
가속 컴퓨팅과 AI의 발전이 전 세계 혁신을 주도하고 있습니다. 이에 따라 양자 컴퓨팅, 신약 개발, 핵융합 에너지 등 인류에 도움이 되는 여러 분야에서 과학 컴퓨팅과 물리학 기반 시뮬레이션이 큰 진전을 이룰 것으로 기대되는데요.
NVIDIA는 지난 3월 GTC에서 NVIDIA Blackwell 플랫폼을 공개했습니다. 이는 NVIDIA Hopper 아키텍처보다 최대 25배 적은 비용과 에너지 소비로 수조 개 파라미터의 거대 언어 모델(large language models, LLM)에서 생성형 AI를 구현할 수 있는 플랫폼입니다.
Blackwell은 AI 워크로드에 강력한 영향력을 발휘할 것으로 예상됩니다. 또한, 기존의 수치 시뮬레이션을 포함한 모든 유형의 과학 컴퓨팅 애플리케이션에서 새로운 발견을 이끌어낼 수 있는 기술력까지 갖추고 있죠.
가속 컴퓨팅과 AI는 에너지 비용을 줄임으로써 지속 가능한 컴퓨팅을 실현합니다. 이미 많은 과학 컴퓨팅 애플리케이션이 이러한 이점을 누리고 있는데요. 예를 들어, 날씨 시뮬레이션은 200배 낮은 비용과 300배 적은 에너지로 구현할 수 있습니다. 디지털 트윈 시뮬레이션의 경우, 기존 CPU 기반 시스템 대비 65배 낮은 비용과 58배 적은 에너지 소비로 구현이 가능하죠.
Blackwell을 통한 과학 컴퓨팅 시뮬레이션 확장
과학 컴퓨팅과 물리학 기반 시뮬레이션은 문제를 해결하기 위해 배정밀도(double-precision) 또는 FP64(부동 소수점)로 알려진 방식에 의존하는 경우가 많습니다. Blackwell GPU는 Hopper보다 30% 더 뛰어난 FP64와 FP32 FMA(fused multiply-add) 성능을 제공합니다.
물리학 기반 시뮬레이션은 제품 설계와 개발에 매우 중요합니다. 비행기와 기차에서 교량, 실리콘 칩, 의약품에 이르기까지 시뮬레이션을 통해 제품을 테스트하고 개선하면 연구자와 개발자는 수십억 달러를 절약할 수 있죠.
오늘날 응용 주문형 집적회로(application-specific integrated circuits, ASICs)는 전압과 전류를 식별하기 위한 아날로그 분석을 포함해 길고 복잡한 워크플로우를 통해 거의 CPU에서만 설계됩니다.
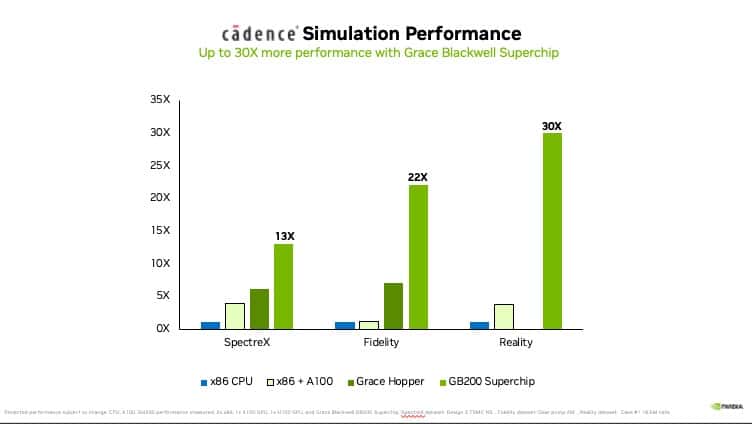
하지만 이제 상황이 바뀌고 있죠. 케이던스 스펙터엑스(Cadence SpectreX) 시뮬레이터는 아날로그 회로 설계 솔버의 한 사례인데요. 스펙터엑스 회로 시뮬레이션은 Blackwell GPU와 Grace CPU를 연결하는 GB200 Grace Blackwell 슈퍼칩에서 기존 CPU보다 13배 더 빠르게 실행될 것으로 예상됩니다.
또한 GPU 가속 전산유체역학(CFD)은 핵심 도구로 자리 잡았는데요. 엔지니어와 장비 설계자는 이를 사용해 설계의 동작을 예측합니다. 케이던스 피델리티(Fidelity)는 기존 CPU 기반 시스템보다 GB200 시스템에서 최대 22배 더 빠르게 실행될 것으로 예상되는 CFD 시뮬레이션을 실행합니다. 병렬 확장성과 GB200 NVL72 랙당 30TB의 메모리를 통해 이전과는 전혀 다른 방식으로 흐름을 세밀하게 파악할 수 있습니다.
또 다른 애플리케이션인 케이던스 리얼리티(Reality)의 디지털 트윈 소프트웨어로는 물리적 데이터센터의 가상 복제본을 생성할 수 있습니다. 여기에는 서버, 냉각 시스템, 전원 공급 장치 등 모든 구성 요소가 포함되죠. 이러한 가상 모델을 통해 엔지니어는 다양한 구성과 시나리오를 실제 환경에 구현하기 전에 테스트함으로써 시간과 비용을 절약할 수 있습니다.
케이던스 리얼리티의 놀라운 기능은 열, 공기 흐름, 전력 사용량이 데이터센터에 미치는 영향을 시뮬레이션할 수 있는 물리학 기반 알고리즘에서 비롯됩니다. 이를 통해 엔지니어와 데이터센터 운영자는 용량을 보다 효과적으로 관리하죠. 또한 잠재적인 운영 문제를 예측하며, 정보에 입각한 결정을 내려 데이터센터의 레이아웃과 운영을 최적화해 효율성과 용량 활용도를 개선할 수 있습니다. Blackwell GPU를 사용하면 이러한 시뮬레이션이 CPU보다 최대 30배 빠르게 실행돼 타임라인이 단축되고 에너지 효율이 높아질 것으로 기대됩니다.
과학 컴퓨팅을 위한 AI
새로운 Blackwell 가속기와 네트워킹은 고급 시뮬레이션을 위한 비약적인 성능을 제공합니다.
NVIDIA GB200은 고성능 컴퓨팅(HPC)의 새로운 시대를 열었습니다. 이 아키텍처는 LLM의 추론 워크로드를 가속화하는 데 최적화된 2세대 트랜스포머 엔진을 탑재하고 있죠.
이를 통해 1.8조 개의 파라미터를 가진 GPT-MoE(generative pretrained transformer-mixture of experts) 모델과 같은 리소스 집약적인 애플리케이션의 속도가 H100 세대 대비 30배 향상돼 HPC의 새로운 가능성을 열어줍니다. LLM이 방대한 양의 과학 데이터를 처리하고 해독할 수 있도록 지원함으로써, HPC 애플리케이션은 과학적 발견을 가속화할 수 있는 유용한 인사이트에 더 빨리 도달할 수 있게 됐습니다.
샌디아 국립 연구소(Sandia National Laboratories)는 병렬 프로그래밍을 위한 LLM 코파일럿을 구축하고 있습니다. 기존 AI는 기본적인 직렬 컴퓨팅 코드를 효율적으로 생성할 수 있지만, HPC 애플리케이션을 위한 병렬 컴퓨팅 코드의 경우 LLM이 불안정할 수 있죠. 샌디아 연구진들은 코코스(Kokkos)라는 프로그래밍 언어로 병렬 코드를 자동으로 생성하는 야심찬 프로젝트를 추진하며, 이 문제를 정면으로 다루고 있습니다. 코코스는 세계에서 가장 강력한 슈퍼컴퓨터에서 수만 개의 프로세서 작업을 실행하기 위해 여러 국립 연구소에서 설계한 전문 프로그래밍 언어입니다.
샌디아 국립 연구소는 정보 검색 기능과 언어 생성 모델을 결합한 검색 증강 생성(retrieval-augmented generation, RAG)이라는 AI 기술을 사용하고 있습니다. 이들은 코코스 데이터베이스를 생성하고 RAG를 사용해 AI 모델과 통합하고 있습니다.
이들의 초기 연구 결과는 매우 유망한데요. 샌디아 국립 연구소의 다양한 RAG 접근 방식은 병렬 컴퓨팅 애플리케이션을 위해 자율적으로 생성된 코코스 코드를 시연했습니다. 이들은 AI 기반 병렬 코드 생성의 장애물을 극복함으로써 전 세계 주요 슈퍼컴퓨팅 시설에서 HPC의 새로운 가능성을 여는 것을 목표로 하고 있습니다. 다른 사례로는 재생 에너지 연구, 기후 과학 그리고 신약 개발 등이 있습니다.

양자 컴퓨팅 발전의 원동력
양자 컴퓨팅은 핵융합 에너지, 기후 연구, 신약 개발 그리고 더 많은 분야에서 타임머신 여행을 가능하게 합니다. 따라서 연구자들은 그 어느 때보다 빠르게 양자 알고리즘을 개발하고 테스트하기 위해 NVIDIA GPU 기반 시스템과 소프트웨어에서 미래의 양자 컴퓨터를 시뮬레이션하는 데 매진하고 있습니다.
NVIDIA CUDA-Q 플랫폼은 CPU, GPU 그리고 양자 처리 장치(quantum processing units, QPU)가 함께 작동하는 통합 프로그래밍 모델을 통해 양자 컴퓨터의 시뮬레이션과 하이브리드 애플리케이션 개발을 모두 지원합니다.
CUDA-Q는 바스프(BASF)의 화학 워크플로우, 스토니 브룩(Stony Brook)의 고에너지와 핵 물리학, 미 국립에너지연구소 과학컴퓨팅센터(NERSC)의 양자 화학 시뮬레이션의 속도를 높이고 있습니다.
NVIDIA Blackwell 아키텍처는 양자 시뮬레이션을 새로운 차원으로 끌어올리는 데 도움이 될 것으로 기대됩니다. 최신 NVIDIA NVLink 멀티노드 인터커넥트 기술을 활용하면 데이터를 더 빠르게 전송해 양자 시뮬레이션의 속도를 높일 수 있습니다.
과학적 혁신을 위한 데이터 분석 가속화
RAPIDS를 사용한 데이터 처리는 과학 컴퓨팅에 널리 사용됩니다. Blackwell은 하드웨어 압축 해제 엔진을 도입해 압축된 데이터를 압축 해제하고 RAPIDS의 분석 속도를 높이죠.
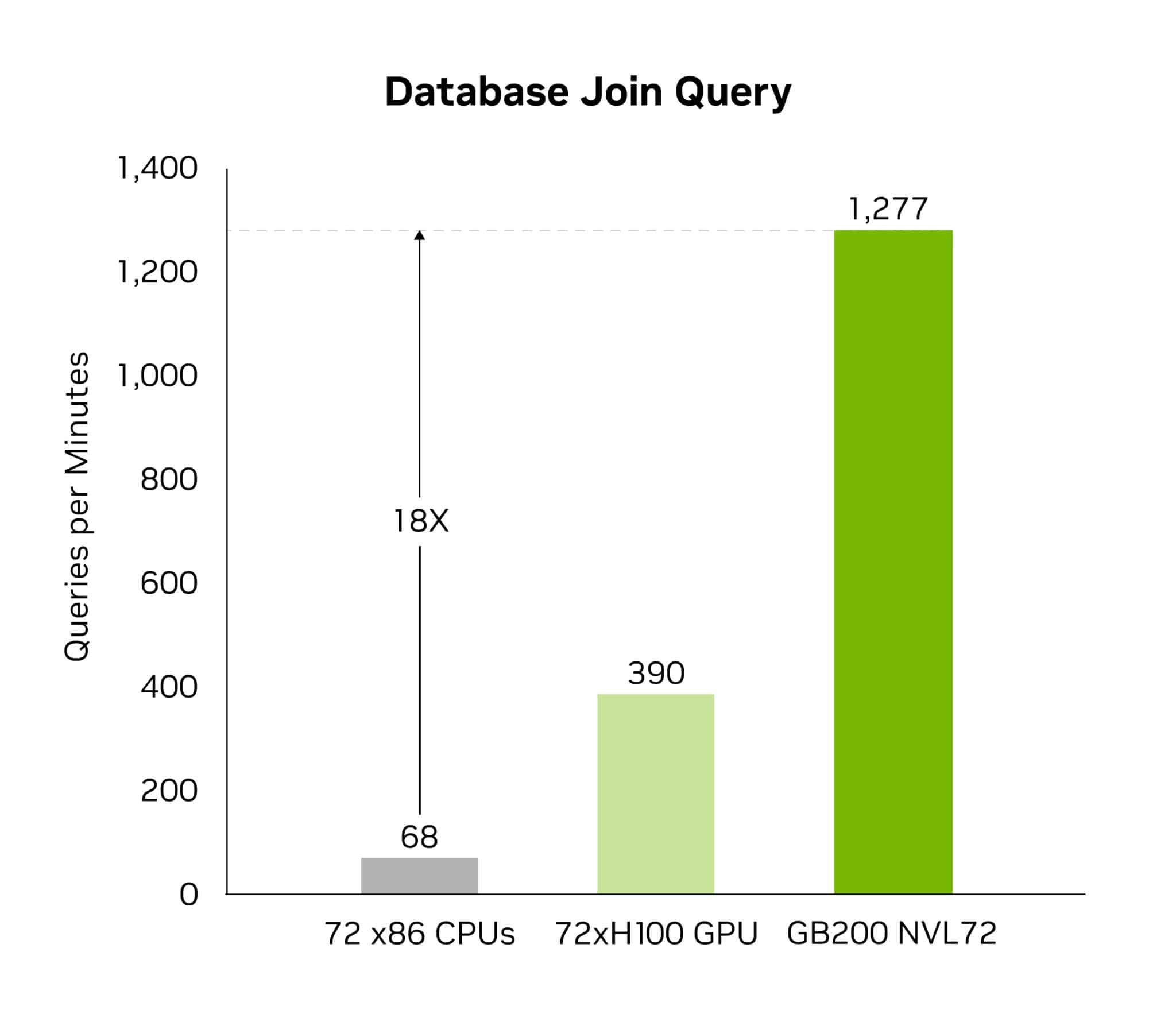
이 압축 해제 엔진은 최대 800GB/s의 성능 향상을 제공합니다. 또한, Sapphire Rapids에서는 CPU보다 18배, 쿼리 벤치마크에서는 NVIDIA H100 Tensor 코어 GPU보다 6배 더 빠른 성능을 발휘할 수 있도록 지원합니다.
이 엔진은 8TB/s의 고용량 메모리 대역폭과 Grace CPU 고속 NVLink 칩투칩(Chip-to-Chip, C2C) 인터커넥트로 데이터 전송을 가속화합니다. 이로써 데이터베이스 쿼리의 전체 프로세스 속도를 높이죠. 데이터 분석과 데이터 사이언스 사용 사례 전반에서 최고 수준의 성능을 제공하는 Blackwell은 데이터 인사이트의 속도를 높이고 비용을 절감합니다.
NVIDIA 네트워킹으로 과학 컴퓨팅을 위한 극한의 성능 구현
NVIDIA Quantum-X800 InfiniBand 네트워킹 플랫폼은 과학 컴퓨팅 인프라를 위한 최고의 처리량을 제공합니다.
여기에는 이전 세대보다 두 배의 대역폭을 제공하는 NVIDIA Quantum Q3400, Q3200 Switch, 그리고 NVIDIA ConnectX-8 SuperNIC가 포함되죠. Q3400 플랫폼은 이전 세대 대비 5배 높은 대역폭 용량과 14.4T플롭의 네트워크 내 컴퓨팅을 제공합니다. 아울러 NVIDIA SHARPv4(scalable hierarchical aggregation and reduction protocol)를 통해 이전 세대 대비 9배 증가된 성능을 제공합니다.
이러한 성능 도약과 전력 효율성은 과학 컴퓨팅의 워크로드 완료 시간과 에너지 소비를 크게 줄여줍니다.
NVIDIA Blackwell에 대해 자세히 알아보세요.