엔비디아 GPU 기반 클라우드 서버로 구동됩니다. 이제 이 획기적인 도구가 로컬에서도 빠른 맞춤형 생성 AI를 구동하기 위해 엔비디아 RTX 기반 윈도우 PC에도 제공됩니다.
현재 무료로 다운로드할 수 있는 Chat with RTX는 최소 8GB 이상의 비디오 랜덤 액세스 메모리 또는 VRAM을 갖춘 엔비디아 지포스 RTX 30 시리즈 GPU로 가속화된 자체 콘텐츠로 챗봇을 개인화할 수 있는 기술 데모입니다.
무엇이든 물어보세요.
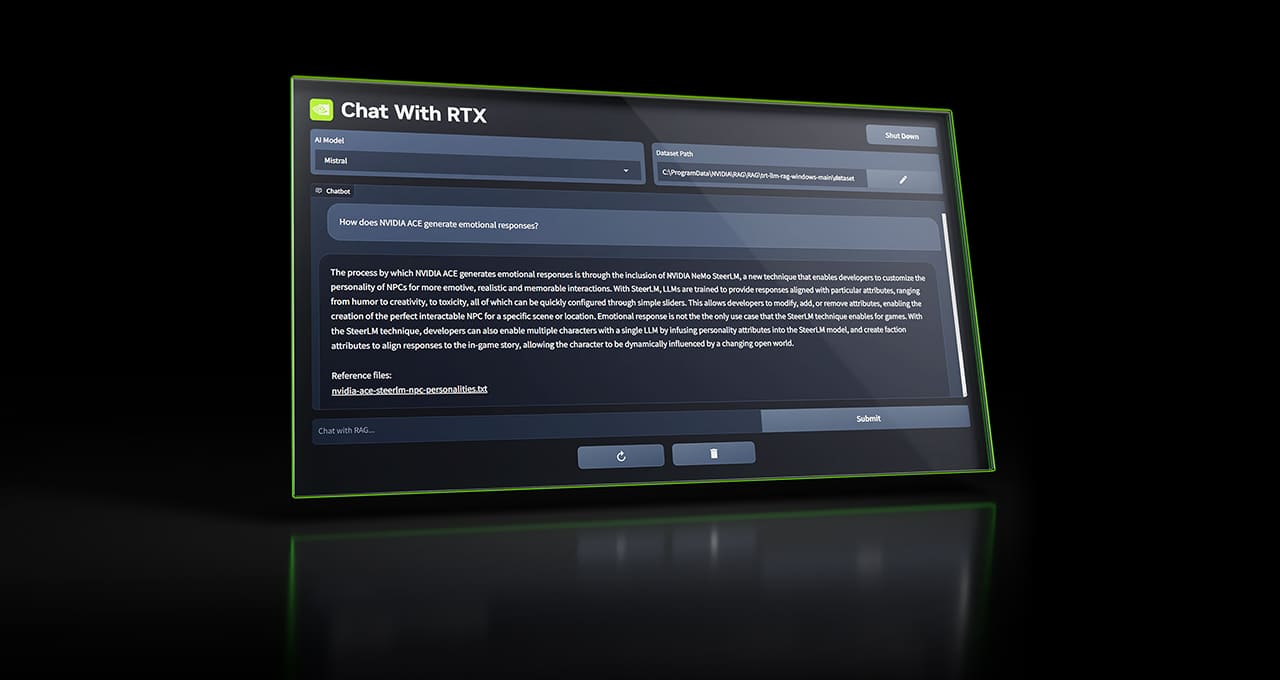
Chat with RTX는 검색 증강 생성 (RAG), 엔비디아 TensorRT-LLM 소프트웨어와 엔비디아 RTX 가속 성능을 사용하여 지포스 기반 윈도우 PC에 생성형 AI 기능을 제공합니다. 사용자는 PC의 로컬 파일을 데이터세트로서 미스트랄이나 라마 2와 같은 오픈 소스 대규모 언어 모델에 빠르고 쉽게 연결하여 쿼리를 통해 상황에 맞는 답변을 빠르게 얻을 수 있습니다
사용자는 노트나 저장된 콘텐츠를 검색하는 대신 간단히 검색어를 입력할 수 있습니다. 예를 들어 “라스베가스에 있을 때 파트너가 추천한 레스토랑이 어디였나요?”라고 질문하면 Chat with RTX가 사용자가 가리키는 로컬 파일을 스캔하여 해당 상황의 문맥과 함께 답변을 제공합니다.
이 도구는 .txt, .pdf, .doc/.docx, .xml 등 다양한 파일 형식을 지원합니다. 애플리케이션에서 이러한 파일이 포함된 폴더를 가리키면 도구가 몇 초 만에 해당 파일을 라이브러리에 로드합니다.
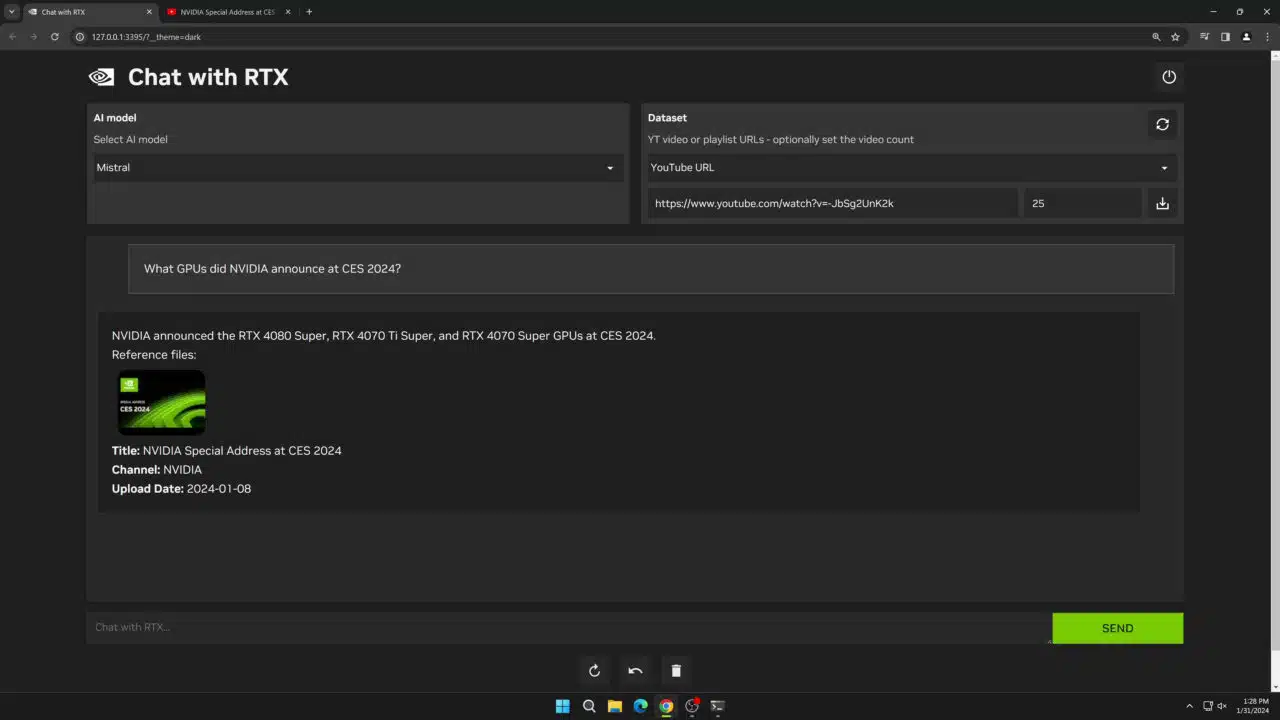
사용자는 유튜브 동영상이나 재생 목록의 정보도 포함할 수 있습니다. RTX로 채팅에 동영상 URL을 추가하면 사용자가 이러한 지식을 챗봇에 통합하여 문맥에 맞는 질문을 할 수 있습니다. 예를 들어, 좋아하는 인플루언서 동영상의 콘텐츠를 기반으로 여행 추천을 요청하거나 최고의 교육 리소스를 기반으로 빠른 튜토리얼과 사용법을 얻을 수 있습니다.
Chat with RTX는 윈도우 RTX PC 및 워크스테이션에서 로컬로 직접 실행되기 때문에 제공된 결과가 빠르며 사용자의 데이터는 디바이스에 유지됩니다. 클라우드 기반 LLM 서비스에 의존하는 대신 Chat with RTX를 사용하면 사용자가 민감한 데이터를 제3자와 공유하거나 인터넷에 연결할 필요 없이 로컬 PC에서 바로 처리할 수 있습니다.
Chat with RTX를 사용하려면 최소 8GB의 VRAM이 탑재된 지포스 RTX 30 시리즈 이상의 GPU와 더불어 윈도우 10 또는 11, 최신 엔비디아 GPU 드라이버가 필요합니다.
참: 사용자가 다른 설치 디렉토리를 선택하면 설치가 실패하는 문제가 발견되었습니다. 이 문제는 향후 릴리스에서 수정될 예정입니다. 당분간은 기본 설치 디렉터리(“C:\사용자\<사용자 이름>\AppData\Local\NVIDIA\ChatWithRTX”)를 사용해야 합니다.
RTX로 LLM 기반 애플리케이션 개발하기
Chat with RTX는 RTX GPU로 LLM을 가속화할 수 있는 잠재력을 보여줍니다. 이 앱은 GitHub에서 제공되는 TensorRT-LLM RAG 개발자 레퍼런스 프로젝트를 기반으로 제작되었는데요. 개발자는 이 레퍼런스 프로젝트를 사용하여 TensorRT-LLM으로 가속화된 RTX용 RAG 기반 애플리케이션을 직접 개발 및 배포할 수 있습니다. LLM 기반 애플리케이션 구축에 대해 자세히 알아보세요.
Chat with RTX에 대한 자세한 사항이나 다운로드는 여기에서 확인하세요. 또한 오는 3월 18일부터 21일까지 열리는 AI 및 가속 컴퓨팅 분야의 글로벌 컨퍼런스인 엔비디아 GTC에서 생성형 AI 관련 최신 트렌드와 적용 사례들을 들을 수 있는 세션들을 확인하세요.