추천 시스템은 사용자의 행위 이력에 기반하여 제품 선호도 예측을 진행합니다. 온라인 상점의 제품 추천, 소셜 미디어의 표적 광고(targeted ads), 영상이나 음악 스트리밍 플랫폼의 사용자 중심 컨텐츠 등에 널리 사용되고 있죠.
이번 글에서는 주피터 노트북에서 샘플용 추천 시스템을 사용하는 방법을 살펴보겠습니다. 이 모델은 영화 평점 예측과 영화 추천을 수행합니다.
추천 시스템
여기에 소개된 변분 오토인코더(Variational Autoencoder)는 협업 필터링 (Collaborative Filtering)을 기반으로 최적화된 모델로 실제 실제 추천 업무에도 사용이 가능합니다. 주피터 노트북에서 VAE 모델의 훈련과 검증 프로세스를 확인할 수 있는데요. 해당 모델은 인코더와 디코더의 두 부분으로 구성됩니다. 인코더는 특정 사용자에 대한 인터랙션을 포함한 벡터를 n차원의 변수로 변환합니다. 이 변수를 통해 사용자의 잠재적 특징을 도출할 수 있습니다. 또한 이러한 특징을 디코더에 입력하면 특정 사용자의 아이템 인터랙션 확률을 보여주는 벡터를 얻을 수 있습니다.
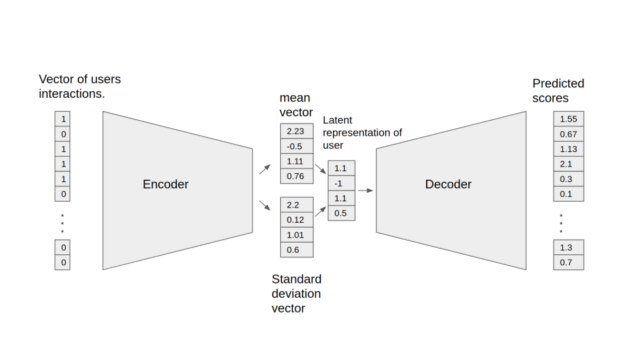
해당 모델은 다음의 기능을 지원합니다.
- 희소행렬(Sparse matrix) 지원
- 데이터 병렬 처리 방식의 다중 GPU를 활용한 훈련
- 텐서 코어(혼합정밀도) 훈련 시 백오프(backoff)를 활용한 다이나믹 로스 스케일링(dynamic loss scaling)
- 피처 지원 행렬(Feature support matrix)
튜토리얼의 진행에 앞서 아래 리소스 유무를 확인하세요.
- NVIDIA GPU 기반 시스템
리포지토리 복제
이 모델과 관련한 리소스를 NGC Catalog 리소스 페이지에서 찾으실 수 있습니다. 화면 우측 상단의 메뉴에서 수동으로 다운로드하거나 wget resource 명령을 사용하십시오.
명령 줄 인터페이스(command line interface, CLI)로 리소스를 다운로드하고 압축을 해제하려면 다음의 과정을 수행하십시오.
- mkdir을 사용해 새 폴더를 만듭니다.
- cd를 사용해 새 폴더로 이동합니다.
- wget을 사용해 폴더 내 zip 파일 형태로 리소스를 다운로드합니다.
- unzip을 사용해 zip 파일의 압축을 풉니다.
mkdir VAE cd VAE wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/vae_for_tensorflow/versions/20.06.0/zip -O vae_for_tensorflow_20.06.0.zip unzip vae_for_tensorflow_20.06.0.zip
컨테이너 생성
조금 전 다운로드한 리소스 폴더 내의 Dockerfile을 사용하여 컨테이너를 생성하십시오.
docker build . -t < tagname>
컨테이너에 임의의 이름으로 태그를 지정할 수 있습니다.
docker build . -t vae
컨테이너 실행
컨테이너를 시작하십시오. 그러면 데이터 폴더가 컨테이너에 올라갑니다. 이 폴더에 영화 평점 데이터세트를 다운로드하고 컨테이너의 포트를 8888:8888로 설정하십시오. 향후 이 포트로 컨테이너 내 주피터 노트북에 액세스할 수 있습니다.
docker run -it --rm --runtime=nvidia -v /data/vae-cf:/data -p 8888:8888 vae /bin/bash
데이터세트
이번 글에서 소개하는 모델의 훈련에는 MovieLens 20M 데이터세트를 사용합니다. MovieLens 20M은 2,000만 개의 평점, 2만7,000 편의 영화에 대한 46만5,000개의 태그 애플리케이션으로 구성된 영화 평점용 데이터세트로, 참여 사용자 수는 13만 8,000명에 달합니다. 이 모델의 목표는 영화, 평점 등 기존 사용자들의 세트를 감안해 새로운 영화의 평점을 예측하는 것입니다.
다운로드해둔 데이터세트가 없을 경우 다음의 명령을 실행해 MovieLens 데이터세트를 ‘/data/ml-20m/extracted/폴더’로 다운로드하고 압축을 해제합니다. Docker 컨테이너에서 다음의 명령을 실행해 데이터세트를 전처리할 수 있습니다.
python prepare_dataset.py
해당 데이터세트는 기본적으로 /data 디렉터리에 저장됩니다. 다른 위치에 저장을 원하시면 –data_dir argument형태로 저장하세요.
mkdir /data/ml-20m mkdir /data/ml-20m/extracted wget https://files.grouplens.org/datasets/movielens/ml-20m.zip unzip ml-20m.zip
다른 곳에서 데이터세트의 다운로드와 압축 해제를 진행한 경우 다음의 명령을 실행하여 현재의 VAE-CF Docker 컨테이너를 먼저 종료한 다음 MovieLens 데이터세트 위치를 마운트하여 VAE-CF Docker 컨테이너를 다시 시작하십시오.
exit docker run -it --rm --gpus all -v /data/vae-cf:/data -v <ml-20m folder path>:/data/ml-20m/extracted/ml-20m -p 8888:8888 vae /bin/bash
컨테이너 내 모델 훈련과 검증
컨테이너를 실행했고 컨테이너 내 데이터세트도 준비를 마쳤다면 주피터 노트북을 사용해 나머지 명령을 실행하십시오. 컨테이너의 주피터랩(Jupyterlab) 워크스페이스(workspace)를 엽니다. 다음으로 VAE 모델 노트북을 업로드하고 노트북의 셀들을 실행하여 이 모델상의 추론을 훈련, 검증, 실행합니다.
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
데이터세트 준비
압축을 푼 폴더에 데이터세트를 다운로드한 후 메인 워크스페이스로 돌아가 prepare_dataset.py를 실행하십시오. 이 명령은 MovieLens 20M 데이터세트를 가져오기 한 후 분할하여 훈련, 인증, 검증에 활용될 수 있게 해줍니다.
python prepare_dataset.py
모델 훈련
train argument로 구성된 main.py 스크립트를 실행해 훈련을 시작합니다. 가중치를 비롯해 훈련 마지막에 체크포인트는 –checkpoint_dir 디렉터리 옵션으로 디렉터리에 저장할 수 있습니다.
이에 더해 –results_dir 명령줄 인수(기본값: None)는 훈련 결과로 얻어지는 통계를 JSON 포맷으로 저장할 위치를 지정합니다. 명령줄 인수의 전체 목록은 /args.json으로 저장되며, 훈련 중 기록된 인증∙성능 정보(metrics)의 목록도 함께 저장됩니다.
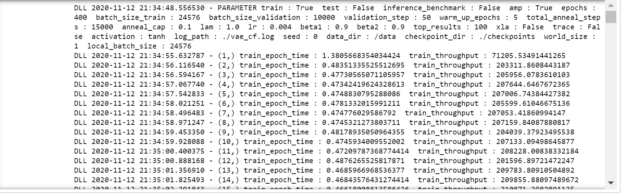
훈련 명령의 실행 시 각 에포크(epoch)별 훈련 과정의 세부 정보를 확인할 수 있습니다. 또한 main.py의 인수를 변경하여 모델의 훈련용 하이퍼파라미터를 바꿀 수도 있습니다. main.py 인수와 관련한 더 자세한 정보는 노트북의 마지막 셀을 참고하십시오.
50에포크마다 추론을 실행하여 모델의 리콜(recall)을 확인합니다. 리콜은 이 모델의 성능을 정확한 전체 평점 대비 정확한 예측 평점의 백분율로 보여주는 메트릭입니다. 참의 양수/참의 양수+거짓의 음수로 표현됩니다.
mpirun --allow-run-as-root -np 1 -H localhost:8 python main.py --train --amp --checkpoint_dir ./checkpoints
Figure 3은 이전 명령 실행의 아웃풋을 보여줍니다.
모델 검증
모델을 기본 위치인 model_dir로 내보내기 한 후 다음 명령을 사용해 로딩과 검증을 진행할 수 있습니다. 훈련된 모델의 가중치는 체크포인트 폴더에 저장되어 있으며, 이를 이용해 새로운 데이터를 검증할 수 있습니다.
이 단계에서는 훈련된 모델의 검증을 위해 따로 마련해둔 데이터를 활용해 모델의 성능을 검사합니다. 리콜 메트릭으로 예측 정확도를 확인할 수도 있습니다.
python main.py --test --amp --checkpoint_dir ./checkpoints
Figure 4는 테스트 명령의 아웃풋(output)을 보여줍니다.
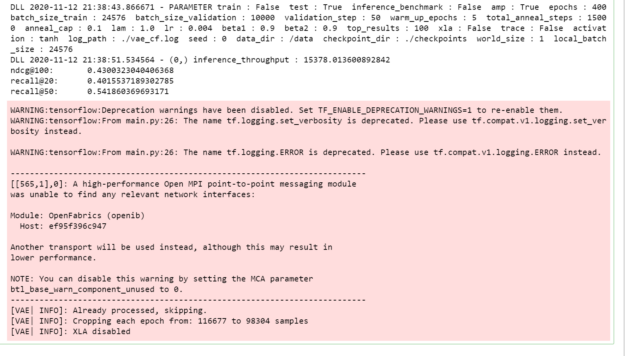
Main.py
이 모델은 기본 하이퍼파라미터와 400에포크짜리 소규모 데이터세트로 훈련되었습니다. 더 큰 데이터세트를 활용하고, 훈련 에포크를 늘리고, 다른 하이퍼파라미터를 사용해 모델의 성능을 개선할 수 있습니다. Main.py –help 명령은 이 특정한 모델을 이용한 작업에서 선택이 가능한 여러 옵션을 보여줍니다. main.py 스크립트는 또한 훈련, 검증, 추론 등 허락되는 모든 기능에의 진입점을 제공합니다. 이 스크립트의 동작은 다음 섹션에 나열된 명령줄 인수들로 제어합니다. prepare_dataset.py 스크립트를 사용하여 MovieLens 20M 데이터세트를 전처리할 수 있습니다.
파라미터
가장 중요한 명령줄 파라미터에는 다음이 포함됩니다.
- –data_dir— 데이터가 저장되는 Docker 컨테이너 내 디렉터리를 지정하여 디폴트 위치/데이터를 오버라이드(override)합니다.
- –checkpoint_dir— 체크포인트의 저장 여부와 위치를 제어합니다.
- –amp— 혼합정밀도(mixed precision) 훈련을 실시합니다.
학습률과 배치 사이즈(batch size) 등 훈련 프로세스의 다양한 하이퍼파라미터를 제어하는 파라미터들도 있습니다. 사용 가능한 옵션의 전체 목록과 설명을 보려면 -h 또는 –help 명령줄 옵션을 사용하십시오.
python main.py --help
Figure 5는 main.py를 실행하는 사용자 지정 옵션을 보여줍니다.

결론
이번 글에서는 VAE 모델을 생성하고 해당 모델에 대한 컨테이너를 생성하는 방법을 살펴봤습니다. 다음으로 주피터 노트북에 컨테이너를 올려 모델의 훈련과 검증을 진행했습니다.
오늘 NGC Catalog에 방문하여 추천 시스템 리소스를 다운로드하고 다양한 사용 사례에 적용해보세요.
NVIDIA GTC는 AI를 학습하고 전문가와 인사이트를 나눌 기회를 제공합니다. 4월 12일부터 16일까지 개최되는 NVIDIA GTC에서 AI, 데이터 센터, 가속 컴퓨팅, 헬스케어, 게임 개발, 네트워킹 등 다양한 분야의 최신 혁신을 확인하세요.