
최근 구글(Google)의 TPU 보고서는 인공지능(AI)이 가속 컴퓨팅 없이 확장하는 것은 불가능하다는 명백한 결론을 제시했습니다.
오늘날 경제는 전 세계 데이터센터 내에서 돌아가고 있으며 데이터센터는 크게 변화하고 있습니다. 얼마 전까지만 해도, 데이터센터는 웹 페이지, 광고 및 동영상 콘텐츠를 제공하는 수준의 서비스만을 제공했는데요. 이제 데이터센터는 음성을 인식하고, 동영상 스트림 내 이미지를 감지하며, 사용자가 필요할 때 정확한 정보를 제공해 사람들을 연결합니다.
이러한 기능들은 딥 러닝이라고 일컬어지는 인공지능의 한 형태 덕분에 가능했는데요. 딥 러닝은 방대한 양의 데이터로부터 언어를 번역하고, 암을 진단하고, 자율주행차를 운전할 수 있도록 교육시키는 것과 같은 여러 과업들을 해결하는 소프트웨어 개발에 이르기까지 학습하는 알고리즘입니다. 인공지능이 가져온 이와 같은 변화는 이전 산업에서는 볼 수 없었던 속도로 가속화되고 있습니다.
딥 러닝의 권위자인 제프리 힌튼(Geoffrey Hinton)은 최근 미국의 유력 주간지, 뉴요커(The New Yorker)를 통해 “어떤 오래된 분류 문제도, 충분한 데이터를 가지고 있다면 딥 러닝으로 해결할 수 있습니다. 향후 딥 러닝을 활용한 수천 가지 애플리케이션이 생겨날 테니까요.”라고 말했습니다.
믿을 수 없을 만큼 효과적인 결과들
구글의 경우를 볼까요? 딥 러닝에 획기적인 작업을 적용한 결과, 구글 나우(Google Now) 서비스는 놀라울 만한 정확성을 보여주게 되었고, 세계에서 가장 위대한 바둑 선수를 상대로 기념비적인 승리를 거두었으며, 구글 번역은 100가지의 서로 다른 언어를 처리할 수 있게 되었습니다.
딥 러닝은 믿을 수 없을 만큼 효과적인 결과물들을 이루어냈습니다. 다만 이와 같은 접근들은 무어의 법칙이 느려지는 시점에서 컴퓨터가 방대한 양의 데이터를 처리할 것을 요구하고 있는데요. 딥 러닝은 새로운 컴퓨팅 아키텍처 발명에 필수적인 새로운 컴퓨팅 모델입니다.
엔비디아는 AI 컴퓨팅 모델의 변화하는 아키텍처를 오랫동안 사용해왔습니다. 2010년, 유르겐 슈미트후버(Juergen Schmidhuber) 교수의 스위스 AI 연구소(Swiss AI Lab) 소속 연구원인 댄 크리슨(Dan Ciresan)은 엔비디아 GPU를 사용해 딥 뉴럴 네트워크를 트레이닝하여 CPU보다 50배 빠른 속도를 달성할 수 있다는 사실을 발견했습니다. 1년 후, 슈미트후버의 연구소는 GPU를 사용해서 최초의 완전한 딥 뉴럴 네트워크를 개발했습니다. 이 딥 뉴럴 네트워크는 손글씨 인식 및 컴퓨터 비전 분야의 국제 경연 대회에서 우승을 차지하기도 했습니다. .
그 후, 2012년 토론토 대학 대학원생이었던 알렉스 크리제브스키(Alex Krizhevsky)는 GPU 한 쌍을 사용해서 이제는 유명한 이미지넷(ImageNet) 대용량 이미지 인식대회에서 우승을 차지했습니다. (슈미트후버는 현대 컴퓨터 비전에 있어서 GPU 딥 러닝의 영향력에 대해 포괄적인 역사를 집대성했습니다.)
딥 러닝에 최적화
전 세계 인공지능 연구원들은 엔비디아가 컴퓨터 그래픽 및 슈퍼컴퓨팅 애플리케이션을 선도하기 위해 개발한 GPU 가속 컴퓨팅 모델이 딥 러닝에 이상적이라는 것을 발견했습니다. 3D 그래픽, 의료 이미징, 분자 역학, 양자 화학 및 기상 시뮬레이션과 같은 딥 러닝은 텐서, 또는 다차원 벡터를 대량으로 병렬 연산하는 선형 대수학 알고리즘입니다. 2009년에 제작된 엔비디아의 케플러(Kepler) 세대 GPU가 딥 러닝에서 GPU 가속 컴퓨팅을 사용할 수 있다는 가능성을 전 세계에 알렸지만 당시에는 구체적으로 그 작업에 대해 최적화된 적은 없었습니다.
엔비디아는 새로운 세대의 GPU 아키텍처 개발에 착수했지요. 처음에는 맥스웰(Maxwell), 그 후에는 특히 딥 러닝에 있어서 많은 아키텍처 진보를 이룬 파스칼(Pascal)이었습니다. 케플러 기반 테슬라 K80(Tesla K80)이 출시된 지 4년 만에 도입된 파스칼 기반의 테슬라 P40 추론 가속기(Tesla P40 Inferencing Accelerator)는 26배의 딥 러닝 추론 작업 성능을 제공합니다. 이것은 무어의 법칙을 훨씬 뛰어넘는 수준이지요.
이 기간 동안 구글은 2015년에 배포한 추론을 처리하기 위해 텐서 프로세싱 유닛(Tensor Processing Unit), 혹은 TPU라고 하는 커스텀 가속기 칩을 고안했습니다.
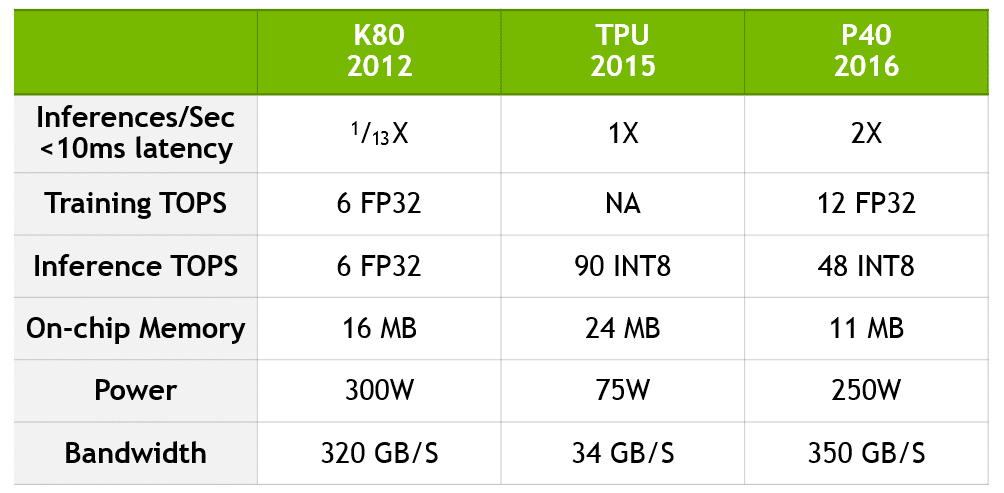
구글의 담당 팀은 지난 주에 TPU의 강점에 대한 기술 정보를 발표했는데요. TPU가 K80 추론 성능의 13배의 성능을 낸다는 사실을 강조합니다. 하지만 발표 중에 TPU를 현재 세대인 파스칼 기반 P40과 비교하지는 않았지요.
구글의 비교에 대한 업데이트
구글의 비교를 업데이트하기 위해 엔비디아는 K80에서 P40으로 성능 도약을 계량화하고, TPU가 현재의 엔비디아 기술과 어떻게 비교될 수 있는지 제시하는 아래 차트를 만들었습니다.
P40은 연산 정밀도, 처리량, 온칩 메모리와 메모리 대역폭의 균형을 유지함으로써 추론뿐만 아니라 트레이닝 방면에서도 전례 없는 성능을 발휘합니다. 트레이닝 용으로 쓰일 때, P40는 10배의 대역폭을 가지며, 32비트 부동소수점 성능의 12테라플롭스를 구현합니다. 추론용으로 쓰일 때, P40은 처리량이 많은 8비트 정수 및 높은 메모리 대역폭을 제공합니다.
구글과 엔비디아는 서로 다른 개발 방법을 선택했지만 두 회사의 접근 방식에는 몇 가지 공통적인 주제가 있다는 것을 확인할 수 있었는데요. 구체적으로 정리하자면 다음과 같습니다.
- 인공지능은 가속 컴퓨팅이 필요합니다. 무어의 법칙이 느려지는 시대에 성장하고 있는 딥 러닝에 대한 수요를 충족시키기 위해서 가속기는 중요한 데이터 처리 기능을 제공합니다.
- 텐서 프로세싱은 딥 러닝 트레이닝 및 추론을 위한 성능의 핵심입니다.
- 텐서 프로세싱은 현재 데이터센터를 구축할 때 기업이 중요하게 고려해야 하는 새로운 워크로드입니다.
- 텐서 프로세싱을 가속화하면, 데이터센터의 구축 비용을 크게 줄일 수 있습니다.
기술 세계는 이미 인공지능 혁명이라고 불리는 역사적인 변화의 한가운데에 있습니다. 그 영향은 알리바바, 아마존, 바이두, 페이스북, 구글, IBM, 마이크로소프트, 텐센트와 같은 하이퍼스케일 데이터센터에서 가장 명백합니다. CPU 노드가 있는 새로운 데이터센터를 짓거나 전력을 투입하는 데 수십억 달러를 쓰지 않고, 인공지능 작업 능력을 가속화해야 합니다. 가속 컴퓨팅이 없으면 인공지능의 확장은 절대 실현될 수 없습니다.
GPU 가속 컴퓨팅은 딥 러닝을 가능케 하고, 현대 인공지능의 발전을 야기했습니다. 캘리포니아 산호세에서 5월 8부터 11일까지 개최되는 GPU 테크놀로지 컨퍼런스 (GPU Technology Conference)에 참여하세요. 인공지능의 선구자들이 이루어낸 혁신적인 발견에 대해서 직접 듣고, GPU 컴퓨팅의 최신 기술과 업계에 혁신을 불러 일으키는 방법을 탐색할 수 있습니다.