
모든 혁신적인 AI 모델은 동일한 출발점에서 시작됩니다. 바로 학습 실행(training run)이죠. 이 학습 작업을 구동하는 인프라가 모든 것을 결정합니다. 팀이 얼마나 빠르게 반복 실험할 수 있는지, 어떤 규모의 모델을 구축할 수 있는지, 그리고 작업이 안정적으로 완료되는지가 모두 인프라에 달려 있습니다.
모델의 크기, 복잡성, 지능이 높아지면서 학습 인프라에 대한 니즈도 함께 높아지고 있는 상황이죠.
AI 학습 성능을 엄격하게 평가하는 산업 벤치마크 시리즈 중 최신판인 MLPerf Training 6.0에서, NVIDIA Blackwell 플랫폼이 전 부문을 선도하며 다음과 같은 성능을 증명했습니다:
- 모든 벤치마크에서 최단 학습 시간 달성
- NVIDIA Blackwell NVL72 시스템으로 8,192개 GPU를 활용한 최대 규모 학습 수행
- 전체 7개 벤치마크에 결과를 제출한 유일한 플랫폼
NVIDIA는 극도로 정밀한 코디자인(codesign)을 통해 설계된 단일 플랫폼에 성능, 규모, 안정성을 결합했습니다. AI 모델 빌더들이 프런티어 모델을 더 빠르게 출시하고, 학습 비용을 최소화하며, 조기에 수익을 창출할 수 있도록 지원하기 위해서죠.
성능: 모든 벤치마크에서 최단 학습 시간
MLPerf Training 6.0에는 두 개의 새로운 MoE(Mixture-of-Experts) 사전 학습 워크로드인 DeepSeek-V3 671B와 GPT-OSS-20B가 추가됐습니다. MoE 아키텍처의 중요성이 갈수록 커지고 있음을 반영한 결과죠. NVIDIA 플랫폼은 전체 7개 벤치마크 모두에 결과를 제출한 유일한 플랫폼이었으며, 모든 항목에서 최단 학습 시간을 기록했습니다.
이번 라운드에서 NVIDIA는 GB200 NVL72와 GB300 NVL72 랙 규모(rack-scale) 시스템 모두에서 결과를 제출했습니다. 각 랙 규모 시스템 내에서 5세대 NVIDIA NVLink 스위치는 72개의 GPU를 고대역폭으로 연결하고, 컴퓨팅과 메모리를 통합 풀로 묶어 하나의 거대한 GPU처럼 동작하게 합니다.
대규모 MoE 학습은 MoE 추론과 동일한 올투올(all-to-all) 통신 과제에 직면하는데요, 토큰이 올바른 전문가 서브네트워크에 도달하기 위해 GPU 전반을 거쳐야 하는데, NVLink의 대역폭 우위가 이 과정을 대규모에서도 빠르고 효율적으로 만들어 줍니다.
NVIDIA는 대규모 및 소규모 사전 학습, 파인튜닝 워크로드 전반에서 엄격한 정확도 요구사항을 충족하면서도 성능을 높이는 NVFP4 학습 방법론도 선보였습니다. NVIDIA는 다양한 모델 아키텍처에서 저정밀도 학습 혁신을 이어가고 있으며, 가장 최근에는 NVFP4를 활용해 5,500억 개의 파라미터를 갖춘 초대형 NVIDIA Nemotron 3 Ultra 모델을 사전 학습하는 데 성공했습니다.
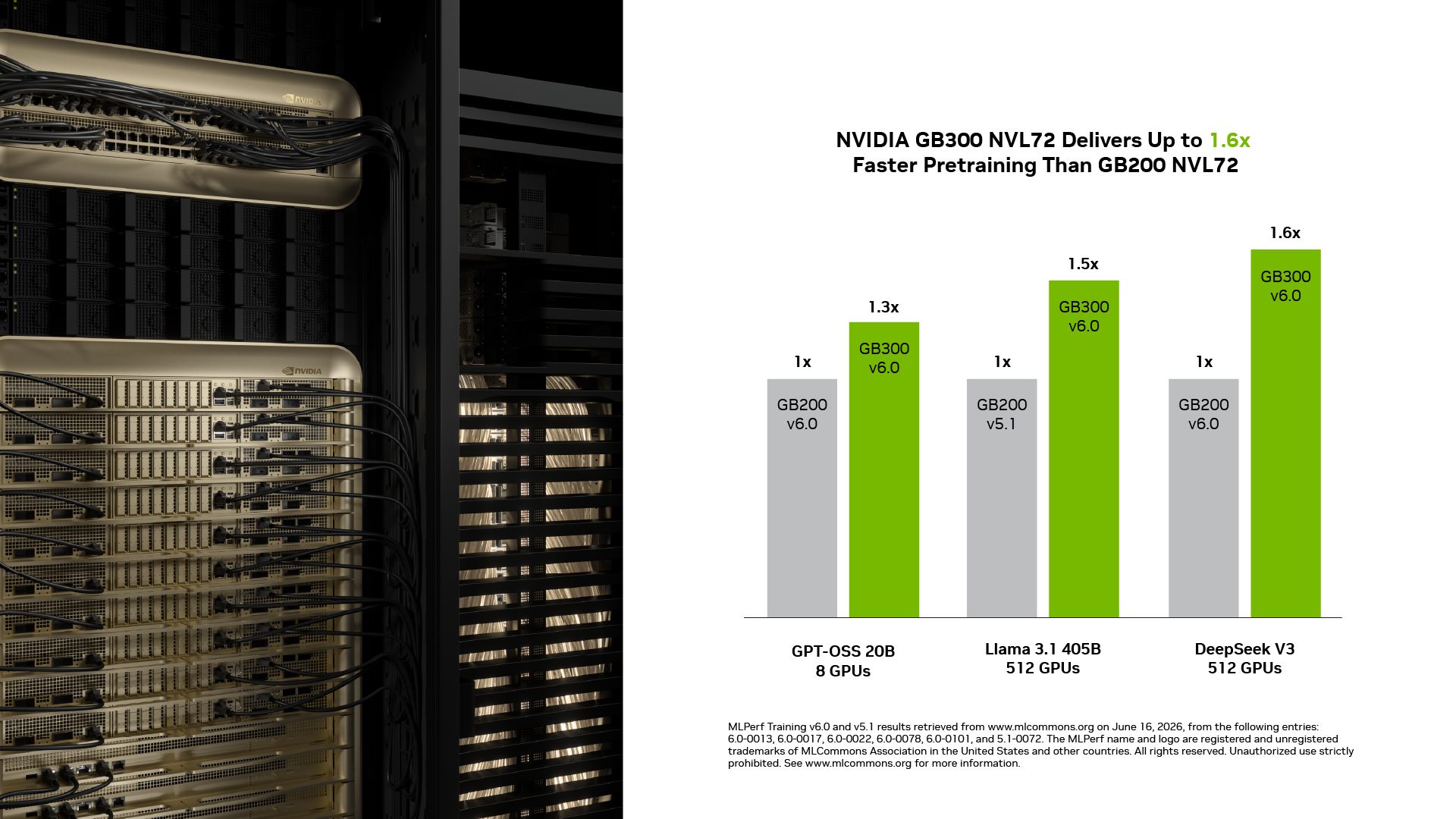
NVIDIA GB300 NVL72, GB200 NVL72 대비 최대 1.6배 성능 향상: 이번 라운드에서 GB300 NVL72는 동일한 규모에서 GB200 NVL72 대비 최대 1.6배 빠른 학습 속도를 기록했습니다. NVFP4를 통한 높은 컴퓨팅 밀도, 확장된 메모리 용량, GPU가 피크 성능을 지속할 수 있게 해주는 높아진 전력 상한 등 Blackwell Ultra의 핵심 기능들이 이 성능 향상을 이끌었습니다.

규모: MLPerf Training 역대 최대 Blackwell 클러스터
대규모 분산 학습을 지원하기 위해 NVIDIA는 NVIDIA Quantum InfiniBand와 NVIDIA Spectrum-X Ethernet이라는 상호 보완적인 두 가지 스케일아웃 네트워킹 플랫폼을 제공하며, 데이터센터가 인프라에 최적화된 대규모 클러스터를 유연하게 구축할 수 있도록 합니다.
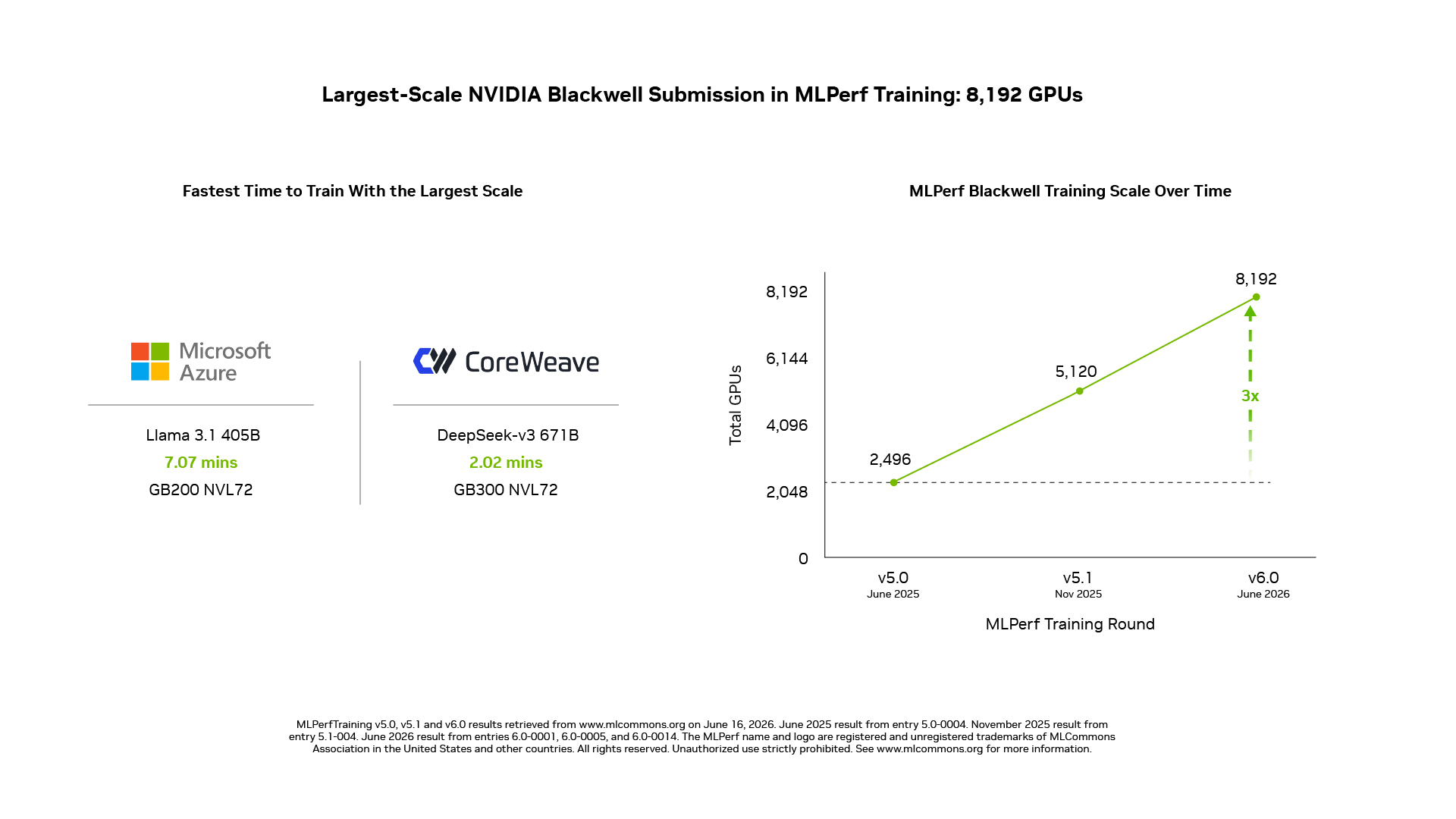
벤치마크 스위트에서 가장 큰 MoE 모델인 DeepSeek-V3 671B에서 NVIDIA는 GB200 NVL72 시스템을 활용해 8,192개의 GPU로 결과를 제출했는데, 이는 MLPerf Training 역대 최대 규모의 Blackwell 기반 제출입니다. NVIDIA는 벤치마크 스위트에서 가장 대형 고밀도 LLM 중 하나인 Llama 3.1 405B에서도 GB200 NVL72 시스템으로 5,120개의 GPU를 활용한 결과를 함께 제출했습니다.
이번 라운드 결과는 시스템 아키텍처, 네트워킹, 소프트웨어 전반에 걸친 NVIDIA와 파트너들의 긴밀한 공동 엔지니어링을 반영합니다:
- Microsoft Azure는 GB200 NVL72 시스템으로 Llama 3.1 405B 학습을 8,192개의 GPU로 확장해 7.07분 만에 기준 품질 목표에 도달했으며, 이는 해당 벤치마크에서 가장 빠른 학습 시간입니다.
- CoreWeave는 Spectrum-X Ethernet 네트워킹으로 연결된 GB300 NVL72 시스템에서 8,192개의 GPU 규모로 2.02분 만에 품질 목표에 도달해 DeepSeek-V3 671B에서 최단 학습 시간을 기록했습니다.
대규모 안정성: 프로덕션을 위한 설계
실제 프로덕션 학습 환경에서는 수십만 개의 GPU를 활용한 작업이 몇 주에서 몇 달에 걸쳐 진행되기도 합니다. 이러한 규모에서 실질적인 학습 처리량은 시스템 성능과 함께, 작업을 시간이 지나도 안정적으로 재현할 수 있는 복원력에 달려 있습니다.
앞서 소개한 MLPerf Training v6.0 결과는 NVIDIA 플랫폼의 성능을 대변합니다. 복원력 측면에서 NVIDIA 플랫폼은 두 가지 차원에서 설계됩니다:
- 더 적은 장애: NVIDIA GPU는 장애가 발생하기 전에 이를 방지하도록 설계됩니다. GPU가 데이터센터에 도달하기 전에 NVIDIA는 30개 이상의 제조 테스트 단계를 통해 잠재적 결함을 조기에 잡아냅니다. 배포된 이후에는 RAS(Reliability, Availability and Serviceability) 엔진이 칩 전체를 모니터링하며, 자가 복구 기능이 감지된 결함을 워크로드 중단 없이 자동으로 우회합니다. 네트워크 레벨에서는 Spectrum-X Ethernet이 밀리초 단위로 장애 링크를 우회해 작업을 중단하지 않고 패브릭을 안정적으로 유지합니다.
- 장애 발생 시 더 빠른 복구: NVRx(NVIDIA Resiliency Extension)는 장애가 실제로 발생했을 때 손실되는 시간을 최소화하며, 클러스터 전반의 장애 감지, 복구, 상태 모니터링 기능을 제공합니다. 성능이 저하된 노드가 나머지 클러스터를 느리게 만들기 전에 이를 자동으로 감지하고 관리합니다. 노드에 장애가 발생할 경우, 전체 작업을 재시작하는 대신 최근 체크포인트(학습 상태의 저장된 스냅샷)에서 작업을 재개합니다.
NVIDIA 위에 구축된 프런티어 AI
이번 라운드에는 NVIDIA 생태계 파트너들도 대거 참여했습니다. ASUSTeK, Microsoft Azure, Cisco, CoreWeave, Dell Technologies, Fujitsu, Giga Computing, Google Cloud, Hewlett Packard Enterprise, Inventec, Krai, Lambda, Nebius, Netweb Technologies India Ltd., Quanta Cloud Computing(QCT), ScitiX, Supermicro, TTA 등 19개 기관이 인상적인 결과를 제출했는데요, 이들 파트너 중 다수는 NVIDIA 인프라에서 가장 까다로운 AI 학습 워크로드를 실행하고 있습니다.
Dell PowerRack 시스템과 Dell PowerEdge 서버로 구성된 NVIDIA 인프라를 보유한 CoreWeave에서는 이러한 워크로드 다수가 실행됩니다. Cohere는 GB200 NVL72에서 자사 North 에이전트형 AI 플랫폼의 학습 속도를 3배 끌어올렸으며, Blackwell 클러스터에서 v8 이미지 생성 모델을 학습한 Midjourney는 현재 CoreWeave 위에서 대규모 Blackwell Ultra GPU를 확장해 차기 이미지 및 비디오 모델을 학습시키고 있습니다.
Google Cloud에서 Thinking Machines Lab은 GB300 NVL72를 활용해 이전 세대 GPU 대비 학습 및 서빙 속도가 2배 빨라지는 것을 확인하며, 프런티어 모델 연구와 강화 학습 워크플로를 가속하고 있습니다.
AI 클라우드에서 NVIDIA Blackwell 및 Blackwell Ultra 인프라를 운영하는 Nebius는 Higgsfield가 모델 학습 시간을 30% 단축할 수 있도록 지원했으며, 현재 2,200만 명의 사용자에게 서비스를 제공하고 하루 600만 건 이상의 AI 콘텐츠를 생성하는 플랫폼을 뒷받침하고 있습니다.
MLPerf Training 6.0 결과와 그 이면의 최적화에 대한 심층적인 기술적 분석은 기술 블로그를 참고하세요.
