
개인용 에이전트의 인기가 폭발적으로 늘고 있는데요, OpenClaw와 Hermes 같은 오픈 소스 프로젝트가 GitHub의 AI 개발자 커뮤니티에서 빠르게 확산되고 있습니다. 이러한 에이전트는 개인의 취향과 워크플로에 맞게 동작하도록 설계돼, 애플리케이션과 상호작용하고 콘텐츠를 생성하며 반복 작업을 자동화하고 여러 단계로 이뤄진 작업까지 처리합니다. 이 모든 과정이 기기에서 로컬로 실행되죠.
NVIDIA는 NVIDIA GTC Taipei at COMPUTEX에서 개인용 에이전트를 위해 특별히 설계된 새로운 Windows PC 제품군 NVIDIA RTX Spark를 공개했습니다. 동시에 더 넓은 NVIDIA RTX·DGX 생태계 전반으로 로컬 에이전트를 확장하는 다양한 업데이트도 함께 선보였습니다.
에이전트를 안전하고 사적으로 실행하려면 그에 걸맞은 하드웨어가 필요합니다. RTX Spark는 1페타플롭의 AI 연산 성능과 128GB 통합 메모리를 갖춰 온디바이스 에이전트의 연산 수요를 충족하며, 단순한 도구를 넘어 팀원처럼 활약하는 새로운 차원의 컴퓨터를 제시하죠. AI와 창작, 게이밍을 위해 설계된 RTX Spark는 NVIDIA의 30년 기술 혁신을 하루 종일 가는 배터리의 슬림한 Windows 노트북과 초고효율 데스크톱 PC에 담아냈습니다.
Windows와의 협력은 개인용에서 엔터프라이즈 솔루션까지 폭넓게 확장됩니다. 이번 행사에서는 전문가를 위한 궁극의 AI 데스크사이드 슈퍼컴퓨터 Windows를 위한 NVIDIA DGX Station도 함께 공개됐는데요, 데이터센터급 GPU와 CPU를 추론에 활용하면서도 관리 편의성과 보안, 호환성을 위해 Windows를 탑재한 데스크톱 시스템입니다.
이 밖에 발표된 주요 소식은 다음과 같습니다:
- NVIDIA OpenShell 런타임이 Windows에 도입됩니다. Microsoft의 새로운 에이전트용 보안 프리미티브를 기반으로 구축돼, 개발자에게 안전한 온디바이스 에이전트를 손쉽게 배포할 수 있는 패키지를 제공하죠. Hermes Agent와 OpenClaw 역시 새로운 Windows 애플리케이션에 OpenShell과 Microsoft 보안 프리미티브를 통합할 예정입니다.
- NVIDIA NemoClaw blueprint가 GeForce RTX, RTX PRO, RTX·DGX Spark, DGX Station에 이르는 NVIDIA의 전체 로컬 AI 라인업으로 확대되며, 간소화된 새 설치 프로그램과 Hermes Agent 지원이 더해집니다.
- llama.cpp와 vLLM의 멀티 토큰 예측(multi-token prediction)으로 주요 에이전트 모델에서 2배 빠른 추론 성능을 구현하고, llama.cpp와 ComfyUI를 위한 새로운 멀티 GPU 최적화도 제공합니다.
- H Company는 RTX·DGX PC에 최적화된 컴퓨터 사용(computer-use) 도구를 공개합니다. 여기에는 새로운 모델과 곧 출시될 데스크톱 에이전트 하네스가 포함되죠.
- Adobe는 Photoshop과 Premiere 앱을 재설계하고, Blender는 NVIDIA DLSS 4.5 Ray Reconstruction을 추가하며, NVIDIA는 ComfyUI에 적용될 RTX Video Frame Generation을 공개했습니다. 이러한 업데이트는 모두 올해 가을 RTX Spark와 함께 제공됩니다.
- NVIDIA Broadcast 2.2 업데이트는 Studio Voice 기능 최적화와 Elgato Stream Deck 지원을 제공하며, NVIDIA Project G-Assist에도 Stream Deck 연동이 추가됩니다.
로컬 에이전트 AI: Windows RTX PC에서 개인화되고 안전하며 빠르게
그동안 에이전트의 폭넓은 확산은 사용자의 주력 PC에서 에이전트를 안전하고 사적으로 실행하기 어렵다는 한계에 가로막혀 왔습니다.
NVIDIA와 Microsoft는 이러한 과제를 해결하기 위해 협력해, 온디바이스 에이전트를 위한 견고하고 안전한 Windows 플랫폼을 선보입니다.
이번 협력은 에이전트가 안전하게, 그리고 사용자의 완전한 통제 아래 실행되도록 보장하는 탄탄한 토대, 즉 새로운 Windows 보안 프리미티브와 NVIDIA OpenShell 런타임에서 출발합니다.
새로운 Windows 프리미티브는 에이전트를 네이티브로 구축하고 실행하는 데 필요한 신원 확인과 격리(containment), 정책, 종단 간 보안 기능을 제공합니다. NVIDIA OpenShell은 여기에 더해 에이전트가 할 수 있는 일과 할 수 없는 일을 사용자가 직접 정의하고, 사용자의 개인정보 보호 정책에 따라 쿼리를 로컬 모델로 지능적으로 라우팅하며, 클라우드 모델로 전송되는 쿼리 속 개인정보를 가려 주는 추가 정책 기능을 갖췄습니다.
이처럼 견고한 보안·프라이버시 계층은 Hermes Agent, OpenClaw 같은 선도적인 에이전트 개발사들이 새로운 Windows 앱에 도입하고 있습니다. 이들 신규 앱 덕분에 사용자는 강력한 온디바이스 에이전트를 손쉽고 안전하게 활용할 수 있는데요, 이 에이전트는 Windows 애플리케이션에서 작업을 실행하고, 여러 앱을 넘나드는 워크플로를 추론하며, 이미지와 영상을 생성하고, 플러그인과 앱을 코딩하며, 로컬 파일을 의미 기반으로 검색합니다.
로컬 기기에서 에이전트를 구동하려면 견고한 보안과 고성능 하드웨어가 모두 필요합니다. RTX Spark는 최대 1페타플롭의 AI 연산 성능과 128GB 통합 메모리를 갖춰 온디바이스 에이전트의 처리 요구를 충족합니다.
또한 NVIDIA는 이러한 에이전트가 의존하는 로컬 오픈 모델 생태계도 가속하고 있습니다.
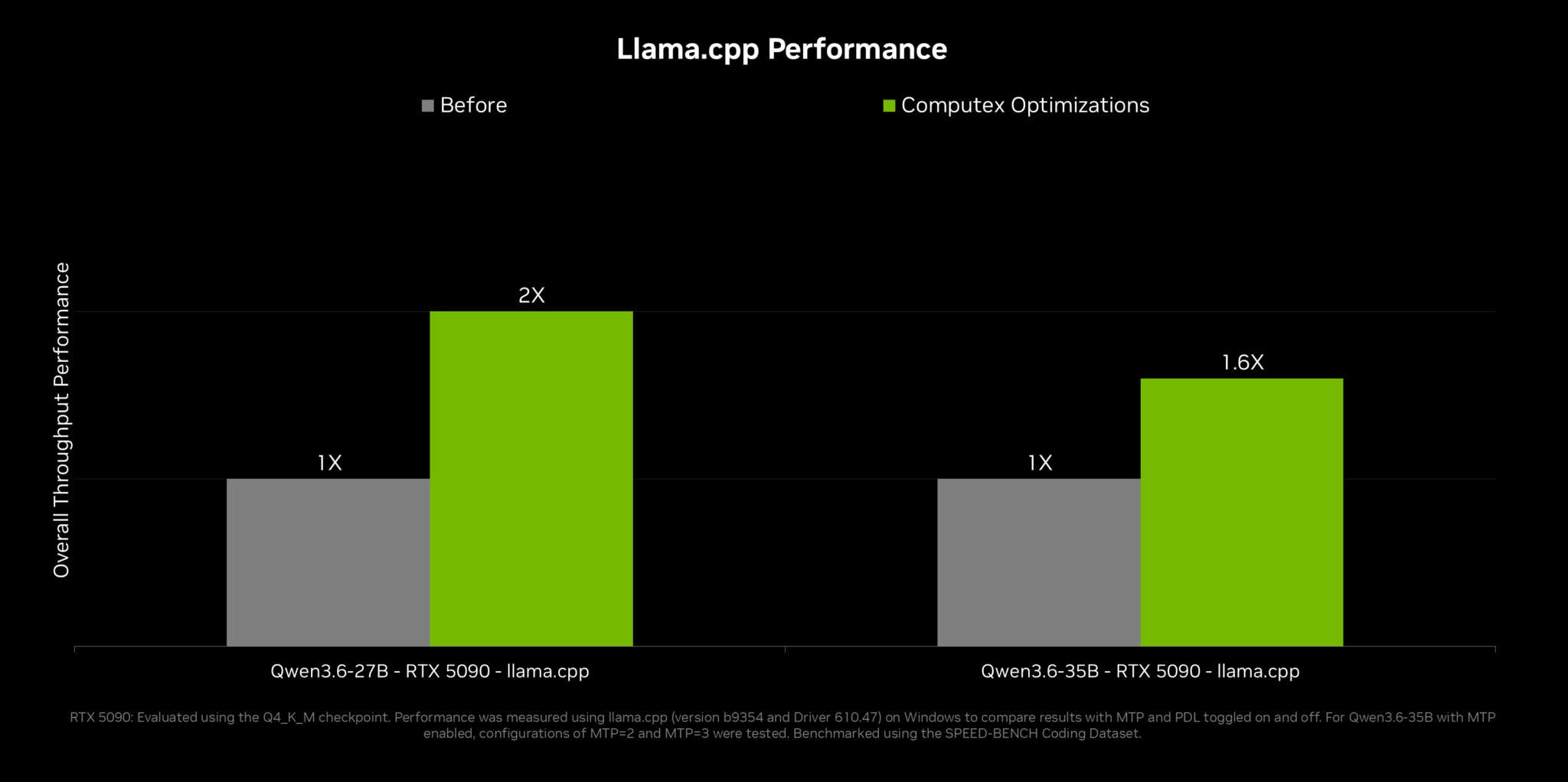
NVIDIA는 llama.cpp 커뮤니티와 협력해 멀티 토큰 예측(MTP) 같은 기능과 최적화를 구현했습니다. MTP는 작은 드래프트 모델이 한 번에 여러 토큰을 제안하면 타깃 모델이 단일 패스로 이를 검증하는 추측 디코딩(speculative decoding) 기법인데요, 여기에 프로그래매틱 디펜던트 론치(programmatic dependent launch) 같은 최적화가 더해져 Qwen 3.6·3.5 27B에서 2배, Qwen 3.6·3.5 35B에서 1.6배의 성능 향상을 끌어냅니다. 이러한 업데이트는 llama.cpp 웹UI와 LM Studio에서 이용할 수 있습니다.
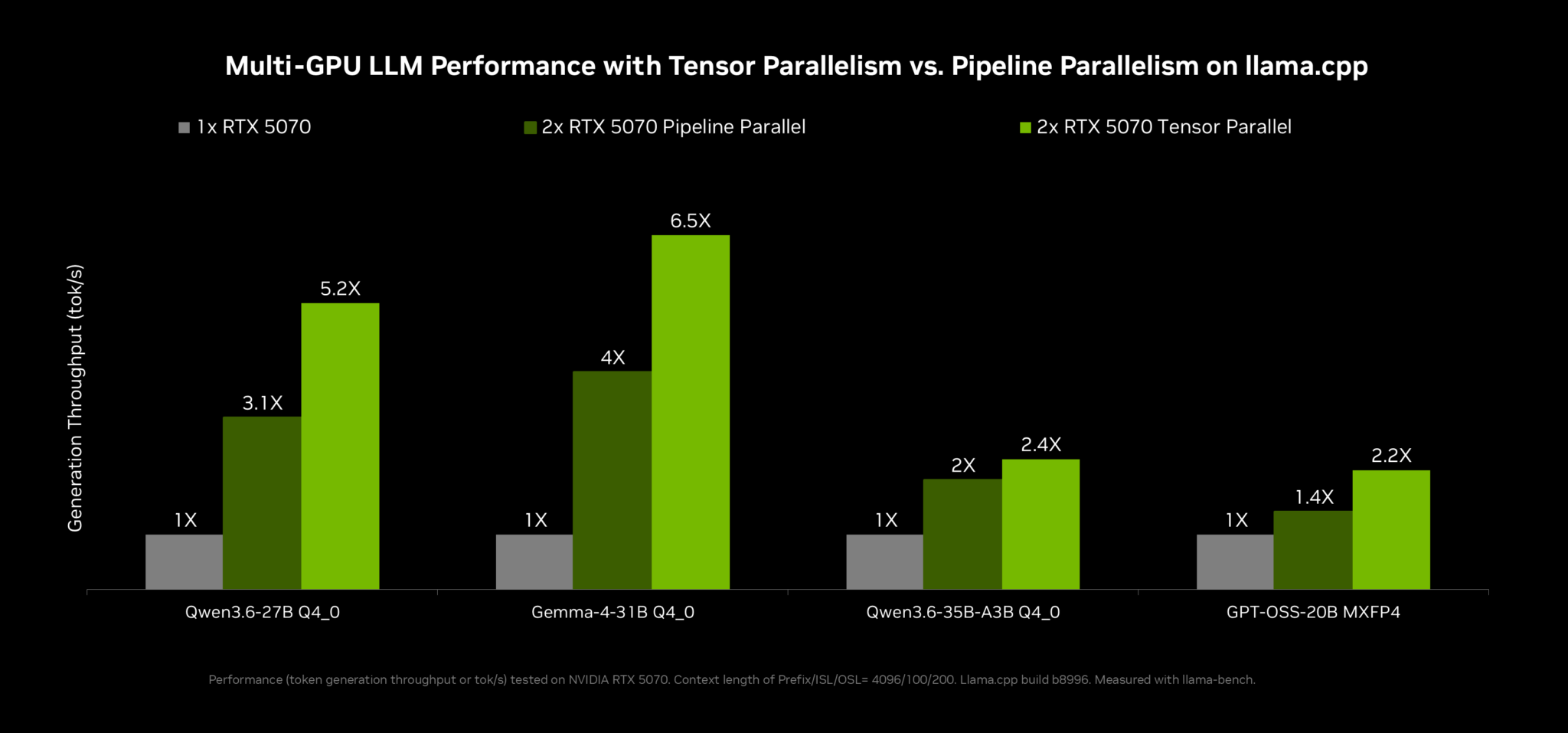
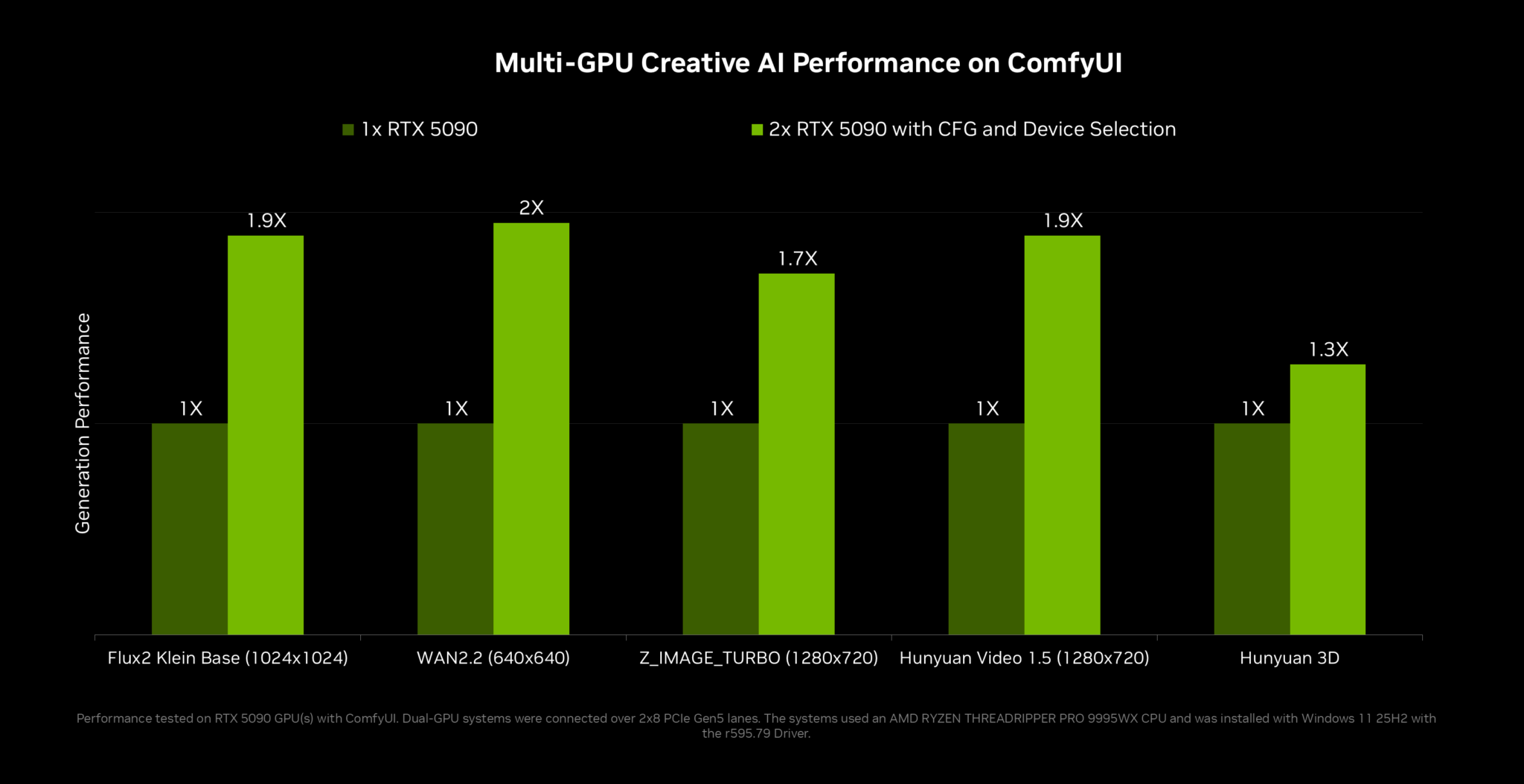
멀티 GPU 구성을 운용하는 AI 애호가를 위해, NVIDIA는 오픈 소스 커뮤니티와 협력해 가장 인기 있는 로컬 AI 도구 두 가지를 개선했습니다:
- llama.cpp는 텐서 병렬화(tensor parallelism)를 추가해 동급 GPU 두 개에서 최대 2배의 메모리와 1.8배의 연산 성능을 제공합니다.
- ComfyUI는 새로운 classifier-free guidance 방식을 도입해 동급 GPU 두 개에서 최대 2배의 성능을 내고, 모델 체인을 여러 GPU에 분할해 합산된 메모리를 활용하는 옵션도 추가했습니다.
NVIDIA는 H Company와 함께 에이전트의 역량도 확장하고 있습니다. H Company의 컴퓨터 사용(computer-use) 하네스는 에이전트가 화면을 보고 마치 사용자처럼 마우스와 키보드를 조작해 PC를 다룰 수 있게 하는데요, 애플리케이션 프로그래밍 인터페이스(API)가 없는 앱에서도 작동하며, 로컬 모델 지원과 함께 곧 RTX·DGX PC에 제공될 예정입니다.
NVIDIA는 H Company와 협력해 최첨단 Holo Computer Use 모델을 양자화하고 하네스를 가속했으며, 그 결과 NVIDIA GPU에서 2배의 속도 향상과 함께 메모리 사용량을 35% 줄였습니다. 해당 모델은 지금 다운로드할 수 있으며, Holo Desktop 앱도 곧 출시됩니다.
Linux를 위한 에이전트 최적화
언제든 접근할 수 있는 로컬 에이전트가 필요한 개발자, 특히 Linux 환경이 필요한 개발자에게 NVIDIA DGX Spark는 가장 강력한 개인용 에이전트 AI 컴퓨터입니다. 대용량 메모리와 빠른 연산, NVIDIA CUDA 생태계와의 호환성을 하나로 결합했죠.
이번 달 공개된 DGX Spark OS는 간소화된 NemoClaw 설치 프로그램으로 가장 매끄러운 초기 사용 경험을 제공하며, 주요 에이전트 모델에서 한층 빠른 추론까지 지원합니다.
NemoClaw는 이제 Linux와 Windows Subsystem for Linux에서 모든 NVIDIA RTX·DGX PC에 사용할 수 있습니다. 간소화된 새 설치 프로그램으로 Linux에 로컬 에이전트를 안전하게 배포할 수 있으며, 자동 샌드박싱과 Hermes Agent 지원이 더해졌습니다.
NVIDIA는 vLLM과 협력해 에이전트 추론을 최적화했으며, vLLM 자체 최적화와 Qwen 3.6 35B용으로 새롭게 최적화한 NVFP4 체크포인트를 선보였습니다. 이번 업데이트는 기존에 제공되던 Unsloth의 NVFP4 체크포인트 대비 DGX Spark에서 2.6배의 성능을 제공하며, 커널 개선과 혼합 정밀도(mixed precision), MTP를 위한 CUDA Graph 지원을 포함합니다.
DGX Spark에서 NVFP4 전문가 혼합(mixture-of-experts) 모델을 서빙하는 전체 과정은 vLLM 블로그에서 확인할 수 있습니다. 통합 메모리 튜닝부터 실제 동작하는 NVIDIA Nemotron 3 Super 레퍼런스 설정까지 자세히 다룹니다.
Adobe와 함께 선사하는 강력한 창작 경험
NVIDIA는 Adobe와 협력해 RTX Spark에 맞춰 Adobe Premiere와 Photoshop을 재설계하고 있습니다. Photoshop의 Firefly 기반 Generative Fill, Premiere의 Generative Extend는 창작의 힘과 정밀도, 제어력을 제공하는 수백 가지 가속 도구에 속하죠. RTX Spark는 이러한 역량을 한 단계 더 끌어올려, 창작 워크플로 전반에서 AI와 편집, 컬러링, 이펙트를 최대 2배 빠르게 처리합니다.
Adobe Premiere는 RTX Spark의 통합 메모리와 Blackwell GPU, TensorRT 소프트웨어를 활용하는 새로운 영상 파이프라인을 탑재합니다. 이를 통해 편집과 색 보정에서 실시간 성능을 구현하고, GPU 가속 AI 성능과 복잡한 타임라인의 한층 효율적인 렌더링을 제공하죠. 또한 Adobe의 Substance 3D Painter와 Stager가 RTX Spark에서 네이티브로 실행돼, 3D 텍스처링과 장면 제작 워크플로가 더욱 매끄럽고 빠르게 반응합니다.
Adobe의 차세대 Photoshop 엔진은 GPU 가속 합성(compositing)에 최적화돼 라이브 필터와 하이 다이내믹 레인지(HDR), 자연스러운 최신 브러싱을 지원합니다. 이 AI 네이티브 파이프라인은 TensorRT를 포함한 RTX Spark의 모든 성능을 끌어내도록 설계됐습니다.
나아가 Adobe는 Premiere와 Photoshop을 더욱 확장해, 사용자가 Windows 에이전트와 함께 창작하고 편집하며 디자인할 수 있도록 지원합니다. 크리에이터에게는 워크플로를 가속해 주는 협업 팀원이 생기는 셈이죠.
Premiere와 Photoshop, Substance 등 Adobe 창작 앱의 업데이트는 RTX Spark 출시에 맞춰 순차적으로 제공될 예정입니다.
크리에이터를 위한 새로운 도구와 앱 업데이트
새로운 NVIDIA 플랫폼 업데이트와 파트너 앱 최적화가 더 넓은 RTX 생태계 전반으로 확산되고 있는데요, 일부는 이미 제공되고 나머지는 올해 가을 RTX Spark와 함께 선보입니다.
NVIDIA Broadcast 2.2는 어떤 마이크든 스튜디오급 음질로 들리게 해 주는 AI 기능 Studio Voice를 베타에서 정식 버전으로 전환했습니다. Studio Voice는 이제 GeForce RTX 3060 이상 GPU에서 향상된 성능으로 작동하죠. 또한 이 애플리케이션에는 Elgato Stream Deck 연동과 사용자 지정 키보드 단축키가 추가됐습니다.
Project G-Assist에도 Elgato MCP Server를 통한 Stream Deck 지원이 추가돼, 사용자가 자신의 방송 환경에 AI 어시스턴트 기능을 적용할 수 있습니다.
또한 Blender Cycles는 DLSS 4.5 Ray Reconstruction을 새로운 디노이저로 통합해, 패스 트레이싱 뷰포트를 인터랙티브한 실시간 뷰어로 바꿔 놓습니다. 덕분에 3D 아티스트는 장면을 자유롭게 둘러보면서도 최종에 가까운 렌더링 품질을 확인할 수 있어, 라이팅과 룩 개발(look-development) 워크플로가 완전히 달라지죠. 이 업데이트는 올해 가을 RTX Spark와 함께 Blender 5.3으로 출시됩니다.
RTX Spark와 함께 출시되는 RTX Video Frame Generation은 영상 프레임 속도를 실시간으로 2배 또는 4배 높여 주는 새로운 AI 이펙트입니다. AI 모델이 보통 생성하는 초당 15~20프레임(fps) 결과물을 개선하는 데 안성맞춤이죠. ComfyUI 노드와 Python 휠 형태로 제공돼, AI 아티스트는 낮은 fps로 영상을 더 빠르게 생성한 뒤 매끄러운 재생 속도까지 보간(interpolate)할 수 있습니다.
#ICYMI: RTX AI Garage 최신 소식
🪐 슈퍼칩과 에이전트에 관한 NVIDIA와 Windows의 협력, 파트너 노트북·소형 데스크톱에 대한 자세한 내용은 NVIDIA RTX Spark 전체 발표 내용에서 확인하세요.
💻 ASUS ProArt 크리에이터 노트북에는 이제 Black Forest Labs의 FLUX.2 Klein 4B가 기본 탑재됩니다. MuseTree 앱을 통해 사전 설치되는 이 경량화 이미지 모델은 NVFP4 포맷과 NVIDIA TensorRT for RTX 소프트웨어 개발 키트로 최적화됐는데요, 크리에이터는 최대 2.5배의 속도 향상과 560%의 메모리 절감을 누릴 수 있습니다. 게다가 첫 실행부터 별도의 모델 다운로드나 ComfyUI 설정 없이 곧바로 로컬에서 이미지를 생성할 수 있죠.
🎬 NVIDIA AI for Media 소프트웨어 개발 키트가 업데이트를 선보입니다. 여기에는 프랑스어·독일어·스페인어에 최적화된 새로운 LipSync NVIDIA NIM 마이크로서비스가 포함되며, Active Speaker Detection NIM 마이크로서비스에도 여러 영상 간 화자 연동을 지원하는 멀티 카메라 기능이 추가됩니다.
🤖 RTX PC와 DGX Spark의 Hermes Agent 및 자기 개선형(self-improving) AI를 다룬 최신 RTX AI Garage 블로그 게시물도 확인해 보세요.
RTX Spark 소식은 Facebook, Instagram, TikTok, X에서 만나보고, RTX Spark 뉴스레터를 구독해 최신 정보를 받아보세요.
소프트웨어 제품 정보에 관한 고지사항을 확인하세요.