편집자 노트: 본 글은 매달 개발자와 기업이 GPU를 사용하여 애플리케이션을 가속화하는 데 도움이 되는 최신 라이브러리, NIM 마이크로서비스 및 도구를 소개하는 새로운 CUDA Accelerated 블로그 시리즈의 첫 번째 글입니다.
뉴스 요약: 가속 컴퓨팅의 새로운 라이브러리는 데이터 처리, 생성형 AI, 추천 시스템, AI 데이터 큐레이션, 데이터 처리, 6G 리서치, 그리고 AI 물리학 등에서 엄청난 속도 향상을 제공하고 에너지 소비와 비용을 절감시켜 줍니다. 여기에는 다음과 같은 것들이 포함됩니다:
- LLM 애플리케이션: 맞춤형 데이터 세트를 생성하기 위한 NeMo 큐레이터, 고품질 합성 데이터 생성을 위한 이미지 큐레이션 및 Nemotron-4 340B 추가
- 데이터 처리: 며칠이 아닌 몇 분 만에 인덱스를 구축할 수 있는 벡터 검색용 cuVS와 오픈 베타 버전의 새로운 Polars GPU 엔진 추가
- 물리 AI: 물리 시뮬레이션의 경우, 워프는 새로운 TIle API로 연산을 가속화합니다. 무선 네트워크 시뮬레이션의 경우, Aerial은 레이 트레이싱 및 시뮬레이션을 위한 더 많은 지도 형식을 추가합니다. 또한 링크 수준의 무선 시뮬레이션을 위해 시오나는 실시간 추론을 위한 새로운 툴체인을 추가합니다.
전 세계 기업들은 CPU로만 실행하던 애플리케이션의 속도를 높이기 위해 점점 더 많은 기업들이 NVIDIA 가속 컴퓨팅으로 전환하고 있습니다. 이를 통해 엄청난 속도 향상을 달성하고 놀라운 에너지 절약의 혜택을 누릴 수 있게 되었습니다.
휴스턴의 CPFD는 차세대 재활용 시설을 설계하는 데 도움이 되는 Barracuda Virtual Reactor 소프트웨어와 같은 산업용 애플리케이션을 위한 전산 유체 역학 시뮬레이션 소프트웨어를 제작합니다. 플라스틱 재활용 시설에서는 NVIDIA 가속 컴퓨팅으로 구동되는 클라우드 인스턴스에서 CPFD 소프트웨어를 실행합니다. CUDA GPU 가속 가상 머신을 사용하면 CPU 기반 워크스테이션을 사용할 때보다 400배 더 빠르고 140배 더 에너지 효율적으로 시뮬레이션을 효율적으로 확장하고 실행할 수 있습니다.

한 인기 있는 화상 회의 애플리케이션은 시간당 수십만 건의 가상 회의에 자막을 제공합니다. CPU를 사용해 라이브 캡션을 생성할 때 이 앱은 트랜스포머 기반 음성 인식 AI 모델을 초당 세 번 쿼리할 수 있었습니다. 클라우드의 GPU로 마이그레이션한 후에는 애플리케이션의 처리량이 초당 200회로 증가하여 속도가 66배 빨라지고 에너지 효율성이 25배 향상되었습니다.
전 세계의 한 전자상거래 웹사이트는 NVIDIA 가속 클라우드 컴퓨팅 시스템에서 실행되는 딥 러닝 모델 기반의 고급 추천 시스템을 사용하여 하루에 수억 명의 쇼핑객에게 필요한 제품을 연결합니다. 클라우드에서 CPU에서 GPU로 전환한 후 33배의 속도 향상과 약 12배의 에너지 효율 향상으로 지연 시간을 크게 줄였습니다.
데이터가 기하급수적으로 증가함에 따라 클라우드의 가속화된 컴퓨팅은 더욱 혁신적인 분야에도 활용 가능할 것입니다.
지속 가능한 컴퓨팅을 위한 CUDA GPU의 NVIDIA 가속 컴퓨팅
현재 CPU 서버에서 실행 중인 모든 AI, HPC 및 데이터 분석 워크로드를 CUDA GPU 가속으로 전환하면 데이터센터가 연간 40테라와트시의 에너지를 절약할 수 있을 것으로 NVIDIA는 추정하고 있습니다. 이는 미국 가정 5백만 가구가 연간 소비하는 에너지와 거의 맞먹는 양입니다.
가속 컴퓨팅은 CUDA GPU의 병렬 처리 기능을 사용하여 CPU보다 훨씬 빠르게 작업을 완료함으로써 생산성을 향상시키는 동시에 비용과 에너지 소비를 획기적으로 줄일 수 있습니다.
CPU 전용 서버에 GPU를 추가하면 피크 전력이 증가하지만, GPU 가속화는 작업을 빠르게 완료한 다음 저전력 상태로 전환합니다. GPU 가속 컴퓨팅으로 소비되는 총 에너지는 범용 CPU보다 훨씬 낮으면서도 뛰어난 성능을 제공합니다.
지난 10년 동안 NVIDIA AI 컴퓨팅은 거대 언어 모델을 처리할 때 약 100,000배 이상의 에너지 효율성을 달성했습니다. 이를 원근법에 비유하자면, NVIDIA의 가속 컴퓨팅 플랫폼에서 AI의 효율성이 향상된 만큼 자동차 연비의 효율성이 개선된다면 갤런당 500,000마일을 주행할 수 있게 됩니다. 이는 1갤런 미만의 휘발유로 달까지 갔다가 돌아올 수 있는 거리입니다.
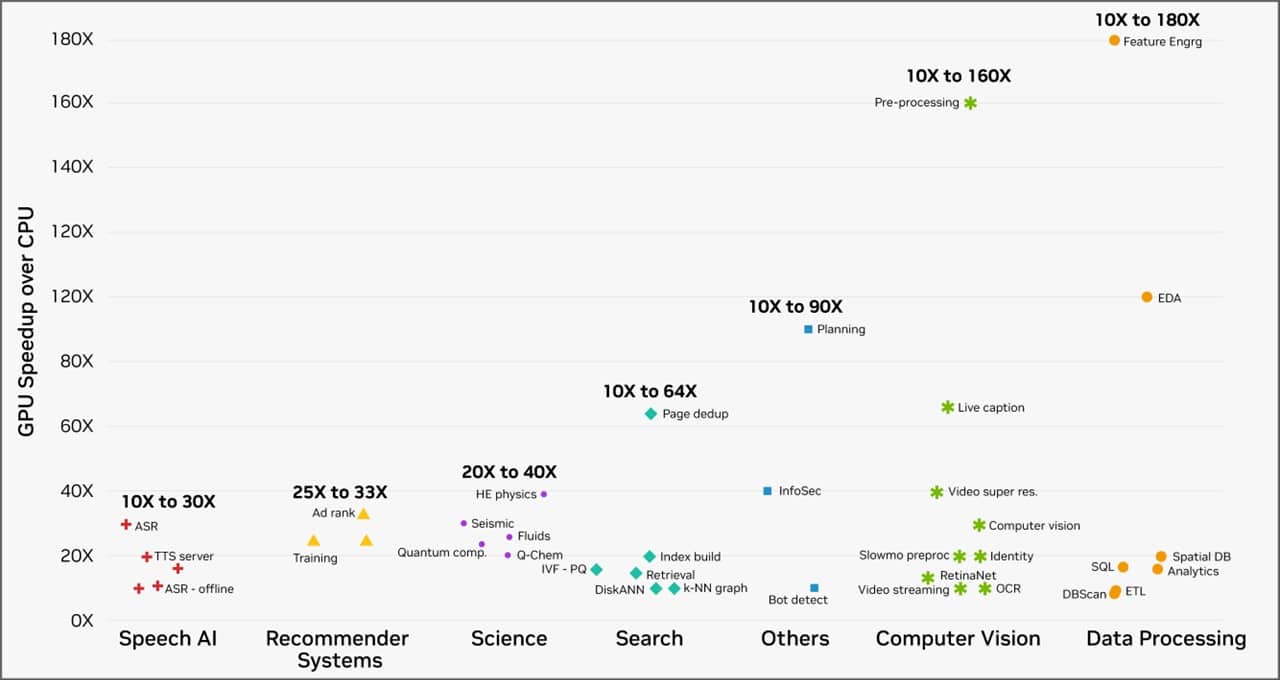
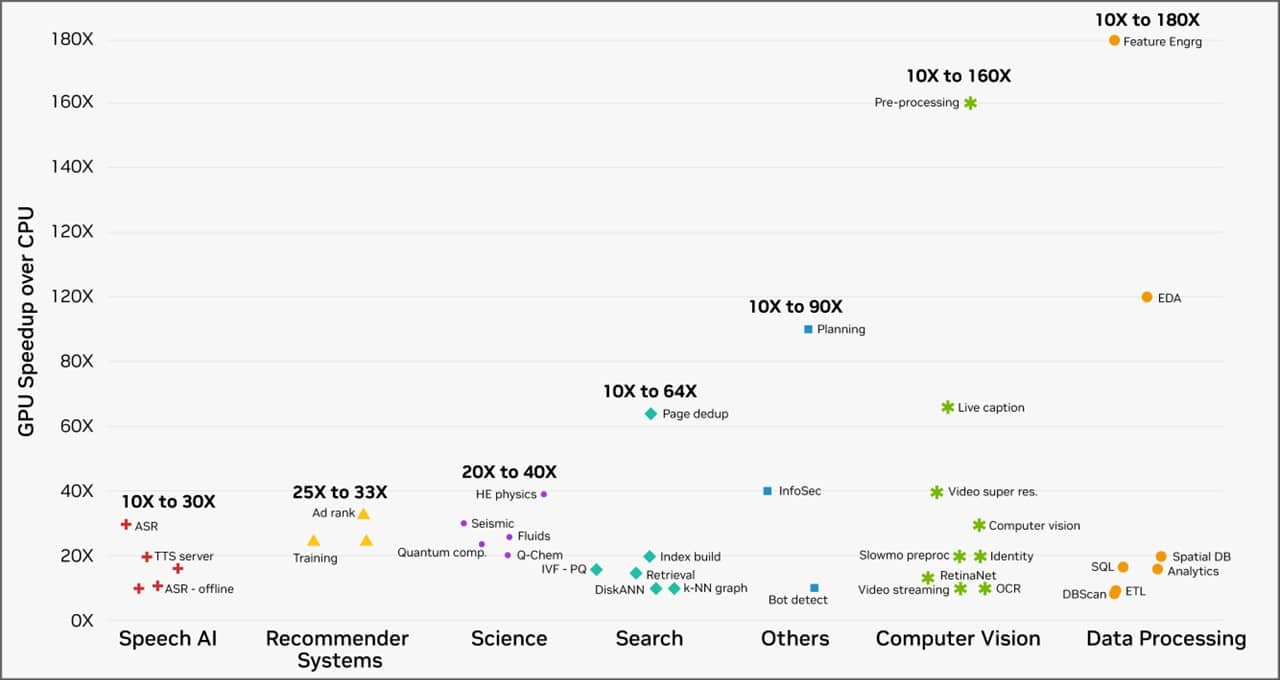
이처럼 AI 워크로드의 효율성이 극적으로 향상되는 것 외에도 GPU 컴퓨팅은 CPU에 비해 놀라운 속도 향상을 달성할 수 있습니다. 클라우드 서비스 제공업체에서 워크로드를 실행하는 NVIDIA 가속 컴퓨팅 플랫폼의 고객은 아래 차트에서 볼 수 있듯이 데이터 처리부터 컴퓨터 비전까지 다양한 실제 작업 영역에서 10~180배의 속도 향상을 경험했습니다.
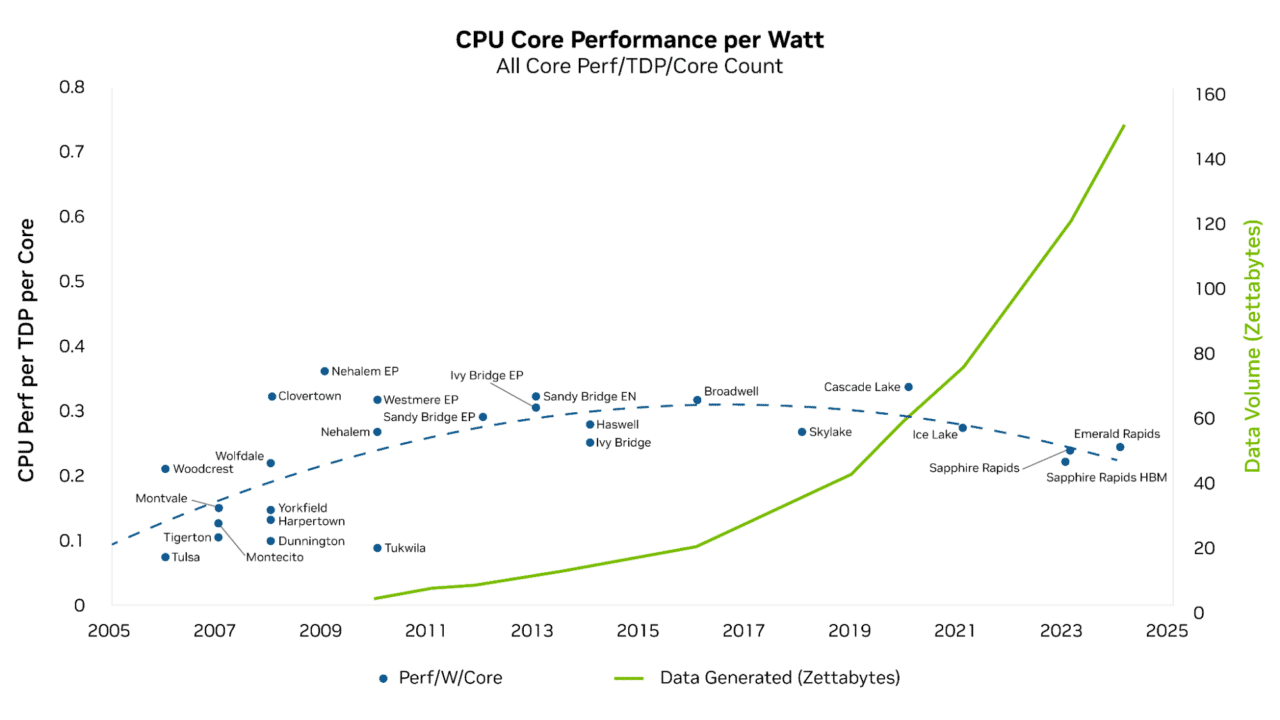
워크로드가 계속해서 기하급수적으로 더 많은 컴퓨팅 성능을 요구함에 따라 CPU는 필요한 성능을 제공하는 데 어려움을 겪어 왔으며, 이로 인해 성능 격차가 커지고 “컴퓨팅 인플레이션”이 발생하고 있습니다. 아래 차트는 데이터 증가가 CPU의 와트당 컴퓨팅 성능 증가를 훨씬 앞지른 다년간의 추세를 보여줍니다.
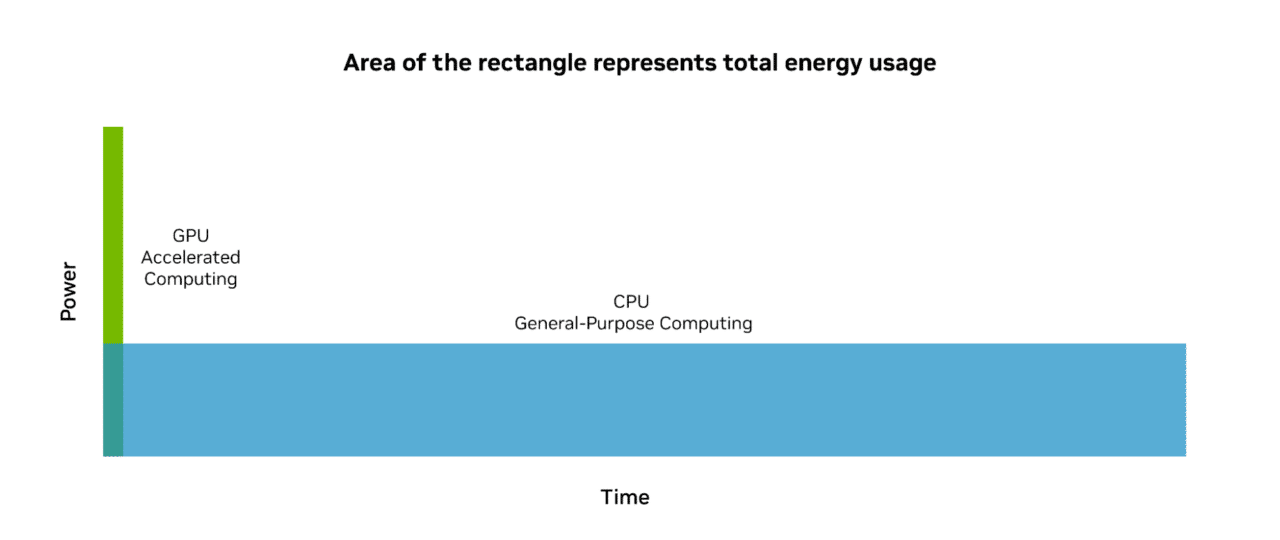
GPU 가속으로 에너지를 절약하면 비용과 에너지가 낭비될 수 있는 부분을 확보할 수 있습니다.
에너지 효율을 크게 절감할 수 있는 가속 컴퓨팅이야 말로 지속 가능한 컴퓨팅입니다.
모든 업무에 적합한 도구
GPU는 범용 CPU용으로 작성된 소프트웨어를 가속화할 수 없습니다. 특정 워크로드를 가속화하려면 특수 알고리즘 소프트웨어 라이브러리가 필요합니다. 정비공이 드라이버부터 렌치까지 다양한 작업을 위한 전체 공구 상자를 가지고 있는 것처럼, NVIDIA는 데이터 구문 분석과 연산 실행과 같은 저수준 기능을 수행할 수 있는 다양한 라이브러리 세트를 제공합니다.
각 NVIDIA CUDA 라이브러리는 NVIDIA GPU에 특화된 하드웨어 기능을 활용하도록 최적화되어 있습니다. 이 두 라이브러리를 결합하면 NVIDIA 플랫폼의 강력한 성능을 활용할 수 있습니다.
CUDA 플랫폼 로드맵에 새로운 업데이트가 계속 추가되어 다음과 같은 다양한 활용 사례에 걸쳐 확장되고 있습니다:
LLM 애플리케이션
NeMo Curator는 개발자가 거대 언어 모델(LLM) 활용 사례에서 커스터마이징 데이터 세트를 신속하게 생성할 수 있는 유연성을 제공합니다. 최근에는 텍스트를 넘어 이미지 큐레이션을 포함한 멀티모달 지원으로 확장된 기능을 발표했습니다.
SDG(합성 데이터 생성)는 기존 데이터 세트를 고품질의 합성 생성 데이터로 보강하여 모델과 LLM 애플리케이션을 사용자 정의하고 미세 조정합니다. 기업과 개발자가 모델 출력을 사용하고 맞춤형 모델을 구축할 수 있도록 SDG를 위해 특별히 제작된 새로운 모델 제품군인 Nemotron-4 340B를 발표했습니다.
데이터 프로세싱 애플리케이션
cuVS는 LLM과 시맨틱 검색 전반에 걸쳐 놀라운 속도와 효율성을 제공하는 GPU 가속 벡터 검색 및 클러스터링을 위한 오픈 소스 라이브러리입니다. 최신 cuVS를 사용하면 몇 시간 또는 며칠이 아닌 몇 분 만에 대규모 인덱스를 구축하고 대규모로 검색할 수 있습니다.
Polars는 쿼리 최적화 및 기타 기술을 사용해 단일 시스템에서 수억 행의 데이터를 효율적으로 처리하는 오픈 소스 라이브러리입니다. NVIDIA의 cuDF 라이브러리로 구동되는 새로운 Polars GPU 엔진은 오픈 베타 버전으로 제공될 예정입니다. 이 엔진은 CPU 대비 최대 10배의 성능 향상을 제공하여 데이터 전문가와 애플리케이션에 가속 컴퓨팅의 에너지 절감 효과를 가져다줍니다.
피지컬 AI
고성능 GPU 시뮬레이션 및 그래픽을 위한 Warp는 그리고 물리 시뮬레이션, 인식, 로보틱스 및 기하학 처리를 위한 차별화된 프로그램을 더 쉽게 작성할 수 있도록 하여 공간 컴퓨팅을 가속화하는 데 도움을 줍니다. 다음 릴리스에서는 개발자가 매트릭스와 Fourier 계산을 위해 GPU 내부의 Tensor 코어를 사용할 수 있는 새로운 타일 API가 지원될 예정입니다.
Aerial은 상용 애플리케이션 및 산업 연구를 위한 무선 네트워크를 설계, 시뮬레이션 및 운영하기 위한 Aerial CUDA 가속 RAN 및 Aerial Omniverse 디지털 트윈을 포함하는 가속 컴퓨팅 플랫폼 제품군입니다. 다음 릴리스에는 레이 트레이싱과 더 높은 정확도의 시뮬레이션을 위한 더 많은 지도 형식이 포함된 새로운 Aerial 확장 기능이 포함될 예정입니다.
Sionna는 무선 및 광통신 시스템의 링크 수준 시뮬레이션을 위한 GPU 가속 오픈 소스 라이브러리입니다. Sionna는 GPU를 통해 수 배 빠른 시뮬레이션을 구현하여 이러한 시스템을 대화형으로 탐색하고 차세대 물리 계층 연구를 위한 기반을 마련합니다. 다음 릴리스에는 신경망 기반 수신기를 설계, 훈련 및 평가하는 데 필요한 전체 툴체인이 포함될 예정이며, 여기에는 NVIDIA TensorRT를 사용한 신경망 수신기의 실시간 추론 지원도 포함됩니다.
NVIDIA는 400개 이상의 라이브러리를 제공하고 있습니다. CV-CUDA와 같은 일부 라이브러리는 사용자 생성 비디오, 추천 시스템, 매핑 및 화상 회의에서 흔히 사용되는 컴퓨터 비전 작업의 사전 및 사후 처리에 탁월합니다. cuDF와 같은 다른 라이브러리는 데이터 사이언스에서 SQL 데이터베이스와 판다의 핵심인 데이터 프레임과 테이블을 가속화합니다.
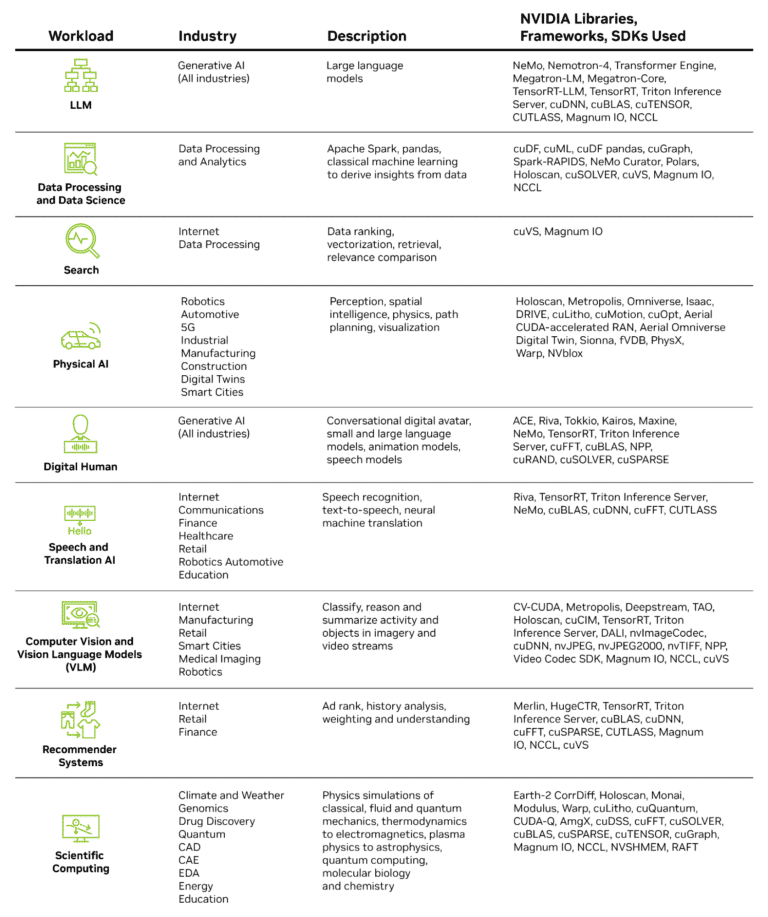
이러한 라이브러리 중 다수는 선형 대수 가속화를 위한 cuBLAS와 같이 다목적이며 여러 워크로드에서 사용할 수 있는 반면, 실리콘 컴퓨팅 리소그래피를 위한 cuLitho와 같이 특정 활용 사례에 초점을 맞춘 고도로 전문화된 라이브러리도 있습니다.
NVIDIA CUDA-X 라이브러리로 자체 파이프라인을 구축하지 않으려는 연구원들을 위해 NVIDIA NIM은 여러 라이브러리와 AI 모델을 최적화된 컨테이너에 패키징하여 프로덕션 배포를 위한 간소화된 경로를 제공합니다. 컨테이너화된 마이크로서비스는 즉시 향상된 처리량을 제공합니다.
이러한 라이브러리의 성능을 강화하는 것은 최고의 에너지 효율로 속도 향상을 제공하는 하드웨어 기반 가속 기능의 확대입니다. 예를 들어 NVIDIA Blackwell 플랫폼에는 압축된 데이터 파일을 인라인으로 압축 해제하는 압축 해제 엔진이 포함되어 있어 CPU보다 최대 18배 더 빠르게 압축을 해제할 수 있습니다. 이는 SQL, Apache Spark, 판다와 같이 스토리지의 압축 파일에 자주 액세스하고 런타임 계산을 위해 압축을 해제해야 하는 데이터 처리 애플리케이션의 속도를 획기적으로 높여줍니다.
클라우드 컴퓨팅 플랫폼에 NVIDIA의 특화된 CUDA GPU 가속 라이브러리를 통합하면 광범위한 워크로드에서 놀라운 속도와 에너지 효율성을 제공합니다. 이러한 조합은 기업의 비용을 크게 절감하고 지속 가능한 컴퓨팅을 발전시키는 데 중요한 역할을 하며, 클라우드 기반 워크로드에 의존하는 수십억 명의 사용자가 보다 지속 가능하고 비용 효율적인 디지털 생태계의 장점을 최대한 누릴 수 있도록 지원합니다.
NVIDIA의 지속 가능한 컴퓨팅 노력에 대해 자세히 알아보고 에너지 효율 계산기를 통해 잠재적인 에너지 및 배기가스 배출량 절감 효과를 확인해 보세요.
소프트웨어 제품 정보에 관한 자세한 내용은 공지를 참조하세요.