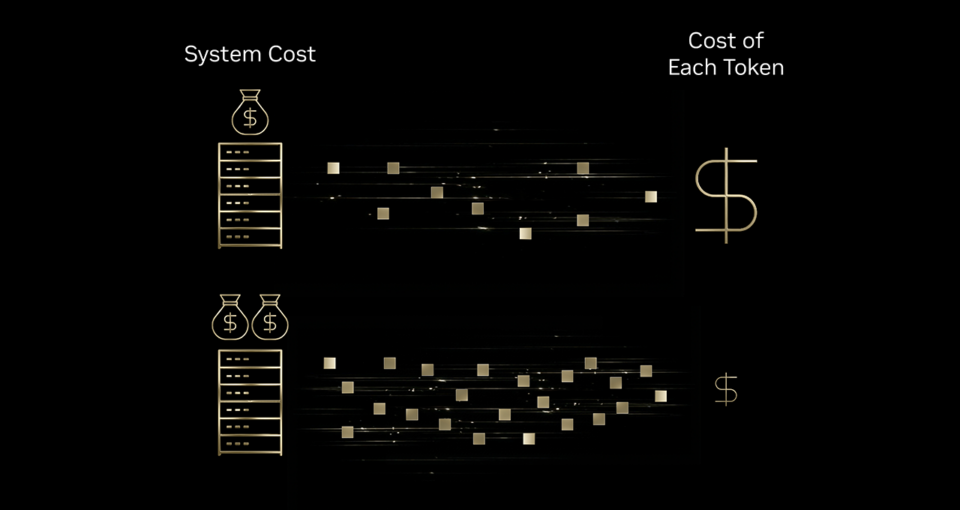
이러한 AI 상호작용을 확장하려면 기업은 더 많은 토큰을 감당할 수 있는지 고려해야 합니다. 해답은 더 나은 토크노믹스(tokenomics)에 있으며, 그 핵심은 각 토큰의 비용을 낮추는 데 있는데요. 이러한 비용 하락 추세는 산업 전반에 걸쳐 나타나고 있습니다. 최근 MIT 연구에 따르면, 인프라와 알고리즘 효율성 향상을 통해 최첨단 성능의 추론 비용이 연간 최대 10배까지 감소하고 있는 것으로 나타났습니다.
인프라 효율성이 토크노믹스를 어떻게 개선하는지 이해하기 위해 고속 인쇄기에 비유해볼 수 있습니다. 잉크, 에너지, 장비에 대한 추가적인 투자로 인쇄기가 10배의 생산량을 만들어낼 수 있다면, 개별 페이지를 인쇄하는 비용은 낮아지죠. 마찬가지로 AI 인프라에 대한 투자는 비용 증가 대비 훨씬 더 많은 토큰을 생성할 수 있게 하며, 결과적으로 토큰당 비용을 의미 있게 낮출 수 있습니다.
이러한 이유로 베이스텐(Baseten), 딥인프라(DeepInfra), 파이어웍스 AI(Fireworks AI), 투게더 AI(Together AI) 등 선도적인 추론 서비스 제공업체들이 NVIDIA Blackwell 플랫폼을 채택하고 있습니다. NVIDIA Hopper 플랫폼 대비 토큰당 비용을 최대 10배까지 절감할 수 있죠.
이 기업들은 현재 최첨단 수준의 지능에 도달한 첨단 오픈소스 모델을 호스팅하고 있습니다. 또한 오픈소스 기반의 최첨단 지능, NVIDIA Blackwell의 긴밀한 하드웨어·소프트웨어 공동 설계, 그리고 자체 최적화된 추론 스택을 결합하기도 하는데요. 이로써 전 산업 분야에 걸쳐 기업들은 토큰 비용을 획기적으로 절감할 수 있습니다.
의료 – 베이스텐과 설리.ai, AI 추론 비용 10배 절감
의료 분야에서는 의료 코드 작성, 문서화, 보험 서류 관리와 같은 반복적이고 시간이 많이 소요되는 업무가 있습니다. 따라서 의료진은 환자에게 할애할 수 있는 시간이 줄어듭니다.
설리.ai(Sully.ai)는 의료 코드 작성과 진료 기록 작성과 같은 반복 업무를 처리할 수 있는 ‘AI 직원’을 개발해 이러한 문제를 해결하고 있습니다. 그러나 플랫폼이 확장됨에 따라, 설리.ai가 사용하던 자체 폐쇄형 모델은 세 가지 병목 현상을 초래했죠. 실시간 임상 워크플로우에서의 예측 불가능한 지연 시간, 수익보다 빠르게 증가하는 추론 비용, 그리고 모델 품질과 업데이트에 대한 제한된 통제력입니다.
이러한 병목 현상을 해결하기 위해 설리.ai는 베이스텐의 모델 API(Model API)를 활용하고 있습니다. 이를 통해 NVIDIA Blackwell GPU 상에서 gpt-oss-120b와 같은 오픈소스 모델을 배포하죠. 베이스텐은 저정밀 NVFP4 데이터 형식과 NVIDIA 텐서RT-LLM(TensorRT-LLM) 라이브러리, NVIDIA Dynamo 추론 프레임워크를 활용해 추론을 최적화했습니다. 또한 NVIDIA Blackwell이 NVIDIA Hopper 플랫폼 대비 달러당 처리량이 최대 2.5배 우수하다는 점을 확인한 후, 이를 모델 API 실행 플랫폼으로 선정했죠.
그 결과 설리.ai의 추론 비용은 기존 폐쇄형 모델 대비 10배, 즉 90% 감소했으며, 의료 기록 생성과 같은 핵심 워크플로우에서 응답 시간은 65% 개선됐습니다. 이로써 회사는 데이터 입력 등 기타 수작업으로 인해 소모되던 시간을 줄여, 의료진에게 3천만 분 이상의 시간을 돌려줬습니다.
게이밍 – 딥인프라와 래티튜드, 토큰당 비용 4배 절감
래티튜드(Latitude)는 어드벤처 스토리 게임 ‘AI 던전(AI Dungeon)’과, 출시 예정인 AI 기반 롤플레잉 게임 플랫폼 ‘보야지(Voyage)’를 통해 AI 네이티브 게임의 미래를 구축하고 있습니다. 플레이어는 보야지에서 원하는 행동을 자유롭게 선택하고 자신만의 이야기를 만들어갈 수 있죠.
이 플랫폼은 플레이어의 행동에 대응하기 위해 거대 언어 모델(LLM)을 활용합니다. 그러나 플레이어의 모든 행동이 추론 요청으로 이어지기 때문에 확장성 측면에서 도전 과제가 따르는데요. 사용자 참여도가 높아질수록 비용이 증가하며, 몰입감 있는 경험을 유지하기 위해서는 응답 속도 또한 충분히 빠르게 유지돼야 합니다.

래티튜드는 NVIDIA Blackwell GPU와 TensorRT-LLM을 기반으로 하는 딥인프라의 추론 플랫폼에서 대규모 오픈소스 모델을 운영하고 있습니다. 딥인프라는 대규모 전문가 혼합(MoE) 모델에서 NVIDIA Hopper 플랫폼 기준 100만 토큰당 20센트였던 비용을 Blackwell에서는 10센트로 절감했죠. 여기에 Blackwell의 네이티브 저정밀 NVFP4 형식을 적용해 비용을 5센트까지 낮추며, 고객이 기대하는 정확도를 유지하면서 토큰당 비용을 총 4배 절감했습니다.
이러한 대규모 MoE 모델을 딥인프라의 Blackwell 기반 플랫폼에서 운영함으로써 래티튜드는 비용 효율성을 확보하면서도 빠르고 안정적인 응답을 제공할 수 있게 됐습니다. 딥인프라의 추론 플랫폼은 트래픽 급증 상황에서도 안정적으로 이를 처리할 수 있는데요. 따라서 래티튜드가 플레이어 경험을 저해하지 않으면서 보다 고도화된 모델을 배포할 수 있도록 지원합니다.
에이전틱 챗 – 파이어웍스 AI와 센티언트 파운데이션, AI 비용 최대 50% 절감
센티언트 랩스(Sentient Labs)는 AI 개발자들이 함께 모여 강력한 추론(reasoning) AI 시스템을 오픈소스로 구축하도록 지원하는 데 주력하고 있습니다. 이를 통해 보안 자율성, 에이전틱 아키텍처, 지속적 학습에 대한 연구를 바탕으로 보다 복잡한 추론 문제 해결을 가속화하는 것을 목표로 하죠.
센티언트 랩스의 첫 번째 애플리케이션인 ‘센티언트 챗(Sentient Chat)’은 복잡한 멀티 에이전트 워크플로우를 오케스트레이션하고, 커뮤니티에서 개발된 12개 이상의 특화된 AI 에이전트를 통합합니다. 이로 인해 단일 사용자 질의가 다수의 자율적 상호작용으로 이어지는 연쇄적인 처리 과정을 유발할 수 있는데요. 또한 높은 인프라 비용으로 이어질 수 있어 대규모 연산 자원이 필요합니다.
이러한 규모와 복잡성을 관리하기 위해 센티언트는 NVIDIA Blackwell 기반에서 구동되는 파이어웍스 AI의 추론 플랫폼을 활용하고 있습니다. 파이어웍스의 Blackwell 최적화 추론 스택을 통해 센티언트는 기존 호퍼 기반 배포 대비 25~50% 향상된 비용 효율성을 달성했습니다.
또한, GPU당 처리량이 증가함에 따라 동일한 비용으로 훨씬 더 많은 동시 사용자를 지원할 수 있게 됐습니다. 이 플랫폼의 확장성은 24시간 내 180만 명의 대기 사용자가 몰린 바이럴 론칭을 안정적으로 지원했으며, 일관된 낮은 지연 시간을 유지하면서 단일 주간에 560만 건의 질의를 처리했습니다.
고객 서비스 – 투게더 AI와 데카곤, 비용 6배 절감
음성 AI를 활용한 고객 서비스 통화는 아주 짧은 지연만 발생해도 사용자가 상담원을 제치고 말하거나 통화를 종료하는 등 불편을 겪을 수 있어, 종종 사용자 경험 저하로 이어집니다.
데카곤(Decagon)은 기업용 고객 지원을 위한 AI 에이전트를 개발하고 있으며, 그중에서도 AI 기반 음성은 가장 까다로운 채널이죠. 데카곤은 예측 불가능한 트래픽 부하에서도 1초 미만의 응답을 제공할 수 있는 인프라와 24시간 음성 배포를 지원하는 토크노믹스가 필요했습니다.

투게더 AI는 NVIDIA Blackwell GPU 기반에서 데카곤의 멀티모델 음성 스택에 대한 프로덕션 추론을 수행하고 있습니다. 이 기업들은 여러 핵심 최적화를 공동으로 구현했는데요. 여기에는 작은 모델이 빠르게 응답을 생성하고, 더 큰 모델이 백그라운드에서 정확도를 검증하는 추측 디코딩, 반복되는 대화 요소를 캐싱해 응답 속도를 높이는 기술, 그리고 성능 저하 없이 트래픽 급증을 처리할 수 있는 자동 확장 기능 등이 포함됩니다.
그 결과 데카곤은 질의당 수천 개의 토큰을 처리하는 상황에서도 400밀리초(ms) 미만의 응답 시간을 달성했습니다. 단일 음성 상호작용을 완료하는 데 드는 총 비용인 질의당 비용은 기존 폐쇄형 모델 대비 6배 절감됐죠. 이러한 성과는 데카곤의 멀티모델 전략(일부는 오픈소스, 일부는 NVIDIA GPU 기반 자체 훈련 모델), NVIDIA Blackwell의 긴밀한 하드웨어·소프트웨어 공동 설계, 그리고 투게더의 최적화된 추론 스택이 결합된 결과입니다.
고도의 공동 설계를 통한 토크노믹스 최적화
의료, 게이밍, 고객 서비스 전반에서 나타난 이러한 비용 절감 효과는 NVIDIA Blackwell의 높은 효율성에 기반합니다. NVIDIA GB200 NVL72 시스템은 이러한 효과를 더욱 확장해, NVIDIA Hopper 대비 추론용 MoE 모델에서 토큰당 비용을 최대 10배까지 낮추는 혁신적인 성과를 제공하죠.
컴퓨팅, 네트워킹, 소프트웨어 전반에 걸친 NVIDIA의 긴밀한 공동 설계와 파트너 생태계는 대규모 환경에서 토큰당 비용을 획기적으로 낮추는 데 기여하고 있습니다.
이러한 흐름은 NVIDIA Rubin 플랫폼으로 이어집니다. 루빈 플랫폼은 6개의 신규 칩을 단일 AI 슈퍼컴퓨터로 통합해, Blackwell 대비 최대 10배의 성능 향상과 10배의 토큰 비용 절감을 제공합니다.
NVIDIA의 풀스택 추론 플랫폼을 통해 AI 추론을 위한 토크노믹스를 어떻게 개선하고 있는지 자세히 확인하세요.