
Megatron과 DeepSpeed로 더 강력해진 세계에서 가장 큰 생성 언어 모델 Megatron-Turing NLG 뜯어보기(1)과 이어집니다.
결과와 성과
언어 모델(LM) 분야의 최근 연구는 강력한 성능으로 사전 트레이닝된 모델의 경우, 미세 조정이 없이도 광범위한 NLP 작업을 경쟁적으로 수행할 수 있음을 보여줍니다.
LM의 스케일업이 제로샷 또는 퓨샷 학습 기능을 강화하는 방법을 이해하고자 MT-NLG를 평가한 결과, 이 모델이 여러 범주의 NLP 태스크에서 새롭고 훌륭한 결과들을 달성함을 입증했습니다. 포괄적인 평가를 위해 5개 영역에 걸쳐 8개의 태스크를 선정했습니다.
- 텍스트 예측 태스크인 람바다(LAMBADA)에서 해당 모델은 주어진 문단의 마지막 단어를 예측합니다.
- 독해 태스크인 레이스-h(RACE-h)와 불Q(BoolQ)에서 해당 모델은 주어진 문단을 바탕으로 출제되는 질문에 대한 답을 생성합니다.
- 상식 추론 태스크인 파이큐에이(PiQA)와 헬라스웨그(HellaSwag), 위노그란데(Winogrande)의 문제를 해결하기 위해서는 언어의 통계적 패턴을 넘어서는 수준의 상식이 요구되었습니다.
- 자연어 추론의 경우, 까다로운 벤치마크인 ANLI-R2와 한스(HANS)로 과거 모델들의 전형적인 실패 사례를 평가합니다.
- 어휘의 중의성 해소 태스크인 위씨(WiC)는 다의어의 맥락상 이해도를 평가합니다.
재현성(reproducibility)을 장려하는 의미에서 오픈 소스 프로젝트인 ‘lm-evaluation-harness’에 기초해 평가 관련 사항을 설정하는 한편, 태스크별로 적절한 변화를 주어 우리의 설정 내용이 기존 작업과 보다 긴밀히 연결되도록 했습니다. 최적의 샷 수를 찾는 작업은 따로 수행하지 않고 제로샷, 원샷, 퓨샷 설정에서 MT-NLG 모델을 평가했습니다.
Table 2는 정확도 메트릭(metric)의 결과입니다. 공개적으로 사용할 수 있는 경우 테스트 세트에 대한 평가를 진행했으며, 그렇지 않은 경우 개발 세트의 숫자를 보고했습니다. 이에 따라 람바다와 레이스-h, ANLI-R2는 테스트 세트, 다른 태스크들은 개발 세트의 내용이 보고됐습니다.
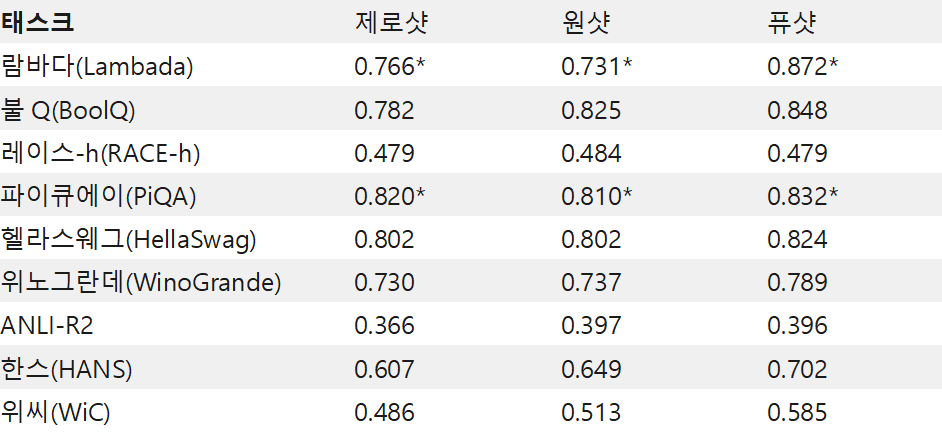
퓨샷 성능을 예로 들어보죠. 기존에 발표된 연구와 비교해 MT-NLG는 고무적인 발전상을 보여줍니다. 이 같은 개선은 두 문장 사이의 관계를 발견하거나 서로 비교하는 태스크(가령 위씨와 ANLI)에서 특히 두드러지는데요. 이는 기존의 모델들이 난항을 겪는 범주이기도 하죠. 제로샷과 원샷 평가의 태스크 대부분에서도 유사한 개선이 관찰됐습니다. MT-NLG가 기존 모델보다 적은 수의 토큰으로 트레이닝된다는 사실에도 주목해야 합니다. 대규모 모델도 학습 속도를 높일 수 있음을 보여주기 때문이죠.
한스 데이터세트의 경우, 데이터세트 전반의 메트릭을 보고하는 기준 모델(baselines)을 찾지 못했습니다. 한스 보고서의 분석에 따르면 MNLI에서 트레이닝된 BERT 기준 모델은 하위 범주의 절반에서 완벽에 가까운 성능을 보이는 반면, 나머지 절반에서는 제로에 가까운 성능을 기록합니다. 이는 기준 모델들이 해당 보고서에 제시된 비논리적 구문 휴리스틱에 크게 의존하고 있음을 보여줍니다.
MT-NLG 모델 역시 이 점에서 어려움을 겪지만 제로샷 설정에서 절반 이상의 사례를 정확히 예측하고, 1개 내지 4개의 샷(예시)을 허용할 경우 수치가 더욱 개선됩니다. 최종적으로 제로샷, 원샷, 퓨샷 설정에서 MT-NLG 모델은 파이큐에이 개발 세트와 람바다 테스트 세트 1위를 달성했습니다.
벤치마크 태스크를 바탕으로 집계한 수치를 리포팅했으며 모델 아웃풋의 질적 분석을 수행한 결과 흥미로운 점을 발견했습니다(표3 참조). MT-NLG 모델이 문맥에서 기초적인 수학 연산을 추론할 수 있다는 점(샘플 1)이 관찰된 것인데요. 맥락이 상징하는 바가 심히 애매한 경우(샘플 2)도 마찬가지였습니다. 이 모델은 수리 감각을 자랑하는 것과는 거리가 멀지만 연산을 단순히 암기하는 수준은 넘어서는 듯 보입니다.
한스 태스크의 샘플(표3의 마지막 행)도 살펴보도록 하겠습니다. 이 태스크에서 우리는 간단한 구문 구조가 포함된 과제를 질문으로 제시하고 모델에 답변을 요구했죠. 구조는 단순하지만 기존의 자연어 추론(NLI) 모델은 이 같은 인풋에 곤란을 겪곤 합니다. 미세 조정된 모델들은 NLI 데이터세트의 시스템적 편향(bias) 때문에 특정한 구문 구조와 그 안에 담긴 관계를 잘못 조합하게 되죠. 그런 경우 MT-NLG는 미세 조정 없이 경쟁력을 발휘합니다.

언어 모델의 편향
거대 언어 모델들은 최첨단 언어 생성 테크놀로지를 발전시키지만 편향과 독성(toxicity) 등의 문제로 곤란을 겪기도 합니다. 언어 모델의 이 같은 과제를 이해, 제거하고자 NVIDIA와 마이크로소프트를 비롯한 AI 커뮤니티가 적극적인 연구를 진행하고 있습니다.
우리는 MT-NLG가 트레이닝을 진행하는 데이터에서 정형화된 이미지와 편향을 받아들이는 과정을 예의주시하고 있습니다. NVIDIA와 마이크로소프트는 관련 문제의 해결에 헌신하는 한편, 모델의 편향을 수량화하는 연구를 지속적으로 지원하고 장려합니다.
또한 프로덕션 시나리오에 MT-NLG를 적용하는 경우에는 사용자에게 초래할지도 모를 잠재적 해악을 완화, 최소화하는 적절한 조치들이 마련되어 있는지 확인해야 합니다. 일체의 작업은 ‘마이크로소프트의 책임 있는 AI를 위한 원칙(Microsoft Responsible AI Principles)’에 규정된 사항들을 준수해야 하는데요. 이 원칙들은 공정성, 신뢰성과 안전성, 프라이버시와 보안, 포용성, 투명성, 책임성 등을 초석으로 삼아 AI의 개발과 활용에 보다 책임 있고 믿을 만한 접근법을 취해야 한다고 강조하고 있습니다.
결론
지금 우리는 AI의 발전이 무어의 법칙(Moore’s law)을 크게 앞지르는 시대에 살고 있습니다. 새 세대 GPU들이 등장을 거듭하고 번개 같은 속도로 상호 연결되면서 더욱 월등한 컴퓨팅 성능을 제공하는 과정을 지속적으로 목격하고 있죠. 동시에 AI 모델의 하이퍼스케일링(hyperscaling)이 곧 성능의 개선으로 이어지는 혁신에는 그 끝이 없는 것처럼 보이기도 합니다.
이 두 가지 추세를 결합하는 소프트웨어 혁신이 최적화와 효율성의 한계를 허뭅니다. MT-NLG는 NVIDIA Selene이나 마이크로소프트 애저 NDv4 같은 슈퍼컴퓨터가 Megatron-LM과 딥스피드 등의 소프트웨어 혁신과 병용되어 대규모 언어 AI 모델을 트레이닝할 때 과연 어디까지 가능한지 보여주는 사례라 할 수 있죠.
오늘날 우리가 확보한 품질과 성과는 자연어 분야에서 AI가 가진 잠재력을 최대한 이끌어내기 위한 여정을 더욱 가속할 것입니다. Megatron-LM과 딥스피드라는 혁신은 기존의, 그리고 미래의 AI 모델 개발을 지원하는 동시에 대규모 AI 모델의 트레이닝을 보다 저렴하고 신속하게 만들어줄 것입니다.
우리는 MT-NLG가 미래 제품들을 구체화하고 관련 커뮤니티에 동기를 부여해 NLP의 경계를 더욱 확장하기를 기대합니다. 그 기나긴 여정의 끝은 아직 한참이 남았지만, 미래의 가능성은 우리를 더욱 설레게 만들 뿐입니다.
참여
이 프로젝트에는 다음의 참여자들이 함께했습니다.
NVIDIA: 모스토파 파트와리(Mostofa Patwary), 모하마드 슈이비(Mohammad Shoeybi), 패트릭 리그레슬리(Patrick LeGresley), 시리마이 프라뷰모예(Shrimai Prabhumoye), 재러드 캐스퍼(Jared Casper), 비자이 코시칸티(Vijay Korthikanti), 바티카 싱(Vartika Singh), 줄리 베르나워(Julie Bernauer), 마이클 휴스턴(Michael Houston), 브라이언 카탄차로(Bryan Catanzaro).
마이크로소프트: 샤든 스미스(Shaden Smith), 브랜던 노릭(Brandon Norick), 샘얌 라즈반다리(Samyam Rajbhandari), 준 리우(Zhun Liu), 조지 저비어스(George Zerveas), 엘튼 장(Elton Zhang), 레자 야즈다니 아미나바디(Reza Yazdani Aminabadi), 시아 송(Xia Song), 유시옹 헤(Yuxiong He), 제프리 주(Jeffrey Zhu), 제니퍼 크루잔(Jennifer Cruzan), 우메시 마단(Umesh Madan), 루이스 바르가스(Luis Vargas), 사우라브 티와리(Saurabh Tiwary).