
전통적인 모델링, 시뮬레이션과 데이터 분석을 보완하는 새로운 방법론들과 함께 부상하고 있는 HPC와 AI의 융합은 오늘날 가장 까다로운 과제들을 해결할 수 있게 하고 있습니다. 기획에서부터 맞춤 설계된 구성 요소들을 통합하는 데까지 무려 수 년이 걸리던 인프라는 GPU 가속 기술과 인 네트워크(in-network) 컴퓨팅을 통해 표준화된 요소를 활용, 세계 최고 수준의 슈퍼 컴퓨터를 수 개월 또는 수 주만에 구축할 수 있게 된 것입니다.
오늘은 이러한 GPU 컴퓨팅 기술과 초고속 인터커넥트를 통한 강력한 데이터센터를 어떻게 구축할 수 있는지 소개하도록 하겠습니다.
스케일업 인프라 위한 최고의 아키텍처 개발을 향한 엔비디아의 여정
엔비디아는 자율주행 자동차 컴퓨터 그래픽 알고리즘, AI 연구, 그리고 기타 새로운 AI 응용 프로그램 개발을 위해 2만 개가 넘는 GPU를 사내용으로 구축하여 사용하고 있습니다. 인공지능 벤치마크라고 할 수 있는 MLPerf를 기준으로 엔비디아는 자사 시스템 MLPerf 성능치를 공개한 많은 시스템 제조기업 중 많은 부분에서 최고 성능에 올라섰습니다.
엔비디아는 스케일업 인프라를 위한 최고의 아키텍처 개발을 위해 많은 투자를 해오고 있습니다. 이를 위해선 컴퓨팅 네트워크 스토리지, 프레임워크 수치 계산 방법 등 전체 스택에 걸친 최적화가 필요하죠.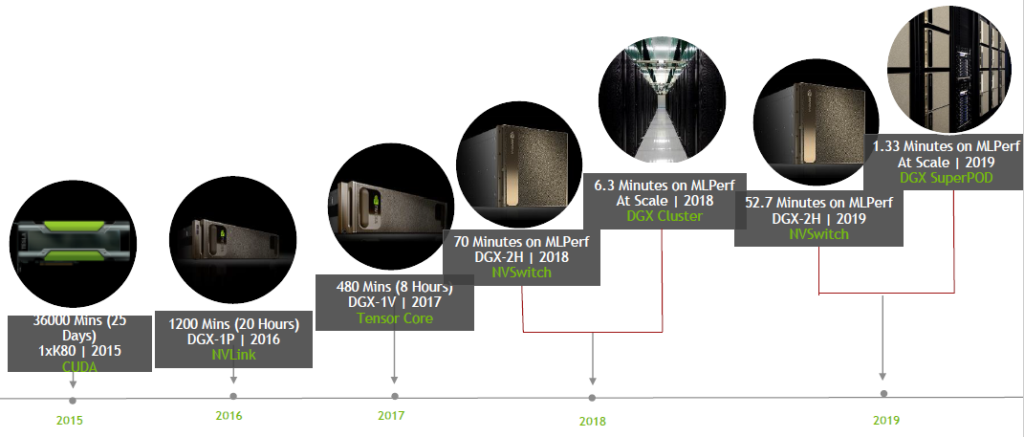
2015년 K80 GPU 하나로 3만 6000분이 걸리던 작업이 2019년에는 DGX SuperPOD를 이용해 1분 20여 초로 줄였듯이, AI 인프라를 구축하는 과정은 GPU 하나가 아닌 큰 전체 시스템에 대한 도전입니다.
네트워크가 복잡해지고 데이터가 많아 짐에 따라 사람들은 더 유연하고 다재 다능하며 다양한 크기의 워크로드를 처리할 수 있는 데이터센터가 필요하다는 것을 알게 됐고, GPU를 적용한 서버를 구축하기 시작했죠. 엔비디아는 GPU를 어떻게 재구성하면 최적의 가속화 데이터센터를 구축할 수 있을지 고민하기 시작했습니다.

혁신적인 GPU를 설계하기 위해 엔비디아가 세운 가이드라인은 이것이었습니다.
- 첫째, 증가하는 워크로드 복잡성에 발맞춰 획기적으로 향상된 컴퓨팅 성능을 확보한다.
- 둘째, 트레이닝과 레퍼런스 솔루션의 역할을 모두 하면서 효율적으로 이러한 작업을 실행할 수 있도록 동적으로 재구성할 수 있어야 한다.
- 마지막으로 셋째, GPU 수를 늘이거나 줄일 수 있는 탄력적인 데이터센터를 구축해야 한다.
그리고 이 고민의 결과가 바로 엔비디아 A100 텐서 코어 GPU입니다.
1.엔비디아 A100 텐서 코어 GPU

전 세대 대비 엄청난 도약
엔비디아 A100 텐서 코어 GPU는 앞 세대 GPU V100 대비 FP32(32비트 부동소수점 연산) 학습과 INT8 추론에서 최대 20배 더 높은 연산 성능을 제공합니다. 또한 새로운 3세대 텐서 코어의 FP64 배정밀도를 추가해여 볼타(Volta)보다 2.5배 더 많은 HPC 연산 성능을 제공합니다.
엔비디아 A100 GPU는 새로운 암페어(Ampere) 아키텍처 기반으로 만들어졌는데요, AI HPC와 데이터 분석에서 더 효과적인 성능을 내도록 새로운 기능들이 추가된 아키텍처죠. 특히 멀티 인스턴스 GPU(Multi-Instance GPU, 이하 MIG) 기능으로 다양한 목적에 적합하면서 높은 처리량을 갖춘 데이터센터를 구축할 수 있는 최초의 탄력적 GPU 아키텍처가 됐습니다.
암페어 아키텍처의 새로운 텐서 코어(Tensor Core)는 AI와 HPC에 사용되는 모든 데이터 유형에 대한 포괄적인 지원을 추가하면서 계산 성능을 크게 향상시키죠.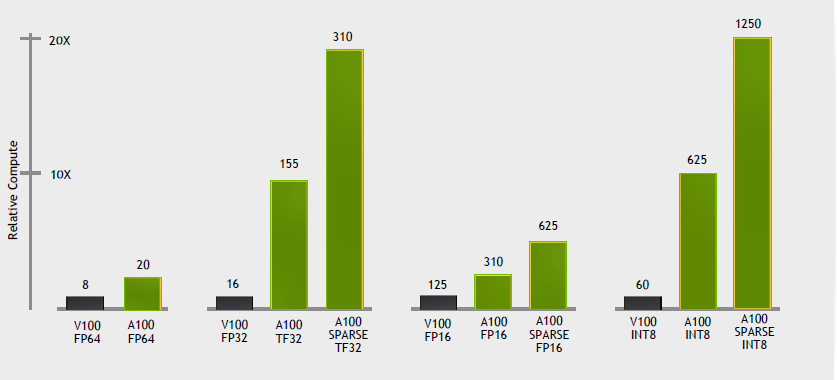
볼타에 비해 개선된 성능은 최대 10배인데요, 여기에 스파시티(Sparsity, 희소성)라는 가속화 기술을 적용하면 처리량은 추가로 2배 증가하며 컴퓨팅 처리량이 볼타 대비 최대 20배까지 향상됩니다.
또한 A100은 3세대 NVLINK 기술과 2세대 NVSWITCH 기술로 거대한 하나의 GPU로 스케일업 할 수 있을 뿐 아니라 인피니밴드(Infiniband) 연결을 통해 스케일아웃도 가능하죠.
‘스파시티’란?
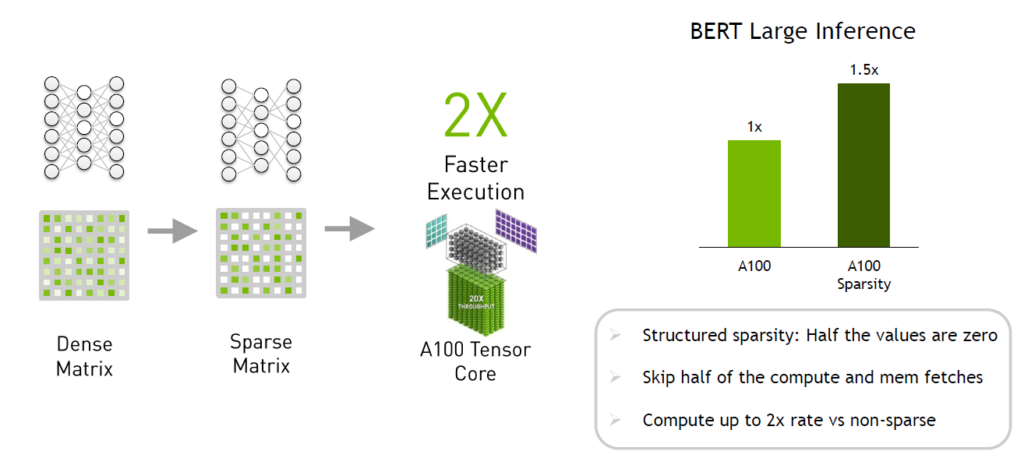
신경망 안에는 네트워크 내의 가중치가 0이거나 거의 0인 것을 뜻하는 희소 데이터가 있는데요. 추론을 할 때 가중치 0은 기본적으로 영향을 미치지 않습니다.
A100에는 희소 네트워크의 행렬을 재정렬 할 수 있는 하드웨어가 내장되어 의미 있는 가중치만이 행렬 연산에 포함되고, 의미 없는 가중치 중 약 절반가량이 계산작업과 메모리 패치 작업에 포함되지 않습니다. 이렇게 하면 이론적으론 최대 2배의 속도 향상을 가져올 수 있습니다.
실제 애플리케이션인 BERT-라지(BERT-Large) 추론을 통해 동일한 정확도를 유지하면서 최대 50%의 성능 향상이 있는 것이 확인된 바 있죠. 이를 통해 경이로운 가속화 서비스를 제공할 수 있습니다.
 멀티 인스턴스 GPU
멀티 인스턴스 GPU
AI 인프라 관련해서 중요한 요소는 ‘평균 시스템 활용시간’인데요, 리소스 활용률을 최대로 높이지 않는다면 데이터센터 구축의 의미가 퇴색되기 때문에 AI 인프라 관리자는 늘 시스템 활용 정도를 모니터링 합니다.
AI 학습 용도로 GPU 서버를 도입하면 최대 수치에 육박하는 높은 사용률을 보입니다. 하지만 학습이 마무리되면 사용 빈도가 크게 줄어들고 GPU 서버는 휴식기에 접어들게 되죠.
그래서 엔비디아가 개발한 것이 바로 MIG(Multi-Instance GPU)입니다. A100 GPU에는 완전히 분리된 7개의 작은 GPU 인스턴스로 분할할 수 있고 각각 고유의 전용 컴퓨팅 리소스, 전용 L2 캐시 및 HBM에 전용 메모리 공간이 있습니다. 이 작업은 모두 하드웨어에서 수행이 되고 각각 다른 작업을 수행하는 여러 컨텍스트를 동시에 실행할 수 있습니다.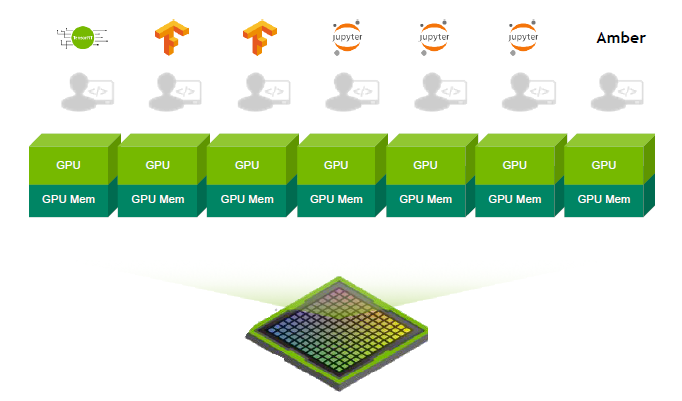
각 MIG 인스턴스는 서로 다른 쿠다 애플리케이션을 독립적으로 실행할 수 있고 인스턴스는 격리된 기능을 갖춘 서비스 퀄리티를 보장합니다. 사용자는 MIG 인스턴스에서 모든 유형의 워크로드를 예측 가능한 처리량과 대기시간 정보와 함께 유연하게 실행할 수 있는 것이죠. 또한 서버를 재부팅 하지 않고도 GPU를 재구성할 수 있습니다.
2.엔비디아 DGX A100
다음은 엔비디아 DGX A100 입니다. DGX A100은 데이터분석, 딥러닝 트레이닝, 인퍼런싱, 어느 종류에 작업이든 규모와 노드에서 관계없이 수행할 수 있는 하나의 시스템인데요, DGX A100에는 8개의 A100 GPU가 연결돼 다른 GPU와 동시 다발적으로 통신할 수 있습니다.
하나의 서버가 스케일업을 통해 응용 프로그램의 처리량을 늘리고 스케일 아웃을 통해 응용 프로그램을 확장할 수 있을 뿐만 아니라 완전히 유연한 시스템을 갖춰 각각의 작업이 독립적으로 수행되는 시스템이죠.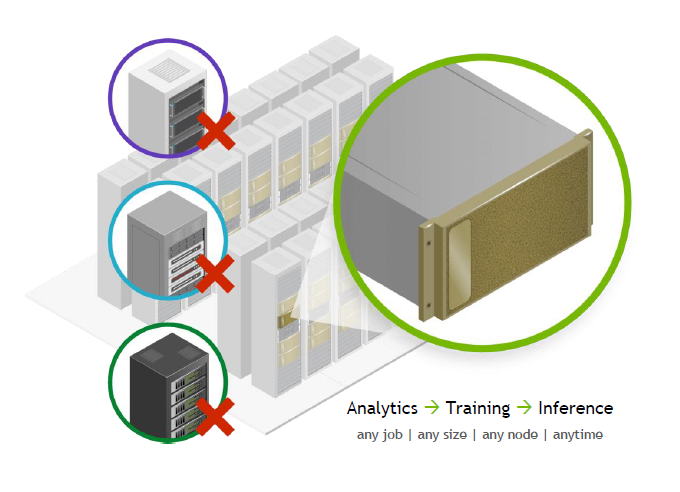
8개 A100 GPU가 있는 단일 서버에서 MIG를 사용하면 최대 56명을 호스팅 할 수도 있습니다.
DGX A100에서 다양한 워크로드를 통합할 수도 있습니다. 예를 들어 훈련에 4개의 GPU를 사용하고 데이터 분석에 두 개의 GPU를 사용한 다음, 나머지 두 개의 GPU를 14개의 MIG 인스턴트로 분할하고 추론을 실행할 수도 있는 거죠. 동일한 시스템 내 각 GPU에서 MIG 기능을 독립적으로 켜고 끌 수도 있습니다.

아르곤국립연구소
DGX A100을 선택한 첫 고객은 미국 에너지국(DOE)의 아르곤국립연구소(Argonne National Laboratory)인데요, 이 곳에서는 새로운 DGX A100 슈퍼컴퓨터의 AI와 컴퓨팅 역량을 이용해 코로나19를 연구, 분석하고 있습니다.

아르곤 클러스터는 24개의 DGX A100으로 구성되어 있으며 총 192개의 A100 GPU가 멜라녹스(Mellanox) 고속 저지연 네트워크 패브릭으로 연결되어 있습니다. 이 곳 연구원들은 120PF의 AI 성능을 제공하는 DGX A100 클러스터를 기반으로 코로나 극복을 위해 열심히 연구하고 있습니다.
3.엔비디아 DGX SuperPOD
AI 연구개발용으로 개발된 세계 최대 인프라
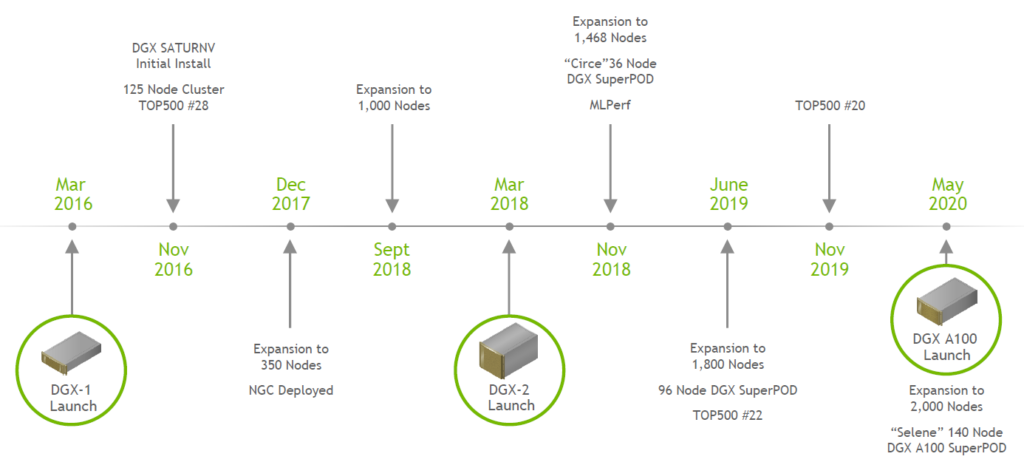
광범위한 딥러닝 워크로드를 지원할 수 있는 시스템을 구축하기 위해 딥러닝 과학자, 애플리케이션 성능 엔지니어, 시스템 설계자가 공동설계 한 DGX SuperPOD 레퍼런스 아키텍처. 여러 대의 DGX 서버와 스토리지 서버를 고속 멜라녹스 커넥터를 통해 연결한 것이 바로 DGX SuperPOD 레퍼런스 아키텍처입니다.
DGX SuperPOD는 획기적인 성능을 제공하고 몇 주만에 온전히 통합된 시스템으로 배포가 가능하며 세계에서 가장 까다로운 계산 문제를 해결하도록 설계됐습니다.
AI 데이터센터에 DGX A100이 도입되면 생기는 변화

위 이미지는 약 1100만 달러 규모에 630kw의 전력이 소비되는 AI 데이터센터 시스템의 모습입니다. 여기에 DGX A100을 도입하면 어떤 변화가 생길까요?
DGX A100을 도입함으로써 1100만 달러의 데이터센터를 1/10 비용인 100만 달러 하나의 랙으로 줄일 수 있고 소비전력도 630KW에서 1/10밖에 되지 않는 28KW으로 줄일 수 있습니다.
DGX A100을 많이 사면 살수록 더 많은 비용을 줄일 수 있는 거죠. 엔비디아 젠슨 황 CEO가 2018년도 CES 기자 회견에서 한 “The more you buy, the more you save”처럼 말입니다.
4.AI 리더십을 위한 가속 RDMA 확장형 인프라
이어서 DGX 시스템을 이용해 AI, 머신 러닝, 그리고 HPC 슈퍼컴퓨팅 환경을 구성할 때 어떻게 네트워크 환경을 구성해야 성능을 극대화하면서 확장성, 안정성을 보장할 수 있을지 알아보겠습니다.
이를 위해서는 기본적으로 인피니밴드라는 기술과 이더넷이라는 기술, 두 가지 데이터 전송 기술을 사용할 수 있습니다. 또한 애플리케이션 성능 극대화를 위해서 RDMA라는 기술을 이용하면 더 높은 성능을 구현할 수 있죠.
그래서 먼저 RDMA 기술이 무엇인지 알아보고, 그 다음 DGX 내부 아키텍처를 한 번 더 네트워크 관점에서 살펴보겠습니다. 마지막으로 네트워크 패브릭을 구성하는 네트워크 디자인에 대해 알아보겠습니다.
올해 4월 말 고성능 인터커넥트 네트워킹 솔루션 기업 멜라녹스(Mellanox Technologies)를 인수하며 엔비디아 네트워킹 사업부가 됐는데요. 멜라녹스는 20여 년간 인피니밴드 솔루션과 그리고 이더넷 솔루션은 약 6년간 글로벌 고객들에게 제공해 온 기업입니다.
현재 전세계 500대 슈퍼컴퓨터 환경 중 1위부터 10위 슈퍼컴퓨터 중 상당수가 인피니밴드 기술을 사용하고 있습니다. 인피니밴드가 분산 병렬 컴퓨팅 환경에 필요한 저지연, 고대역폭의 최적의 네트워크를 제공하기 때문이죠.
현재 사용하는 인피니밴드 기술은 초당 200Gbps의 데이터를 처리할 수 있는 HDR(High Data Rate) 네트워크 인터페이스를 지원하는 규격입니다. 이런 200Gbps HDR 규격 인터페이스를 사용하면 수천에서 수만대의 컴퓨팅 시스템들을 인피니밴드 네트워크 기반으로 하나의 시스템으로 묶어서 사용할 수 있죠.
또한 인피니밴드 기반으로 시스템을 구축하면 애플리케이션 성능을 더욱 향상시킬 수 있는 다양한 네트워크 기술들을 활용할 수 있습니다. 네트워크를 통해 단순히 데이터 패킷을 전달하는 것에서 끝나는 것이 아니라 실제 컴퓨팅 영역에도 참여해 성능을 개선하는 인-네트워크 컴퓨팅(in-network computing)도 구현 가능합니다.
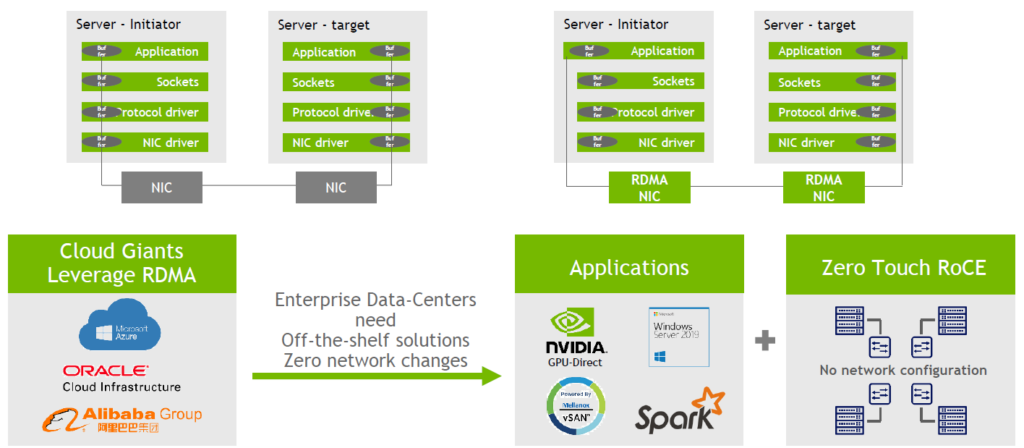
RDMA 기술
RDMA는 Remote Direct Memory Access의 약자인데요. 우선 DMA(Direct Memory Access) 기술을 먼저 설명하면 컴퓨터 주변 장치들이 실질적으로 CPU의 인터럽트(interrupt) 없이 메모리를 직접 접근할 수 있는 기반 기술입니다. RDMA는 이러한 DMA 기술을 단일 시스템 내부뿐만 아니라 리모트 시스템까지 확장해서 적용할 수 있는 기술입니다.
위 이미지에서 왼쪽 그림은 TCP/IP 소켓 기반의 일반적인 데이터통신이 이뤄지는 방식을 설명하고 있는데요, 애플리케이션에서부터 소켓, 프로토콜 드라이버, NIC 드라이버 각각의 계위에 버퍼 카피가 이뤄지고 마지막 NIC 어댑터 카드를 통해서 상대편 시스템으로 데이터를 전송하게 됩니다. 그리고 반대편 시스템은 역순에서 이러한 버퍼 카피를 이뤄내면서 데이터를 전송하는 그림입니다.
이러한 시스템 내부의 여러번의 버퍼 카피가 불필요하게 수 차례 이뤄져 지연(Latency)와 CPU 성능 등에 영향을 미치게 되고 결론적으로 애플리케이션 성능 저하의 원인이 될 수 있습니다.
이런 통상적인 데이터 통신에 RDMA 기술을 적용하면 이러한 불필요한 시스템 내부의 여러 번의 버퍼 카피를 거치지 않고 RDMA가 하드웨어 기반으로 지원되는 버퍼 카피를 거치지 않고 RDMA가 하드웨어 기반으로 지원되는 NIC 카드를 이용해 데이터를 직접 전송할 수 있고 마찬가지로 리모트 시스템에서도 애플리케이션 쪽으로 데이터를 직접 전송할 수 있습니다. 이렇게 되면 성능과 지연(Latency) 면에 막대한 영향을 미칠 수 있죠.
기본적으로 인피니밴드를 기반으로 만들어진 RDMA 기술은 지난 20여년간 사용된 기술인데요, 최근에는 RDMA 기술을 이더넷 기반으로 사용할 수 있는 RoCE(RDMA over converged ethernet) 네트워크 프로토콜도 개발됐습니다.
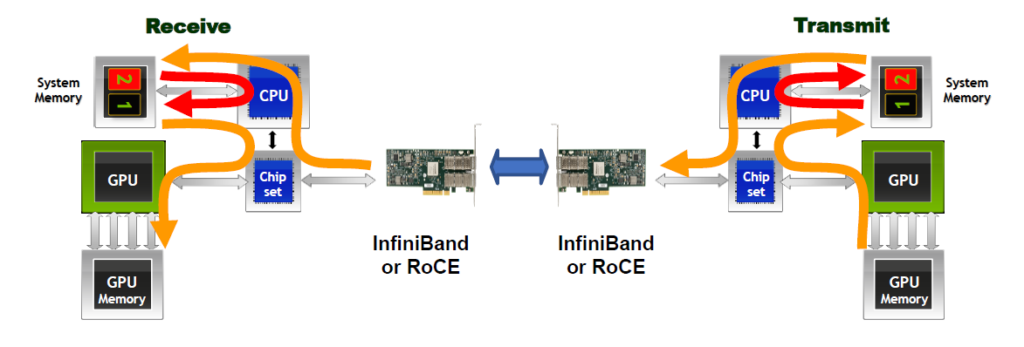
이러한 RDMA 기술을 GPU 컴퓨팅에 접목한 것이 바로 GPUDirect RDMA인데요.
위 이미지는 GPUDirect 기술을 사용하기 이전의 두대의 시스템이 네트워크를 통해서 GPU 기반 데이터 통신을 하는 것을 설명하고 있습니다.
GPU 메모리의 데이터를 네트워크를 통해서 전달하기 위해서 앞서 TCP/IP 기반 데이터 통신에서 살펴본 것처럼 시스템 메모리 영역에서 불필요한 버퍼 카피 및 CPU를 사용을 해야 했습니다.
이제 GPUDirect RDMA 기술을 통해서 시스템 메모리 영역에서 이제 더 이상 불필요한 버퍼 카피 및 CPU를 offload시킬 수 있고 이를 통해서 결과적으로 애플리케이션의 지연과(Latency)와 처리량(Throughput)을 각각 10배 개선해 궁극적으로는 애플리케이션 성능을 향상시킬 수 있게 되었습니다.
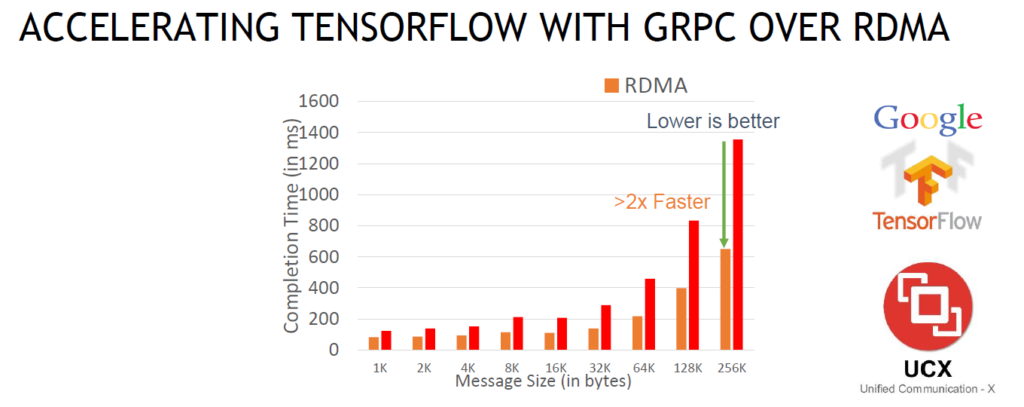
위 그림은 동일 시스템 기준으로 각각 RDMA와 TCP 기반으로 네트워크를 사용했을 때 텐서플로우와 같은 애플리케이션의 성능을 비교한 그림인데요. 애플리케이션 성능이 대략 2배 이상 향상된 것을 보실 수 있습니다.
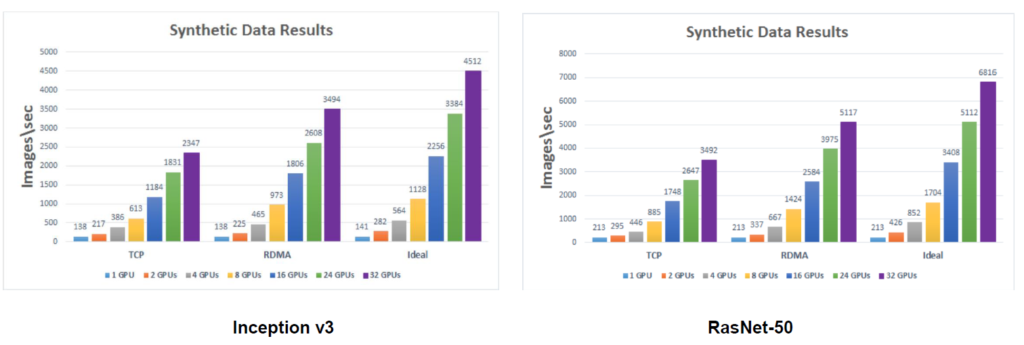
위 그림은 Inception, RasNet을 이용해 멀티 GPU와 멀티노드 환경에서 실제 벤치마크 테스트를 진행했을 때 RDMA을 사용했을 때와 그렇지 않을 때 성능에 어떤 차이가 있는지 보여주는 그림입니다.
SHARP
기존 CPU, GPU 기반의 컴퓨팅 환경에서 네트워크 부분은 단순하게 데이터를 전송하는 역할만 했었는데 인-네트워크 컴퓨팅을 통해 실제 컴퓨팅 영역에 참여해 성능을 향상할 수 있습니다.
엔비디아의 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol) 기능이 바로 인-네트워크 환경을 지원하는 기술인데요. 개별 호스트들이 보유한 데이터, 이에 대한 컴퓨팅, 대당 데이터의 연산 결과에 대한 Collective 연산을 호스트 간에서만 진행하는 것이 아닌 호스트에서 전달된 데이터를 인피니밴드 스위치에서 모아 그 결과를 계산하고 결과값을 호스트 레벨에 전송해 컴퓨팅 성능을 향상하는 기능입니다.
그래서 인피니밴드에 SHARP 기술을 함께 사용하면, 단순하게 인피니밴드 또는 RoCE 기술을 사용했을 때 대비 지연을 최대 4배 이상 낮출 수 있습니다.
또한 MLPerf나 Variable Auto-Encoder와 같은 벤치마크를 통해 실제 애플리케이션 성능이 얼만큼 향상되는지 보면 그림에서 보이는 것처럼 18% 향상됩니다.
DGX A100 네트워킹
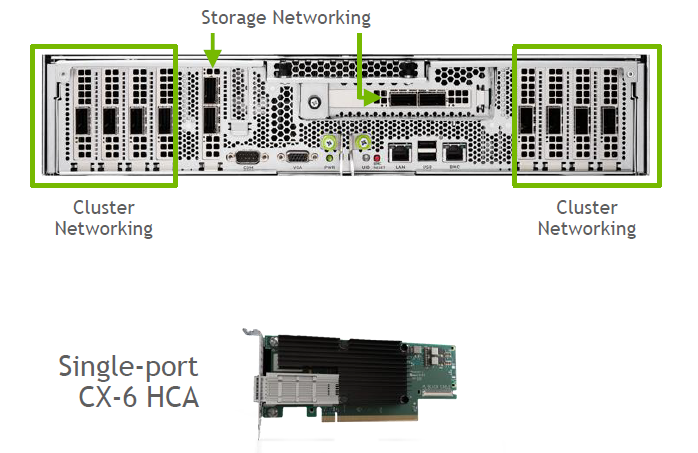
이제 DGX A100용 네트워킹 구성에 대해 설명하겠습니다.
DGX A100이라는 단일 시스템은 여덟 개의 200Gbps HDR 또는 이더넷 200GbE를 지원하는 단일 포트 ConnectX-6 VPI(Virtual Protocol Interconnect)라는 8장의 어댑터 카드가 장착돼 있고, 추가적으로 데이터 스토리지 연결하기 위해서 한 개의 ConnectX-6 듀얼 포트 어댑터가 기본적으로 장착이 돼 있습니다. 또 여기에 ConnectX-6 어댑터를 스토리지 네트워크를 이중화 구성을 위해 1장 더 추가적으로 장착이 가능합니다.
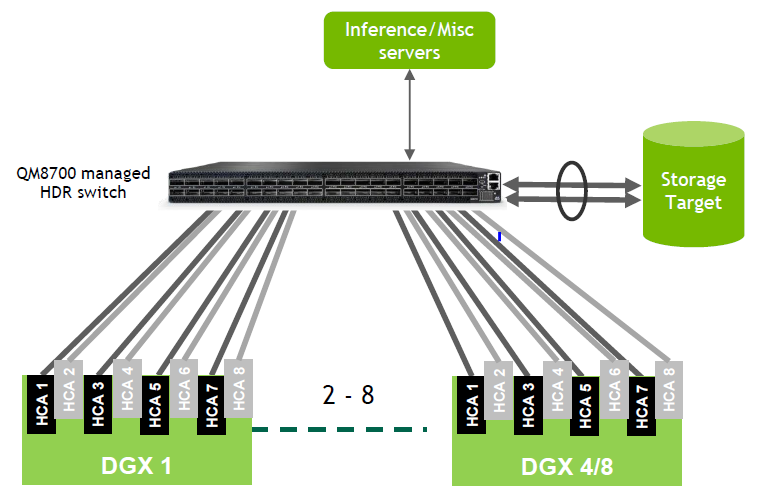
고가용성을 고려하지 않고 2대에서 8대의 DGX A100 시스템을 구성할 때는 인피니밴드 스위치를 통해 구성할 수 있습니다. 이것이 가장 기본적인 베이스 네트워크 구성이죠. 인피니밴드 스위치로는 40개의 200Gbps HDR 포트를 지원하는 QM8700이라는 모델이 사용됩니다.
DGX A100에 장착 되어있는 여덟 개 카드를 모두 사용하는 환경을 구성하려면 최대 4대의 시스템을 단일 스위치에 연결해서 사용 가능합니다. 나머지 8개의 HDR 포트로는 추론 등 다양한 서버들을 수용하는 형태로 연결할 수 있고 스토리지도 이렇게 인피니밴드 기반으로 연결해서 사용할 수 있습니다.
인피니밴드의 경우에는 별도의 인피니밴드 스위치의 추가 설정 등이 필요 없는 플러그앤플레이 방식으로 단순하게 연결해서 바로 사용하실 수 있습니다.
그 다음은 이더넷 기반으로 사용할 경우입니다. 이 때는 32포트 200GbE 이더넷을 지원하는 단일 스위칭 칩 기반의 저지연 고성능의 이더넷 스위치인 엔비디아 SN3700이란 모델을 사용할 수 있습니다.
이 경우에도 마찬가지로 DGX A100 시스템의 8포트를 모두 200GbE로 사용하는 환경으로 구성하면 3대까지의 DGX A100 시스템을 단일 이더넷 스위치에 연결해 네트워크를 구성할 수 있습니다. 나머지 200GbE 8포트들은 스토리지나 추론 등 여러가지 서버들을 연결하는데 사용할 수 있죠. 마찬가지로 가장 기본적인 L2 이더넷 스위치 환경으로 구성해서 사용할 경우 스위치 상에서 별다른 구성 설정은 필요 없습니다.
고가용성을 위해서는 2개의 HDR 지원 인피니밴드 스위치를 사용할 수 있습니다. 2대 스위치 사이에는 단일 스위치가 오작동할 경우를 대비해 그림처럼 최소 4개의 HDR 인터페이스를 연결해 구성할 수 있습니다. 이렇게 두 대의 인피니밴드 스위치를 사용해 최대 8대의 DGX A100 시스템을 인피니밴드 네트워크로 구성 가능하며, 이 경우에는 9번째 어뎁터 카드를 SN3700 이더넷 스위치를 통해서 스토리지 연결용으로 구성 가능합니다. 그리고 필요하다면 스토리지 네트워크의 고가용성을 위해서 추가적인 이더넷 스위치와 어뎁터 카드를 사용할 수 있습니다.
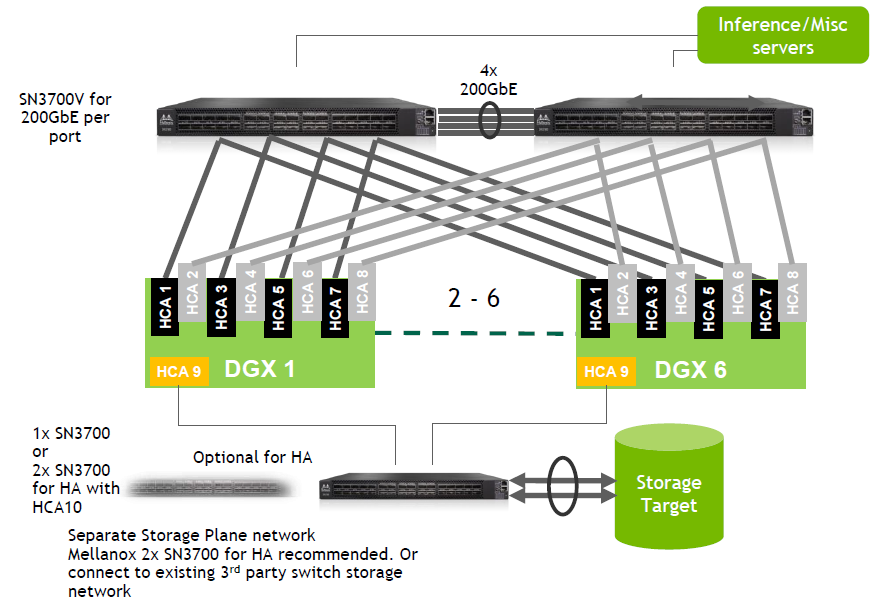
이더넷도 마찬가지로 고가용성을 고려한 네트워크를 구성할 수 있는데요. 위와 같이 최대 여섯 대의 DGX A100 시스템을 두대의 스위치에서 수용 가능하고, 스토리지도 별도의 이더넷 스위치를 통해서 연결 가능합니다. 물론 스토리지 이중화를 고려할 경우에는 추가적인 스위치를 통해서 이중화 구성을 하면 됩니다.
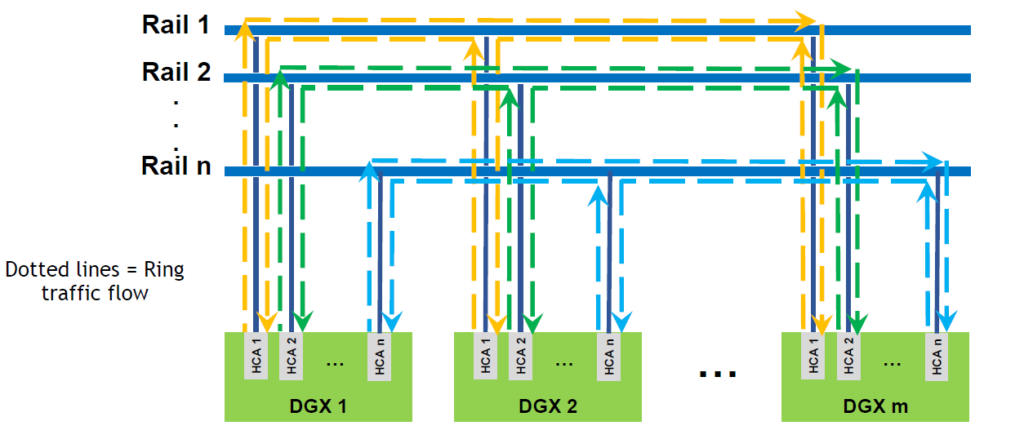
POD 또는 SuperPOD를 위한 네트워크 디자인에 대한 설명에 앞서 먼저 NCCL 라이브러리를 통한 실제 멀티 GPU 멀티 노드간의 데이터 통신이 어떻게 이루어지는지 살펴 보도록 하겠습니다.
NCCL 라이브러리를 통해서 실제로 데이터통신을 할 때는 위 그림과 같이 각각의 DGX A100 시스템의 첫 번째 어댑터 카드간, 또는 두 번째 어댑터 카드 간 통신하는 링 토폴로지를 만들게 되고, 엔비디아에서는 이것을 Rail이라고 부르는데요.
앞서 살펴본 DGX A100 10대 이하의 소규모 네트워크 구성에서는 이러한 Rail 기반의 데이터 통신 특성을 특별히 고려하지 않아도 문제가 되지 않지만 DGX A100 10대 이상의 POD가 사용되는 구성이나 100개 이상의 DGX A100 시스템을 하나의 컴퓨팅 단위로 SuperPOD 환경을 위한 네트워크를 구성할 때는 이 부분을 반드시 고려해야 합니다.
그래서 이런 Rail 기반의 데이터 통신의 특성을 고려해 기본적으로는 20대의 DGX A100 시스템들을 하나의 POD 또는 SU(Scalable Unit)로 그룹을 만들고 해당 각 SU 당 8대의 인피니밴드 스위치를 사용해서 Rail 기반 통신에 최적의 네트워크를 구성합니다. 그 다음에는 이런 8대의 스위치들을 집선하는 다음 레이어의 스위치를 사용하면 됩니다.
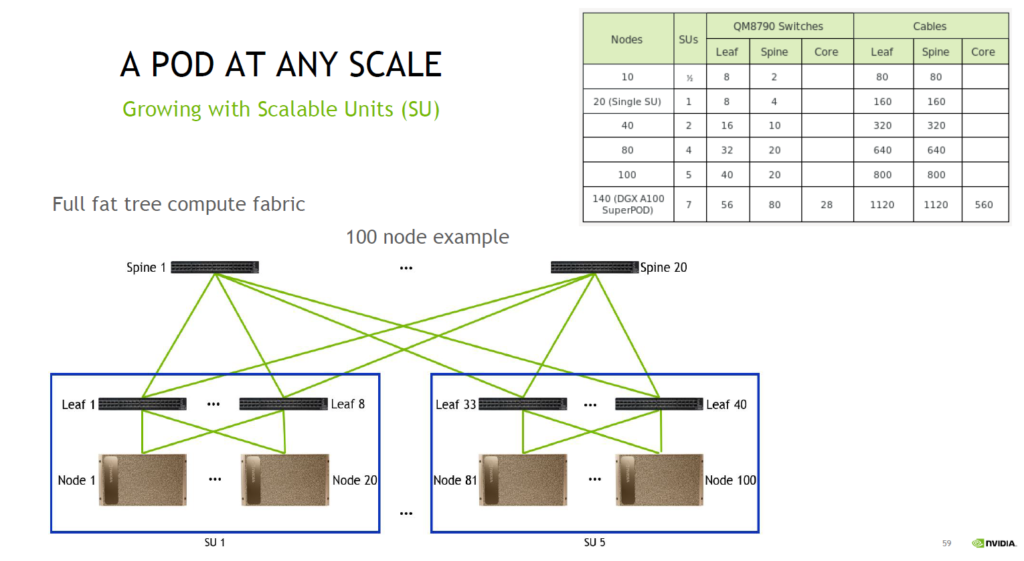
이 그림은 SuperPOD 기준 100대의 DGX A100 시스템에 대한 네트워크 구성입니다. 개별 POD에는 8대의 인피니밴드 스위치가 사용이 되며, 이와 같은 방식으로 SU(Scalable Unit)가 한 단위씩 증가하는 형태로 구성이 되죠.
100대의 DGX A100 시스템의 경우에는 SU(Scalable Unit)이 다섯 개 사용되는데요, 개별 SU에는 8대의 리프(Leaf) 인피니밴드 스위치가 사용되고 해당 각각의 리프(Leaf) 인피니밴드 스위치는 DGX A100 쪽으로 20개의 200Gbps HDR 포트들과 스파인(Spine) 인피니밴드 스위치들로는 20개의 200Gbps HDR 포트를 사용할 수 있습니다. 또한 이러한 리프(leaf) 인피니밴드 스위치들을 집선하는 용도로 스파인(Spine) 인피니밴드 스위치 20대가 사용됩니다.
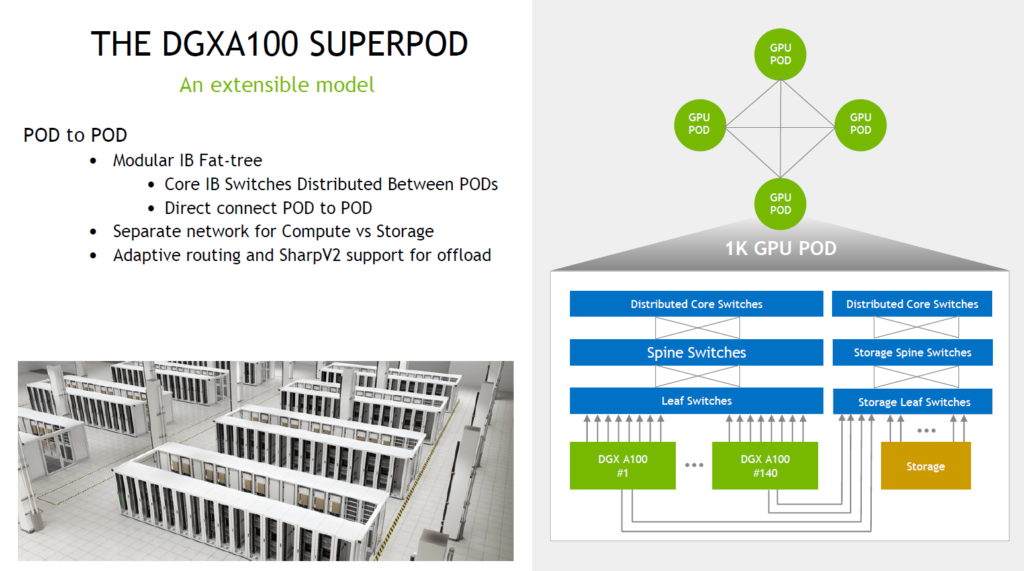
DGX A100 SuperPOD 네트워크 디자인의 경우에는 140대의 DGX A100 시스템을 연결하는 네트워크 구성입니다.
위 그림과 같이 앞에서 살펴본 100대의 DGX A100 시스템들을 위한 네트워크 구성과 동일하게 DGX A100 SU(Scalable Unit) 당 8대씩 리프(Leaf) 인피니밴드 스위치들과 그런 스위치를 모두 다 집선하는 스파인(Spine) 인피니밴드 스위치들을 사용해 연결해야 하며 이번에는 추가적으로 이러한 스파인(Spine) 인피니밴드 스위치들을 한 번 더 집선하는 코아(Core) 인피니밴드 스위치를 구성해야 합니다.
이와 같은 다단계 네트워크 구성은 현재 단일 인피니밴드 스위치에서 지원 가능한 200Gbps HDR 40포트의 포트 개수를 고려한 Fat-Tree 네트워크 디자인으로 이렇게 디자인된 네트워크 구성을 기반으로 앞서 설명한 SHARP와 같은 인-네트워크 컴퓨팅 기술을 활용해 전체적인 GPU 기반 컴퓨팅 및 애플리케이션 성능을 향상시킬 수 있습니다.