편집자 주: 본 게시물은 RTX PC 사용자를 위한 새로운 하드웨어, 소프트웨어, 도구, 가속화를 보여주는 동시에 기술의 접근성을 높여 AI를 쉽게 이해하도록 돕기 위해 작성된 NVIDIA의 AI Decoded 시리즈의 일부입니다.
초고층 빌딩은 튼튼한 기초에서 시작됩니다. AI로 구동되는 애플리케이션도 마찬가지죠.
파운데이션 모델은 일반적으로 비지도형 기계 학습을 통해 방대한 양의 원시 데이터로 학습된 AI 신경망입니다.
인간과 유사한 언어를 이해하고 생성하도록 훈련된 일종의 인공지능 모델이죠. 컴퓨터가 인간처럼 단어와 문장의 문맥과 의미를 이해할 수 있도록 방대한 양의 책을 읽고 학습할 수 있는 라이브러리를 제공한다고 상상해보세요.
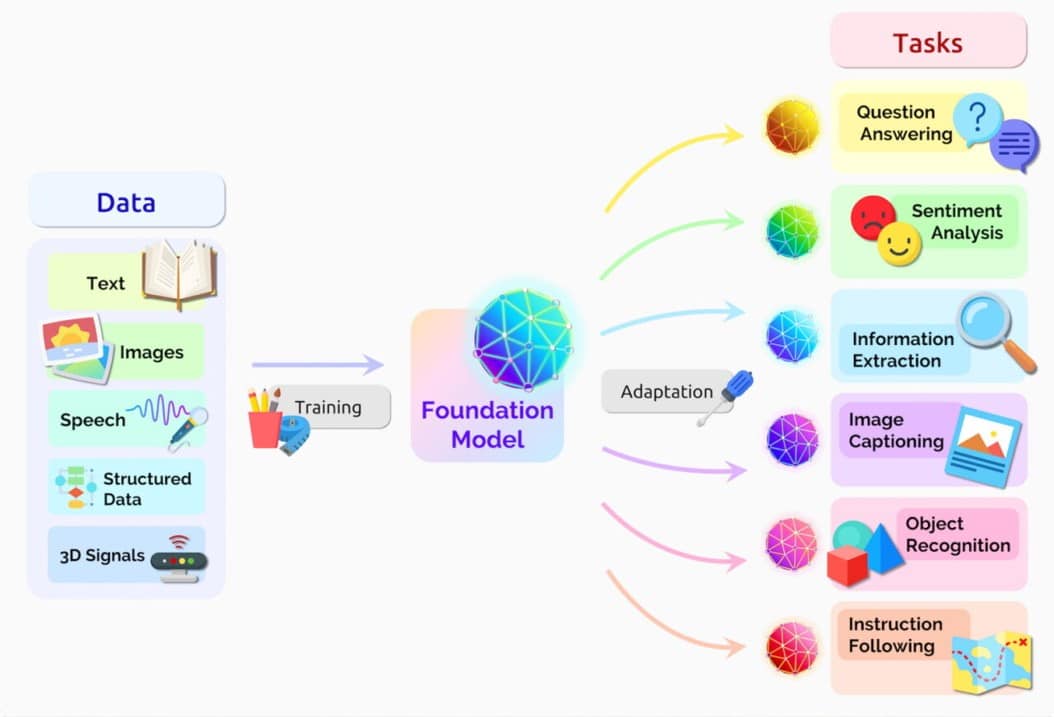
파운데이션 모델은 심층적인 지식 기반과 자연어 의사소통 능력을 갖추고 있습니다. 이는 텍스트 생성과 요약, 코파일럿 제작과 컴퓨터 코드 분석, 이미지와 비디오 제작, 오디오 변환과 음성 합성 등 광범위한 애플리케이션에 유용하게 활용될 수 있습니다.
가장 주목할 만한 생성형 AI 애플리케이션 중 하나인 챗GPT(ChatGPT)는 오픈AI(OpenAI)의 GPT 파운데이션 모델로 구축된 챗봇입니다. 현재 네 번째 버전인 GPT-4는 텍스트나 이미지를 수집하고 텍스트 또는 이미지를 생성할 수 있는 대규모 멀티모달 모델입니다.
파운데이션 모델을 기반으로 구축된 온라인 앱은 일반적으로 데이터센터에서 해당 모델에 액세스하게 되는데요. 이제 이러한 모델과 해당 모델에서 구동되는 애플리케이션의 상당수는 NVIDIA GeForce와 NVIDIA RTX GPU가 탑재된 PC와 워크스테이션에서 로컬로 실행할 수 있습니다.
파운데이션 모델 사용 사례
파운데이션 모델은 다음과 같은 다양한 기능을 수행할 수 있다:
- 언어 처리: 텍스트 이해와 생성
- 코드 생성: 다양한 프로그래밍 언어의 컴퓨터 코드 분석과 디버깅
- 시각 처리: 이미지 분석과 생성
- 음성: 텍스트 음성 생성과 음성을 텍스트로 변환
이러한 기능은 그대로 사용하거나 더 정교하게 수정해서 사용할 수 있습니다. 각 생성형 AI에 대해 완전히 새로운 AI 모델을 학습시키는 과정은 비용과 시간이 많이 소요되는데요. 따라서 사용자는 일반적으로 특정한 사용 사례에 맞게 파운데이션 모델을 미세 조정합니다.
사전 훈련된 파운데이션 모델은 검색 증강 생성(RAG, Retrieval-augmented generation)과 같은 프롬프트와 데이터 검색 기술 덕분에 놀라운 성능을 발휘합니다. 또한 파운데이션 모델은 전이 학습에 탁월하므로 본래의 목적과 관련된 다른 작업을 수행하도록 훈련할 수도 있습니다.
예를 들어, 사람과 대화하도록 설계된 범용 거대 언어 모델(LLM, large language models)은 기업 지식 기반을 사용해 질문에 답변할 수 있는 고객 서비스 챗봇으로 작동하도록 추가 훈련시킬 수 있습니다.
다양한 산업 분야의 기업들은 AI 애플리케이션에서 최상의 성능을 얻기 위해 파운데이션 모델을 미세 조정하고 있습니다.
파운데이션 모델의 유형
현재 100개 이상의 파운데이션 모델이 사용되고 있으며, 그 수는 계속 증가하고 있습니다. LLM과 이미지 생성기는 가장 인기 있는 두 가지 유형의 파운데이션 모델이죠. 그리고 이 중 다수는 NVIDIA API 카탈로그에서 누구든지 모든 하드웨어에서 무료로 사용해 볼 수 있습니다.
LLM은 자연어를 이해하고 쿼리에 응답할 수 있는 모델입니다. 텍스트 이해, 변환, 코드 생성에 탁월한 구글(Google) 젬마(Gemma)가 대표적인 예시죠. 젬마는 천문학자 코넬리우스 젬마(Cornelius Gemma)에 대한 질문에 “천문 항법 그리고 천문학에 대한 그의 공헌은 과학 발전에 큰 영향을 미쳤다”고 설명했습니다. 또한 그의 주요 업적, 유산 그리고 기타 사실에 대한 정보도 제공했습니다.
RTX GPU의 NVIDIA TensorRT-LLM으로 가속화된 젬마 모델의 협업을 확장한 구글의 코드젬마(CodeGemma)는 커뮤니티에 강력하면서도 가벼운 코딩 기능을 제공합니다. 코드젬마 모델은 코드 완성과 코드 생성 작업에 특화된 7B와 2B 사전 훈련된 버전으로 사용할 수 있습니다.
미스트랄 AI(Mistral AI)의 미스트랄 LLM은 명령을 따르고 요청을 완수하며 창의적인 텍스트를 생성할 수 있습니다.
메타(Meta)의 라마2(Llama 2)는 프롬프트에 응답해 텍스트와 코드를 생성하는 최첨단 LLM입니다.
미스트랄과 라마2는 RTX PC와 워크스테이션에서 실행되는 NVIDIA ChatRTX 기술 데모에서 사용할 수 있습니다. 챗RTX를 통해 사용자는 문서, 의사의 진단서, 기타 데이터와 같은 개인 콘텐츠에 RAG을 통해 연결함으로써 이러한 파운데이션 모델을 개인화할 수 있습니다. TensorRT-LLM으로 가속화돼 상황에 맞는 답변을 빠르게 얻을 수 있죠. 또한 로컬에서 실행되므로 결과를 빠르고 안전하게 얻을 수 있습니다.
스태빌리티 AI(Stability AI)의 스테이블 디뷰전 XL(Stable Diffusion XL), SDXL 터보(SDXL Turbo)와 같은 이미지 생성기를 사용하면 놀랍고 사실적인 비주얼을 생성할 수 있습니다. 스태빌리티 AI의 비디오 생성기인 스테이블 비디오 디퓨전(Stable Video Diffusion)은 생성형 확산 모델을 사용해 단일 이미지를 컨디셔닝 프레임으로 삼아 비디오 장면을 합성합니다.
멀티모달 파운데이션 모델은 텍스트와 이미지 등 두 가지 이상의 데이터 유형을 동시에 처리해 보다 정교한 결과물을 생성할 수 있습니다.
멀티모달 모델은 텍스트와 이미지를 모두 지원하기 때문에 사용자가 이미지를 업로드하고 이에 대해 질문할 수 있게 해줍니다. 이러한 유형의 모델은 고객 서비스와 같은 실제 애플리케이션에 빠르게 적용되고 있으며, 기존 매뉴얼을 보다 빠르고 사용자 친화적인 버전으로 대체할 수 있습니다.
코스모스 2(Kosmos 2)는 이미지의 시각적 요소를 이해하고 추론하도록 설계된 마이크로소프트(Microsoft)의 획기적인 멀티모달 모델입니다.
글로벌하게 생각하고, 로컬로 AI 모델 실행하기
GeForce RTX와 NVIDIA RTX GPU는 파운데이션 모델을 로컬에서 실행할 수 있습니다. 그 덕분에 빠르고 안전하게 결과를 얻을 수 있죠.
사용자는 클라우드 기반 서비스에 의존하는 대신 ChatRTX와 같은 앱을 활용해 제3자와 데이터를 공유하거나 인터넷에 연결할 필요 없이 로컬 PC에서 민감한 데이터를 처리할 수 있습니다.
사용자는 빠르게 증가하는 개방형 파운데이션 모델 카탈로그 중에서 자신의 하드웨어에서 다운로드하고 실행할 모델을 선택할 수 있습니다. 이렇게 하면 클라우드 기반 앱과 API를 사용할 때보다 비용이 절감되고 지연 시간과 네트워크 연결 문제가 발생하지 않습니다.
생성형 AI는 게임, 화상 회의 등 모든 종류의 인터랙티브 경험을 혁신하고 있습니다. AI Decoded 뉴스레터를 구독하고 새로운 소식을 받아보세요.