최근 출시된 DeepSeek-R1 모델 제품군은 AI 커뮤니티에 새로운 흥분을 불러일으키며 많은 개발자들이 문제 해결, 수학 및 코드 기능을 갖춘 최첨단 추론 모델을 로컬 PC에서 모두 실행할 수 있게 해주고 있습니다.
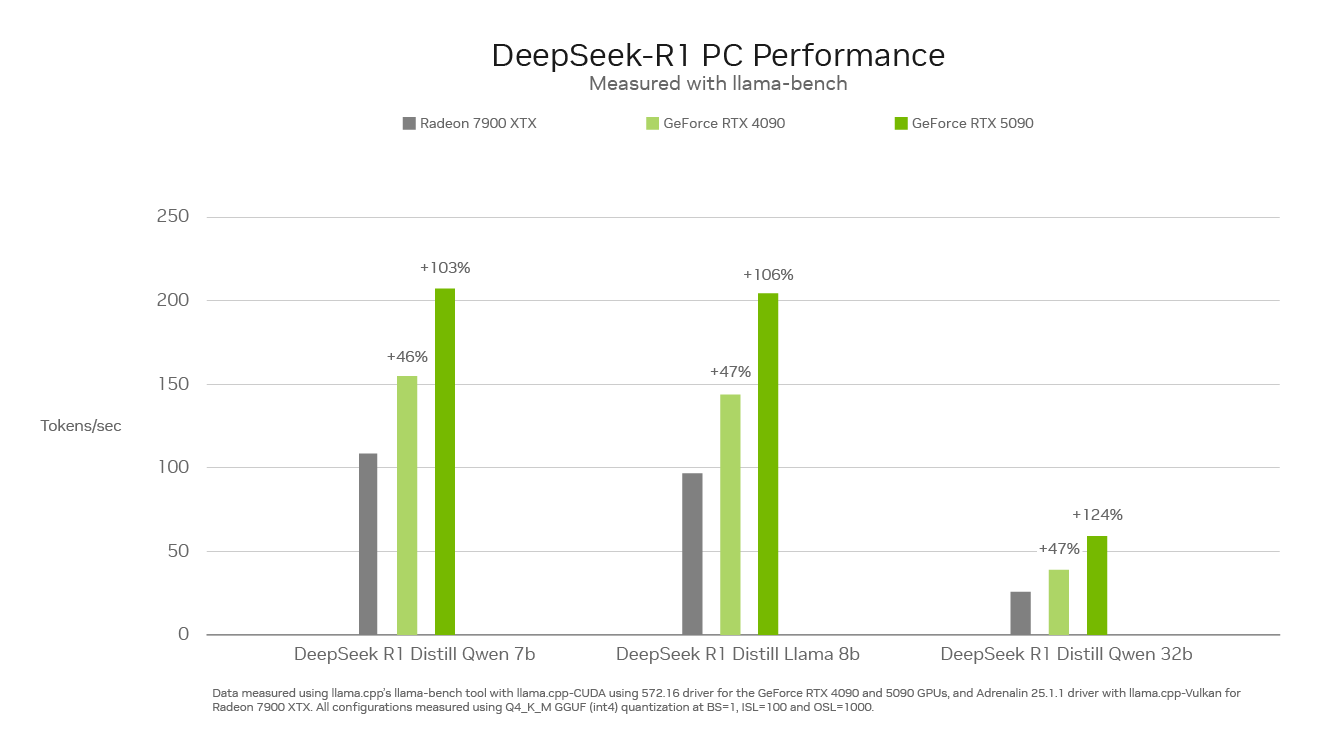
특히 초당 최대 3,352조 회의 AI 연산 능력을 갖춘 NVIDIA GeForce RTX 50 시리즈 GPU는 PC 시장의 그 어떤 제품보다 빠르게 DeepSeek를 실행할 수 있습니다.
새로운 차원의 모델
추론 모델은 작업을 해결하는 데 필요한 단계를 설명하면서 복잡한 문제를 해결하기 위해 ‘사고’와 ‘성찰’에 더 많은 시간을 할애하는 새로운 종류의 거대 언어 모델(LLM)입니다.
기본 원칙은 인간이 문제를 해결하는 방식과 마찬가지로 깊은 사고와 추론, 시간을 투자하면 어떤 문제든 해결할 수 있다는 것입니다. 문제에 더 많은 시간을 할애하고 더 많은 연산을 수행함으로써 LLM은 더 나은 결과를 얻을 수 있습니다. 이러한 현상을 테스트 타임 스케일링(Test-time scaling)이라고 하며, 모델이 문제를 추론하는 동안 컴퓨팅 리소스를 동적으로 할당하여 문제를 추론합니다.
추론 모델은 사용자의 요구 사항을 깊이 이해하고, 사용자를 대신하여 조치를 취하고, 모델의 사고 과정에 대한 피드백을 제공함으로써 시장 조사 분석, 복잡한 수학 문제 수행, 코드 디버깅 등과 같은 복잡한 다단계 작업을 해결하기 위한 에이전트 워크플로우를 열어 PC에서의 사용자 경험을 향상시킬 수 있습니다.
DeepSeek 차이점
DeepSeek-R1 증류 모델(Distilled models) 제품군은 671억 개의 파라미터로 구성된 거대 전문가 혼합 모델(MoE, Mixture-Of-Experts)을 기반으로 합니다. MoE 모델은 복잡한 문제 해결을 위한 여러 개의 소규모 전문가 모델로 구성됩니다. DeepSeek 모델은 작업을 더욱 세분화하고 하위 작업을 소규모 전문가 집합에 할당합니다.
DeepSeek는 증류(Distillation)라는 기술을 사용하여 6,710억 개의 파라미터로 구성된 거대한 DeepSeek 모델에서 15억~70억 개의 파라미터로 구성된 6개의 소규모 학생 모델 제품군을 구축했습니다. 671억 개의 파라미터를 가진 대형 DeepSeek-R1 모델의 추론 기능을 더 작은 규모의 Llama 및 Qwen 학생 모델에 학습시켜 빠른 성능으로 RTX AI PC에서 로컬로 실행되는 강력하고 작은 추론 모델을 만들었습니다.
RTX에서 최고의 성능
이 새로운 종류의 추론 모델에는 추론 속도가 매우 중요한데요. 전용 5세대 Tensor 코어로 구축된 GeForce RTX 50 시리즈 GPU는 데이터 센터에서 세계 최고의 AI 혁신을 촉진하는 동일한 NVIDIA Blackwell GPU 아키텍처를 기반으로 합니다. RTX는 DeepSeek를 완전히 가속하여 PC에서 최고의 추론 성능을 제공합니다.
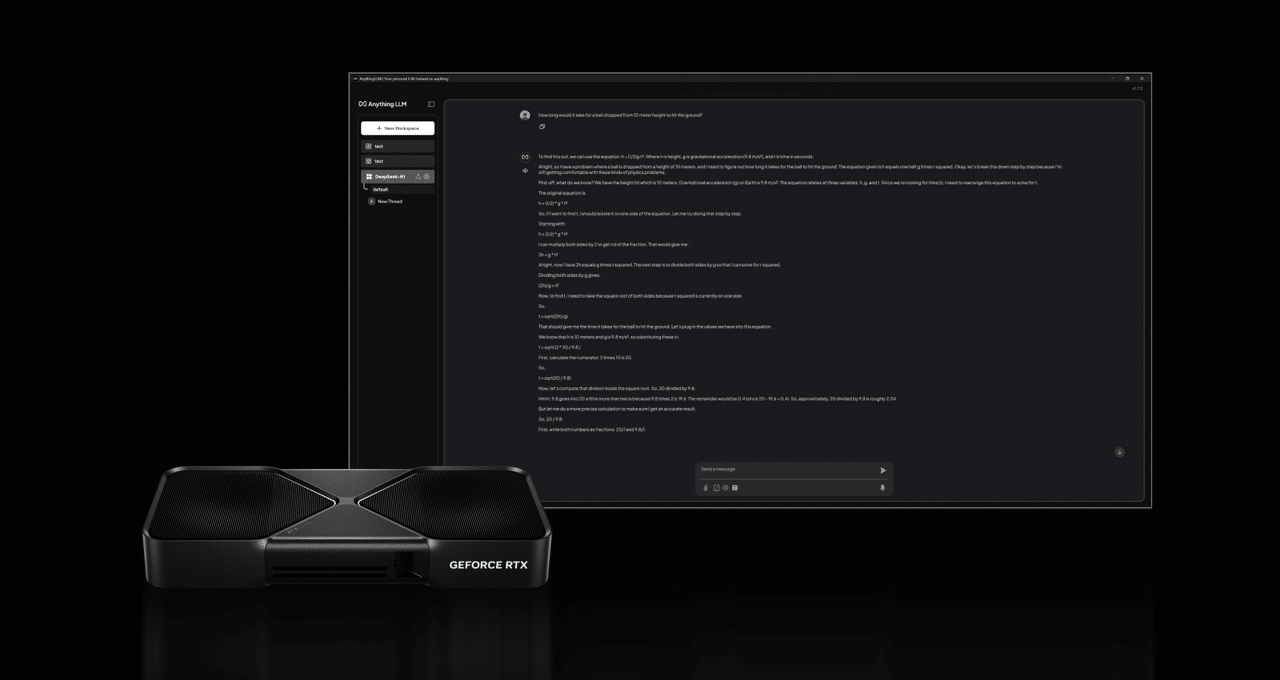
인기 도구에서 RTX의 DeepSeek 체험하기
NVIDIA의 RTX AI 플랫폼은 가장 광범위한 AI 도구, 소프트웨어 개발 키트 및 모델을 제공하며, GeForce RTX 50 시리즈 GPU 기반 PC를 포함하여 전 세계 1억 대 이상의 NVIDIA RTX AI PC에서 DeepSeek-R1의 기능에 액세스할 수 있습니다.
고성능 RTX GPU는 인터넷 연결 없이도 AI 기능을 항상 사용할 수 있게 해주며, 사용자가 민감한 자료를 업로드하거나 온라인 서비스에 쿼리를 노출할 필요가 없기 때문에 지연 시간이 짧고 개인정보 보호가 강화됩니다.
추론을 위한 Llama.cpp, Ollama, LM Studio, AnythingLLM, Jan.AI, GPT4All, OpenWebUI 등 방대한 소프트웨어 에코시스템을 통해 DeepSeek-R1과 RTX AI PC의 성능을 경험해 보세요. 또한 Unsloth를 사용하여 커스터마이징된 데이터로 모델을 파인튜닝할 수 있습니다.