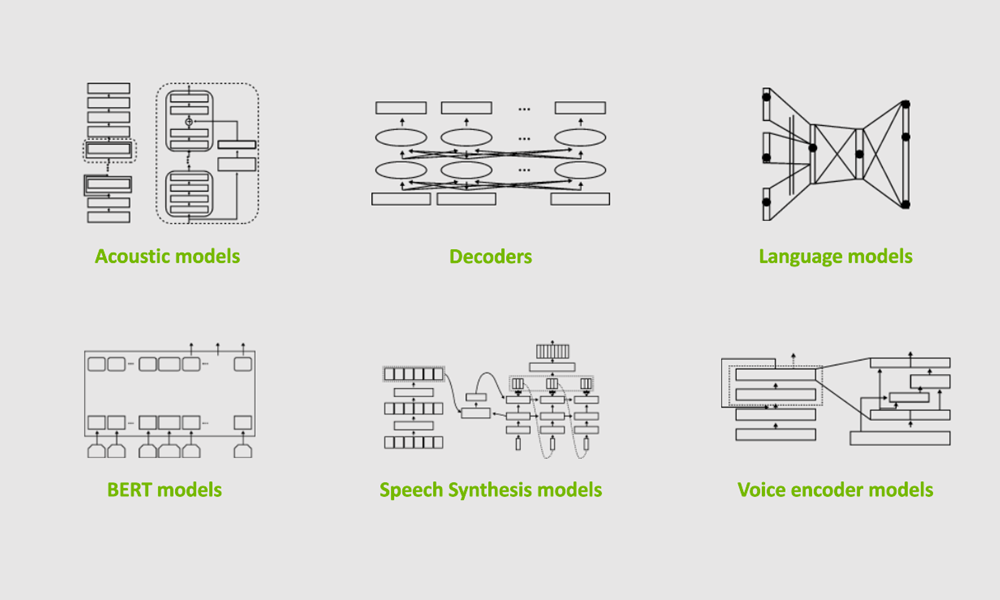
NVIDIA NeMo는 자동 음성 인식(ASR)과 자연어 처리(NLP), 음성 합성 시스템(TTS)의 연구자들을 위한 대화형 AI 툴킷입니다. NeMo의 주목적은 이미 구축되어 있는 결과물(코드와 사전 훈련된 모델)을 재사용하여 새로운 대화형 AI 모델을 보다 간편하게 제작할 수 있도록 돕는 것입니다. NeMo는 오픈 소스 프로젝트이며, 대화형 AI 연구 커뮤니티의 참여를 환영합니다.
NeMo 1.0 업데이트는 아키텍처와 코드의 품질, 다큐멘테이션(documentation)을 대폭 개선했습니다. 또한 새롭게 추가된 최첨단 신경망과 사전 훈련된 체크포인트(checkpoint)들을 다양한 언어로 제공합니다. NeMo를 시작하는 가장 좋은 방법은 여러분이 일상적으로 사용하는 파이토치(PyTorch) 환경에 설치하는 것입니다.
pip install nemo_toolkit[all]
NeMo 컬렉션
NeMo는 파이토치 생태계 프로젝트의 하나로, 훈련을 위한 파이토치 라이트닝(PyTorch Lightning)과 구성 관리를 위한 히드라(Hydra)에 주로 의존합니다. 이 두 프로젝트 역시 파이토치 생태계에 해당하죠. 파이토치 코드 일체에서 NeMo의 모델과 모듈을 사용할 수도 있습니다.
NeMo는 ASR과 NLP, TTS 컬렉션을 제공합니다. 이 컬렉션들은 여러분의 대화형 AI 실험에 즉시 사용이 가능한 모델과 모듈로 구성됩니다. 이 모델들에서 가장 눈여겨볼 사항은 다양한 데이터세트에서 수만에 달하는 GPU 시간을 들여 사전 훈련한 가중치(weights)를 제공한다는 점입니다.
음성 인식
NeMo의 자동 음성 인식(ASR) 컬렉션은 초급에서 고급에 이르기까지, 모든 단계의 연구자에게 다양한 기능을 지원하는 가장 광범위한 컬렉션입니다. 음성 인식용 딥 러닝을 처음 접하는 경우라면, ASR과 NeMo를 개략적으로 살펴볼 수 있는 인터랙티브 노트북으로 시작하기를 권장합니다. 자신만의 모델을 구축하고자 하는 숙련된 연구자들을 위해서는 다음과 같이 즉시 사용이 가능한 빌딩 블록(building block)들이 제공됩니다.
- 데이터 레이어(Data layers)
- 인코더
- 증강 모듈(Augmentation modules)
- 텍스트의 정규화(normalization)와 역정규화(denormalization)
- RNN-T 등의 진일보한 디코더
NeMo ASR 컬렉션은 Jasper와 QuartzNet, CitriNet, Conformer 등 다양한 유형의 ASR 네트워크를 제공합니다. NeMo 1.0의 업데이트와 함께 차세대 주요 ASR 모델로 발돋움한 CitriNet과 Conformer 모델들은 단어 오류율(WER) 측면에서 Jasper나 QuartzNet보다 높은 정확도를 달성하면서 효율성은 비슷하거나 더 높은 수준을 유지합니다.
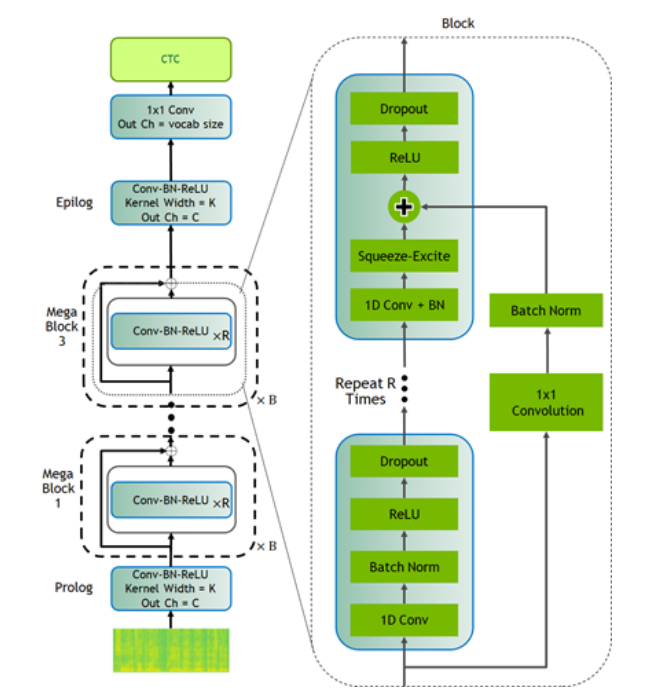
CitriNet
CitriNet은 ContextNet에서 처음 소개된 아이디어의 일부를 활용해 만들어진 QuartzNet을 개선한 버전입니다. 압축과 여기(Squeeze-and-Excitation) 메커니즘, 낱말 토큰화(tokenization)를 통한 서브워드(subword) 인코딩으로 음성 전사물(transcript)의 정확도를 높이는 한편, 비자기회귀형(nonautoregressive)의 CTC 기반 디코딩 체계를 사용하여 추론의 효율성을 확보합니다.
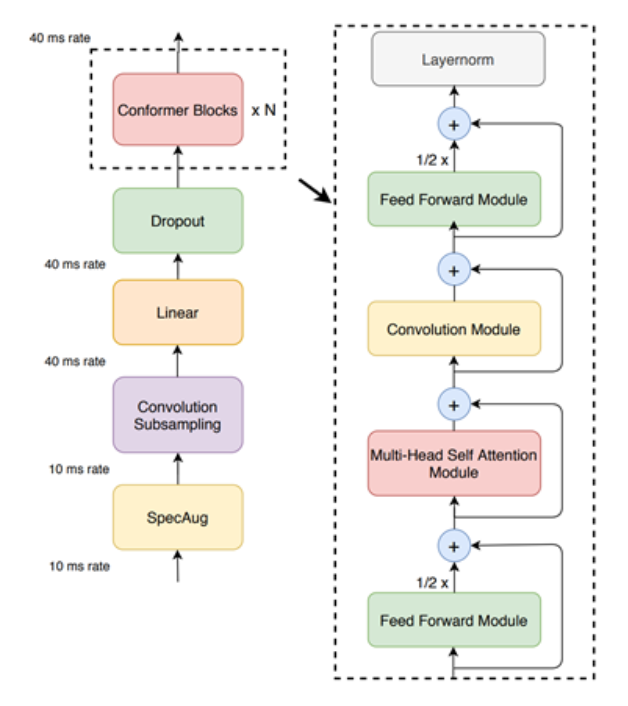
Conformer-CTC
Conformer-CTC는 RNN-T 로스(loss) 대신 CTC 로스와 디코딩을 사용하는 Conformer 모델을 CTC 기반으로 변형한 것으로, 비자기회기형 모델에 해당합니다. 이 모델은 셀프 어텐션(self-attention) 모듈과 합성곱(convolution) 모듈을 결합하여 양쪽의 이점 모두를 최대한 누릴 수 있게 해줍니다. 셀프 어텐션 모듈로 전체적 상호작용을 학습하는 한편 합성곱 모듈로는 로컬 영역의 상관관계를 효율적으로 포착합니다.
이 모델을 활용하여 어텐션 기반 모델들을 실험할 수 있습니다. Conformer와 CitriNet 모델들은 셀프 어텐션, 압축과 여기 메커니즘으로 전체적 맥락을 확보하여 오프라인 시나리오의 단어 오류율에서 우수한 결과를 보여줍니다.
Citrinet과 Conformer 모델은 CTC나 RNN-T 디코더와 병용이 가능합니다.
NVIDIA는 수만에 달하는 GPU 시간을 투자하여 ASR 모델을 다양한 언어로 훈련했습니다. 이 체크포인트들은 이제 NeMo를 통해 커뮤니티에 무상으로 제공됩니다. 이번 릴리스부터 NeMo는 영어와 스페인어, 중국어, 카탈루냐어, 이탈리아어, 러시아어, 프랑스어, 폴란드어로 된 ASR모델들을 지원합니다. 또한 모질라(Mozilla)와 제휴하고 모질라 커먼 보이스(Mozilla Common Voice) 프로젝트의 도움을 받아 더욱 다양한 사전 훈련 모델을 제공합니다.
NeMo의 ASR 컬렉션에는 재사용이 가능한 빌딩 블록과 사전 훈련 모델들이 포함되어 음성 활성도 감지, 화자 인식, 화자 분할(diarization), 음성 명령 감지 등의 음성 기반 주요 작업들을 다양하게 수행할 수 있습니다.
자연어 처리
자연어 처리(NLP)는 고품질의 대화형 AI에 필수적입니다. NeMo의 NLP 컬렉션은 질의응답, 구두점과 대문자 처리, 개체명 인식, 신경망 기계 번역처럼 대표적인 NLP 작업을 위해 사전 훈련을 마친 모델들을 제공합니다.
허깅 페이스(Hugging Face)의 트랜스포머(transformer)들은 개발자와 연구자의 사용자 경험을 개선하고 사전 훈련된 모델들을 방대하게 제공하여, NLP 분야가 최근에 이룩한 여러 혁신들에 이바지해 왔습니다. NeMo는 트랜스포머와 호환이 가능하므로 사전 훈련을 마친 허깅 페이스 NLP 모델의 대부분을 NeMo로 가져오기 할 수 있습니다. 트랜스포머를 기반으로 사전 훈련을 진행한 BERT식 체크포인트를 기본 작업의 인코더로 활용할 수도 있습니다. 기본 작업의 언어 모델은 허깅 페이스 트랜스포머에서 사전 훈련된 모델로 초기화됩니다.
NeMo는 NVIDIA Megatron으로 훈련을 진행하는 모델과 통합됩니다. 따라서 사용자의 질의응답 모델과 신경망 기계 번역 모델에 Megatron 기반 인코더를 통합할 수 있죠. 또한 Megatron 기반의 모델 병렬화 모델(model-parallel model)을 미세 조정하는 데 NeMo를 사용할 수도 있습니다.
신경망 기계 번역
오늘날처럼 세계화된 사회에서는 다른 언어를 사용하는 이들과의 의사소통이 중요합니다. 앞으로는 원문을 한 언어에서 다른 언어로 변환하는 능력을 겸비한 대화형 AI 시스템이 강력한 의사소통 수단으로 자리잡게 될 전망입니다. NeMo 1.0은 트랜스포머 기반 모델과 함께 신경망 기계 번역(NMT)을 지원하여 엔드-투-엔드 언어 변환 파이프라인을 신속하게 구축하도록 해줍니다. 이번 릴리스에는 다음 언어의 양방향 변환을 지원하도록 사전 훈련을 마친 NMT 모델들이 포함됐습니다.
- 영어 <-> 스페인어
- 영어 <-> 러시아어
- 영어 <-> 표준 중국어
- 영어 <-> 독일어
- 영어 <-> 프랑스어
토큰화는 NLP에서 매우 중요하기 때문에 NeMo는 허깅 페이스를 비롯하여 센텐스피스(SentencePiece)와 유토큰투미(YouTokenToMe) 등 가장 널리 사용되는 토크나이저(tokenizer)들을 지원합니다.
음성 합성
인간이 컴퓨터에게 말을 걸 수 있다면 컴퓨터 또한 그에 대답할 수 있어야 합니다. 음성 합성은 텍스트를 입력값으로 삼아 인간화된 소리를 출력합니다. 이를 달성하는 모델은 크게 두 가지, 텍스트에서 스펙트로그램(spectrograms)을 생성하는 스펙트로그램 생성기와 스펙트로그램에서 소리를 생성하는 보코더(vocoder)입니다. NeMo의 문자 음성 변환(TTS) 컬렉션은 다음의 모델을 제공합니다.
- 사전 훈련된 스펙트로그램 생성기 모델: 타코트론2(Tacotron2), 글로우TTS(GlowTTS), 패스트스피치(Fastspeech), 패스트피치(Fastpitch), 토크넷(Talknet)
- 사전 훈련된 보코더 모델: 하이파이Gan(HiFiGan), 멜Gan(MelGan), 스퀴즈웨이브(SqueezeWave), 유니글로우(Uniglow), 웨이브글로우(WaveGlow)
- 엔드-투-엔드 모델: 패스트피치하이파이GAN(FastPitchHiFiGAN), 패스트스피치2 하이파이gan(Fastspeech2 Hifigan)
엔드-투-엔드 대화형 AI 예제
다음의 간략한 예제는 NeMo를 사용하여 범용 번역기 애플리케이션의 프로토타입을 구축하는 방법을 보여줍니다. 이 애플리케이션은 러시아어로 된 오디오 파일을 가져와 영어로 번역된 오디오를 생성합니다. AudioTranslationSample.ipynb 노트북으로 재생할 수 있습니다.
# Start by importing NeMo and all three collections
import nemo
import nemo.collections.asr as nemo_asr
import nemo.collections.nlp as nemo_nlp
import nemo.collections.tts as nemo_tts
# Next, automatically download pretrained models from the NGC cloud
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5")
# Neural Machine Translation model
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6')
# Spectrogram generator that takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.Tacotron2Model.from_pretrained(model_name="tts_en_tacotron2")
# Vocoder model that takes spectrogram and produces actual audio
vocoder = nemo_tts.models.WaveGlowModel.from_pretrained(model_name="tts_waveglow_88m")
# First step is to transcribe, or recognize, what was said in the audio
russian_text = quartznet.transcribe([Audio_sample])
# Then, translate it to English text
english_text = nmt_model.translate(russian_text)
# Finally, convert it into English audio
# A helper function that combines Tacotron2 and WaveGlow to go directly from
# text to audio
def text_to_audio(text):
parsed = spectrogram_generator.parse(text)
spectrogram = spectrogram_generator.generate_spectrogram(tokens=parsed)
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
return audio.to('cpu').numpy()
audio = text_to_audio(english_text[0])
이 예제에서 가장 주목할 부분은 여기에 사용된 모델 일체를 여러분의 데이터세트에서 미세 조정할 수 있다는 점입니다. 도메인 내 미세 조정은 고유의 애플리케이션에서 모델의 성능을 개선하는 훌륭한 방법입니다. NeMo 깃허브(GitHub) 페이지에서 미세 조정의 다양한 예제를 살펴보실 수 있습니다.
NeMo 모델들은 분야에 관계없이 형태와 사용감이 같습니다. 모델의 구성과 훈련, 사용이 모두 유사한 방식으로 진행됩니다.
NeMo를 활용한 스케일링
다양한 실험의 진행과 새로운 아이디어의 신속한 검증은 연구를 성공으로 이끄는 열쇠입니다. NeMo는 다수의 노드와 수백 개의 GPU에서 NVIDIA의 최신 Tensor Core와 모델 병렬화 훈련 기능을 사용하여 학습의 속도를 높입니다. 이 기능들은 직관적이고 사용이 간편한 API를 갖춘 파이토치 라이트닝 트레이너와 함께 제공됩니다.
음성 인식, 언어 모델링, 기계 번역을 위해 NVIDIA는 고성능 웹 데이터세트 기반 데이터 로더(data loader)를 지원합니다. 이 데이터 로더들은 수만 시간 분량에 달하는 음성 데이터를 스케일링하여 수천 개의 GPU에 방대하게 분산된 환경에서도 훌륭한 성능을 달성합니다.
NeMo를 활용한 텍스트 처리와 데이터세트 생성
훈련용 데이터의 적절한 준비와 전후 처리는 매우 중요한 과정이지만 머신 러닝 파이프라인 전반에서 자주 간과되고는 합니다. NeMo 1.0에는 데이터세트의 생성과 음성 데이터 탐색기를 위한 신기능들이 추가됐습니다.
NeMo 1.0은 텍스트 정규화와 인버스(inverse) 텍스트 정규화 등 중요한 텍스트 처리 기능을 제공합니다. 텍스트 정규화는 텍스트를 문자 형태에서 언어 형태로 변환합니다. 이는 TTS 모델의 훈련 전에 전처리 단계로 사용됩니다. 또한 ASR 훈련용 전사의 전처리로도 쓰입니다. 인버스 텍스트 정규화(ITN)는 언어를 문자로 변환하는 작업이며 ASR의 후처리 파이프라인으로 자주 사용됩니다. ASR 모델이 언어로 출력한 값을 문자 형태로 바꿔 텍스트의 가독성을 개선합니다.
예를 들어 “무게가 10kg이다”의 정규화 버전은 “무게가 10킬로그램이다”가 될 것입니다.
결론
NeMo 1.0 릴리스는 품질과 다큐멘테이션 전반을 크게 개선합니다. 신경망 기계 번역과 여러 언어로 사전 훈련된 모델 등을 새롭게 추가했습니다. ASR과 TTS를 위한 더욱 발전된 형태의 툴답게 텍스트 정규화와 역정규화, CTC 세그멘테이션(segmentation) 기반 데이터 생성, 음성 데이터 탐색기 등의 신기능들도 더했습니다. 이러한 업데이트는 학계와 산업계의 연구자들이 새로운 대화형 AI 모델을 보다 간편하게 개발, 훈련할 수 있게 해줍니다.
NeMo 모델 다수의 경우, NVIDIA Riva에 내보내기 하여 프로덕션 배포와 고성능 추론을 진행할 수 있습니다. NVIDIA Riva는 GPU에서 실시간 성능을 제공하는 멀티모달 대화형 AI 서비스 구축을 위한 애플리케이션 프레임워크입니다.
NVIDIA는 외부의 조력을 환영합니다! NVIDIA NeMo GitHub 페이지를 방문해 예제들을 경험하고, 커뮤니티 토론에 참여하세요. NeMo와 NVIDIA Riva를 사용하여 모델의 연구에서 제작에 이르는 여정을 지금 시작하세요.