아흐메드 엘내거(Ahmed Elnaggar)와 마이클 하인징거(Michael Heinzinger) 연구원은 이 블로그를 보고 계신 여러분이 이 문장을 아주 쉽게 읽을 수 있는 것처럼 컴퓨터가 단백질을 쉽게 읽어낼 수 있도록 연구에 매진하고 있습니다.
두 사람은 텍스트를 이해하는 데 사용되는 최신 AI 모델을 생물정보학 분야에 적용하고 있는데요. 이 연구는 코로나바이러스 같은 살아있는 유기체의 특성 분석을 가속화할 수 있죠.
엘내거와 하인징거의 목표는 올해 말까지 연구원들이 단백질을 결정짓는 일련의 아미노산에 대한 정보를 공유할 수 있는 웹사이트를 개설하는 것인데요. 웹사이트가 완성되면 코로나19을 약물로 치료하는 방법을 파악할 수 있는 핵심 요소인 단백질의 3D 구조에 대한 세부정보를 수초만에 알 수 있을 것입니다
현재 연구진들은 보통 데이터베이스 검색을 통해 이런 종류의 정보를 수집합니다. 하지만 데이터베이스는 단백질의 서열 횟수가 늘어날 수록 증가하기 때문에 단백질 아미노산 규모에 따라 달라지겠지만 AI을 사용하는 경우와 비교하면 검색에 소요되는 시간이 최대 100배까지 늘어날 수 있죠.
새롭게 발견된 단백질의 경우에는 데이터베이스 검색으로 유용한 결과를 도출할 순 없지만, AI 기술을 사용하면 상황은 달라집니다.
컴퓨팅 생물학과 생물정보학에서 박사과정을 밟고 있는 하인징거 연구원은 “코로나19와 관련한 14개의 단백질 중 12개는 이미 충분히 검증된 단백질과 비슷합니다. 그러나 나머지 단백질 두개에 대한 데이터는 거의 없습니다. 이 경우에 AI 모델을 사용하면 굉장히 도움이 많이 됩니다”라고 말합니다.
데이터베이스 검색은 많은 시간이 소요되는 방법이지만 전에 사용하던 AI 방식과 비교하면 정확도가 7~8% 높습니다. 하지만 엘내거와 하인징거 연구원이 최신 모델과 데이터세트를 활용해 데이터베이스 검색과 AI 방식 간 정확도 격차를 절반으로 줄이면서 AI 기술 도입에 물꼬를 트게 됐죠.
생물학적 통찰력을 선도하는 AI 모델과 GPU
하인징거는 “AI 알고리즘 성능이 향상되고 있는 속도를 보면 정확도 격차를 곧 해소할 수 있겠다는 확신이 듭니다. 컴퓨팅 생물학만큼 데이터세트가 빠르게 늘고 있는 분야가 없죠. 이 두가지를 종합적으로 고려해보면 곧 한 차원 높아진 최첨단 기술이 도래할 것 같습니다”라고 말했습니다.
전이 학습(transfer learning) 분야 박사학위를 획득한 AI 전문가 엘내거는 “이런 연구는 2년 전만해도 불가능했을 겁니다. 현재의 생물정보학 데이터, 새로운 AI 알고리즘, 엔비디아 GPU 기반 고성능 컴퓨팅을 통합해 사용하지 않았다면 불가능한 일이죠”라고 말했습니다.
엘내거와 하인징거는 AI와 생물학이 결합된 이 새로운 분야를 개척하는데 큰 도움이 된 뮌헨 공과대학(Technical University of Munich)의 로스트랩(Rostlab) 연구소 소속입니다. 버르크하드 로스트(Burkhard Rost) 연구소장은 1993년 새로운 연구 방향을 확립한 중요한 논문을 썼습니다.
단백질을 ‘읽다’
로스트 연구소장의 논문의 핵심 개념은 간단했습니다. 마치 단어가 문장 안에 나열돼 있듯이, 생명의 구성단위인 단백질도 순차적으로 해석할 필요가 있는 아미노산으로 이루어져 있다는 것입니다.
따라서 로스트 연구소장처럼 연구진은 단백질을 이해하기 위해 자연어 처리를 새로운 작업에 적용했습니다. 그러나 1990년대에는 단백질에 대한 데이터가 적었을 뿐더러 AI 모델이 여전히 걸음마 단계였죠.
지금까지 이 분야는 빠른 속도로 발전했고 많은 변화가 있었습니다.
서열분석(sequencing)은 상대적으로 시간 소요와 비용이 적게 들면서 대량의 데이터세트를 생성해냈습니다. 현대화된 GPU 덕분에 버트(BERT)와 같은 고도로 진화된 AI 모델이 어떤 경우에는 인간보다도 언어를 더 잘 해석할 수 있게 됐죠.
AI 모델 완성도 ‘6배’ 향상
자연어 처리에서 혁신적인 발전의 속도는 특히 눈이 부실 정돕니다. 단 18개월 전만해도 엘내거와 하인징거는 반복 신경망 모델 버전을 9,000만 매개변수로 사용하며 연구했다고 밝혔는데, 이번 달엔 무려 5억 6,700만 매개변수로 트랜스포머(Transformer) 모델을 사용했습니다.
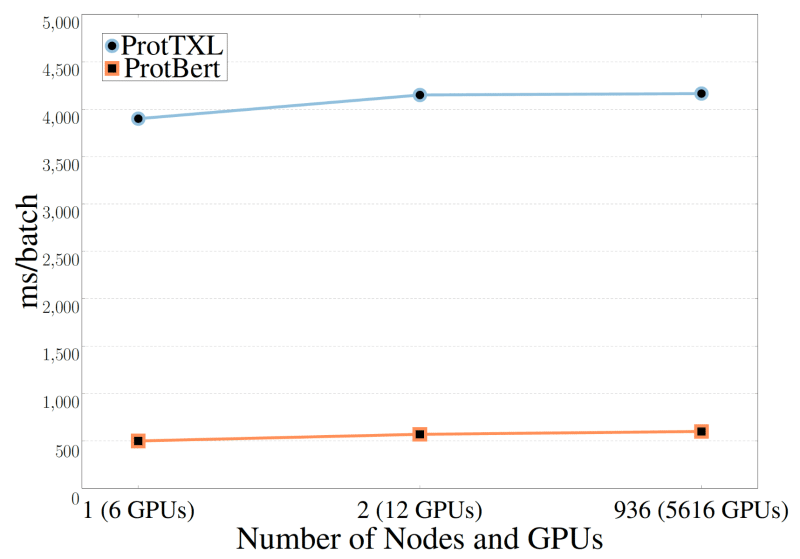
엘내거는 “트랜스포머 모델에는 고성능 컴퓨팅이 필요합니다. 그래서 서밋 슈퍼컴퓨터에서 5,616대의 GPU를 사용할 수 밖에 없었는데, 어떤 모델을 훈련하는 데는 최대 2일이 걸리기도 했죠”라고 말했습니다.
서밋 노드를 수천개 사용해 트랜스포머 모델을 실행하는 데는 여러 어려움이 있었습니다.
엘내거의 이야기는 슈퍼컴퓨터로 작업하는 이들이 흔하게 겪는 일입니다. 엘내거가 파일, 스토리지, 통신, 간접비를 이런 규모로 동기화(syn)하고 관리하는 데 많은 인내심이 필요했는데요. 처음에는 소규모의 노드 몇개로 작업을 시작해 점차 한 단계씩 작업을 발전시켜 나갔죠.
엘내거는 “좋은 소식은 이제 단 한대의 GPU만 있으면 연구실에서 추론 작업을 하는 훈련 모델을 사용할 수 있다는 것입니다”라고 말했습니다.
사전 훈련 AI 모델을 지금 사용해보세요
지난 7월에 발표한 엘내거와 하인징거의 최신 논문에는 다양한 작업에서 사용했던 여러 최신 AI 모델에 대한 장단점의 특징이 수록됐습니다. 이 연구작업은 코로나19 고성능 컴퓨팅 컨소시엄의 기금으로 지원됐습니다.
이 외에도 두 연구원은 사전학습된 모델의 첫번째 버전들을 발표했습니다. 엘내거는 진행 중인 프로젝트가 완성될 때까지 기다리기 보다 “코로나19 사태의 심각성을 고려해서 논문을 일찍 발표하는 것이 낫다고 생각했습니다”라고 밝혔습니다.
하인징거는 “논문에서 제안한 방법들은 단백질 서열분석을 혁신적으로 바꿀 수 있을 겁니다”라고 말했습니다.
이런 연구작업이 코로나바이러스를 단번에 퇴치할 수 없을지도 모르지만, 적어도 앞으로 확산될 바이러스를 방지할 수 있는 더욱 효율적인 새로운 연구 플랫폼을 확립하는 데 도움이 될 것입니다.
컴퓨팅과 생물학, 두 학문의 만남
이번 연구 프로젝트는 과학이 전하는 두 가지 교훈을 보여줍니다. 비전은 항상 미래에 두고 작업은 함께 공유하라는 것입니다.
컴퓨팅 생물학자 하인징거는 “컴퓨터 생물학 분야의 진보는 그 동안 적용했던 자연어 처리 기술이 발전하면서 이루어졌습니다. 이렇게 좋은 아이디어를 다른 유용한 분야에 적용해보는 것이 좋지 않을까요?”라고 말했습니다.
AI 전문가 엘내거도 이에 동의하며 “우리가 성공할 수 있었던 것은 다양한 연구 분야가 서로 협력했기 때문입니다”라고 말했습니다.
여기를 클릭해 코로나19를 해결하기 위해 과학을 진일보시키는 연구원들의 이야기를 더 살펴보세요.
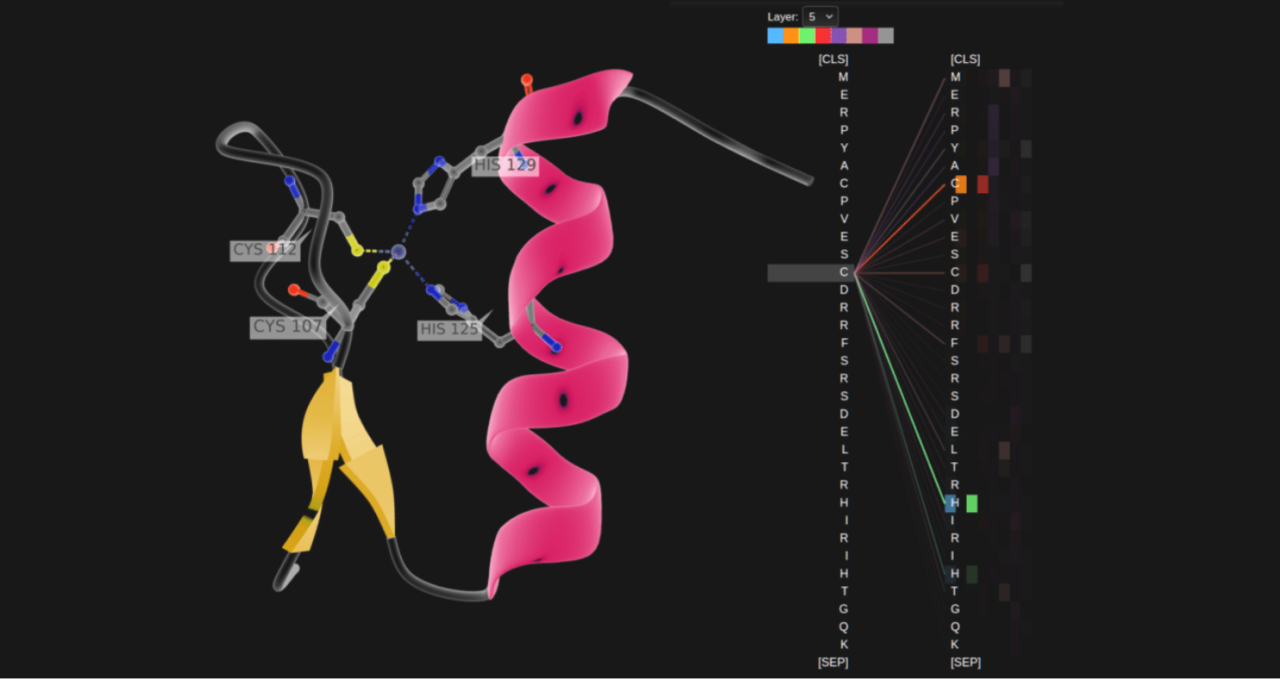
상단의 이미지는 DNA 결합에 필요한 단백질 서열의 신호를 포착하기 위해 라벨링된 샘플 없이 훈련된 언어 모델을 보여줍니다.