
현재 모든 조직들이 연구, 개발, 제품, 비즈니스 프로세스에 인공지능(AI)을 접목하고 있습니다. 이는 조직이 주어진 목표를 뛰어넘은 성과를 얻을 수 있게 도움을 주며 보다 중요한 문제를 해결할 수 있는 다양한 경험과 전문 지식을 쌓게 해주죠.
그러나 기존의 컴퓨팅 인프라는 느린 CPU 아키텍처 속도, 다양한 워크로드와 프로젝트 실행에 필요한 다양한 시스템 요건 등으로 AI 기술과 함께 사용하기에 적합하지 않은데요. 오히려 복잡성과 비용이 증가하고 확장성을 제한하는 요인이 됩니다.
엔비디아는 조직이 이런 문제들을 극복하고 절대적으로 필요한 AI 기술로 주요 문제를 해결할 수 있도록 지원하기 위해 세계 최초로 AI를 위해 특별히 개발된 시스템 제품군인 ‘엔비디아 DGX 시스템’을 개발했습니다. 강력한 엔비디아 GPU, 엔비디아 NGC의 AI 최적화 소프트웨어를 활용해 DGX 시스템은 전례 없는 수준의 성능을 구현하고 복잡한 인테그레이션 과정으로 인한 어려움(integration complexity)도 해소했습니다.
엔비디아는 엔비디아 DGX A100를 출시한 바 있습니다. DGX A100은 새로운 엔비디아 A100 텐서 코어(Tensor Core) GPU에 기반한 DGX의 3세대 제품으로 AI 인프라에 사용될 수 있도록 개발된 보편적인 시스템입니다. 5 페타플롭(PF)의 AI 성능을 갖춰 분석, 훈련, 추론 등 모든 AI 워크로드에서 뛰어난 성능을 발휘하죠. 기업들은 이를 통해 언제든 모든 AI 업무의 속도를 높이는 단일 시스템으로 표준화할 수 있으며, 시간이 지남에 따라 바뀌는 컴퓨팅 조건에 활발하게 조절 가능합니다. 이렇게 비교할 수 없는 수준의 유연성은 관련 비용을 줄이고 확장성을 개선하며 DGX A100이 현대 AI 데이터센터의 기본적인 구성요소로 만들어 주는데요.
그렇다면 DGX A100의 설계와 아키텍처를 살펴볼까요?
시스템 아키텍처

엔비디아 A100 GPU: 탄력적인 컴퓨팅 시대를 위한 8세대 데이터센터 GPU
엔비디아 DGX A100 시스템에서 엔비디아 A100 GPU는 핵심 역할을 합니다. A100 GPU는 V100 GPU의 성능을 향상시키는 개선된 기능과 새로운 기능 등 대규모의 복잡한 AI 워크로드와 몇 가지 소규모 워크로드를 효율적으로 가속화할 수 있도록 설계됐는데요. A100 GPU는 40 GB 고대역폭 HBM2 메모리, 크기와 속도가 향상된 캐시 메모리를 탑재해 AI, HPC 소프트웨어 개수를 줄이고 프로그래밍 복잡성을 축소하도록 설계됐습니다.

엔비디아 A100 GPU에 포함된 AI워크로드와 HPC 애플리케이션 성능을 가속화하는 새로운 기능들:
- 3세대 텐서 코어
- 희소성 가속화
- 멀티 인스턴스 GPU
3세대 텐서 코어
엔비디아 A100 GPU에는 새로운 3세대 텐서 코어가 탑재됐는데요. 텐서 코어는 혼합 정밀도 행렬 곱셈누적(MMA) 계산을 한 번의 작업으로 수행할 수 있는 전문 고성능 컴퓨팅 코어로, AI 워크로드와 HPC 애플리케이션에 가속화된 성능을 제공합니다.
V100이 탑재된 엔비디아 DGX-1시스템에서 사용되는 1세대 텐서 코어는 FP16(반정밀도)와 FP32(단정밀도)의 혼합정밀 MMA로 가속화된 성능을 제공합니다. 최신 세대 DGX A100는 더 큰 행렬 규모를 통해 INT4와 바이너리(binary) 데이터 타입을 위한 성능 개선으로 V100 텐서 코어의 효율성을 높이고 성능을 2배 향상시켰습니다. 또한 A100 텐서 코어 GPU에 추가된 새로운 데이터 유형은 다음과 같습니다.
- TF32
- IEEE(국제전기전자학회) 표준을 따른 FP64
- BF16 (BF16/FP32 혼합정밀 텐서 코어 연산은 FP16/FP32혼합정밀 텐서 코어 연산과 동일한 속도로 처리돼 딥 러닝 훈련에 쓰일 수 있음)
구조화된 희소성
희소성은 신경망에 대해 다소 새로운 접근법으로 네트워크에서 요구하는 연결 수를 줄이고 리소스를 절약하면서 심층 신경망 모델의 역량을 확대할 것으로 예측됩니다. 엔비디아 기술은 A100 GPU로 구조화된 희소성을 통합하면서 신경망 개발 분야의 최선두를 달립니다.
구조화된 희소성을 갖춘 희소성 네트워크의 각각의 노드를 사용하면 동일한 량의 데이터 불러오기(fetch)와 연산 수행, 워크로드의 균형 있는 배분, 컴퓨팅 노드의 활용도 향상이 가능해집니다. 이 외에도 희소성을 사용해 다중 곱셈 연산의 2배 가속 등의 강점이 있는 행렬 압축(matrix compression)을 할 수 있습니다.
이런 성능을 통해 다양한 AI 네트워크에 걸쳐 텐서 코어 연산을 가속화하고 추론 훈련 외에도 FP 훈련의 처리량을 증가시킵니다.
- V100 기반 INT8 대비 20배 빠른 성능을 제공하는 A100 기반 INT8
- V100 기반 표준 FP32 FFMA 연산 대비 20배 빠른 성능을 제공하는 A100 기반 TF32 텐서 코어 연산
- HPC 애플리케이션을 위한 V100 기반 표준 FP64 연산 대비 5배 빠른 성능을 제공하는 IEEE 표준을 따르는 A100 기반 FP64 텐서 코어 연산
멀티 인스턴스 GPU
엔비디아 A100 GPU는 새로운 멀티 인스턴스 GPU(MIG) 기능을 탑재했습니다. MIG의 공간 분할 기능을 통해 단일의 A100 GPU의 물리적 자원을 최대 7개의 독립된 GPU 인스턴스로 분할할 수 있죠. 엔비디아 A100 GPU는 MIG기능으로 GPU 1대당 동시 진행되는 인스턴스(simultaneous instance)를 갖춘 V100 대비 최대 7배 빠른 처리량으로 서비스 품질을 보장합니다.
엔비디아 A100 GPU의 MIG 기능으로 병렬 컴퓨팅 워크로드는 개별 GPU 인스턴스가 고유의 메모리, 캐시 메모리, 스트리밍 멀티프로세스를 갖춘 것처럼, 독립된 GPU 메모리와 물리적 GPU 리소스를 사용할 수 있습니다. 이런 환경은 다수의 사용자가 동일한 GPU를 공유해 모든 인스턴스를 동시에 실행시킬 수 있어 GPU 효율성이 극대화되죠.
DGX A100시스템에서 GPU의 개수에 상관없이 MIG 기능을 선택적으로 사용할 수 있습니다. 모든 GPU가 MIG를 사용할 필요는 없죠. 그러나 DGX A100 시스템의 모든 GPU가 MIG 기능이 있어 최대 56명의 사용자가 GPU 가속의 강점을 모두 동시에 개별적으로 사용할 수 있습니다.MIG 기능을 효율적으로 사용하는 대표적인 사용 사례:
- GPU의 전체 성능을 요구하지 않는 소규모, 낮은 레이턴시(지연시간) 모델과 관련한 배치 사이즈의 멀티 추론 작업
- 모델 탐색용 주피터(Jupyter) 노트북
- 싱글 테넌트 다중 사용자와 기타 공유 리소스 사용
DGX A100에 A100 GPU 8개를 사용해 매우 다양한 워크로드 처리를 위해 GPU를 아래의 사례처럼 다양하게 구성 가능:
- GPU 4개로 AI 훈련
- GPU 2개로 HPC나 데이터 애널리스틱스
- GPU 2개로 MIG 모드를 통해 14개 MIG 인스턴스로 분할하여 각각 추론 작업 처리

3세대 NVLink 와 NVSwitch로 대용량의 복잡한 워크로드 가속
DGX A100 시스템은 3세대 엔비디아 NVLink 고속 연결로 A100 GPU를 서로 연결하는 6개의 2세대 엔비디아 NVSwitch 패브릭을 포함합니다. 각각의 A100 GPU는 12개의 NVLink 인터커넥트를 통해 6개 NVSwitch 노드 모두를 연결하는데, 이는 각 GPU와 각 스위치 간에 2개의 링크가 있다는 뜻입니다. 링크로 GPU 간에 통신할 수 있는 최대 대역폭을 제공하는 것이죠.
2세대 NVSwitch는 엔비디아 DGX-2 시스템에 처음 도입된 기존 버전 대비 2배 빠릅니다. 6개의 NVSwitch와 3세대 NVLink 인터커넥트가 결합돼 GPU 간의 통신의 대역폭을 최대 600 GB/s까지 늘릴 수 있는데요. 모든 GPU 간에 통신하는 경우 양방향의 총 데이터 전송량이 최대 4.8 TB/s까지 이르게 됩니다.

멜라녹스 ConnectX-6를 통한 최대 네트워킹 처리량
AI 딥 러닝과 HPC 연산 워크로드의 멀티 시스템 스케일링(scaling)에는 각 시스템의 중요한 GPU 성능에 매치되도록 멀티 시스템에서 GPU 간에 강력한 통신이 필요합니다. GPU 간 내부에서의 초고속 통신을 위한 NVLink 외에도, DGX A100 서버는 DGX A100 시스템의 초고속 클러스트 구축에 사용되는 8개의 단일 포트 멜라녹스 ConnectX-6 200Gb/s HDR 인피니밴드(InfiniBand) 포트로 구성됩니다(200-Gb/s Ethernet 포트로도 구성 가능).
GPU 간 데이터 이동에 가장 흔히 쓰이는 방법은 온보드 스토리지를 사용하거나 RDMA(remote direct memory access)를 통해 멜라녹스 ConnectX-6 네트워크 어댑터를 사용하는 것입니다. DGX A100는 I/O카드와 GPU간 일대일 관계로 연결되는데요. 이는 각각의 GPU가 네트워크에 다른 GPU 액세스 방해 없이 외부 소스에 직접 통신할 수 있다는 것을 의미합니다.
멜라녹스 ConnectX-6 I/O 카드는 HDR 인피니밴드나 200-Gb/s 이더넷으로 구성할 수 있어 유연하게 연결할 수 있습니다. 이를 통해 엔비디아 DGX A100은 여타의 노드와 클러스터링하여 낮은 레이턴시 고대역폭 인피니밴드 혹은 RoCE(RDMA over Converged Ethernet)를 사용해 HPC와 AI 워크로드를 실행할 수 있습니다.
DGX A100 GPU에는 외장 스토리지에 고속 연결을 위해 사용되는 이중포트 ConnectX-6 카드가 추가 탑재됐습니다. 또한 I/O 구성이 유연해 고속 네트워크로 연결된 스토리지의 다양한 옵션에도 연결할 수 있습니다.

DGX A100 서버 내 ConnectX-6 VPI 카드가 제공하는 기능:
- 포트당 200Gb/s (총 50Gb/s 또는 200Gb/s로 작동하는 4개의 데이터 레인)
• IBTA RDMA와 RoCE 기술
• 멀티 시스템에 걸쳐 대규모 계산을 가속화할 수 있는 낮은 레이턴시 통신, 내장된 기본 요소와 집합요소(collectives)
• 멀티 시스템 간에 최소한의 경합으로 동시에 데이터를 전송할 수 있는 고성능 네트워크 토폴로지 지원
• 멀티 시스템에서 GPU 간 직접 전송을 위한 인피니밴드를 통한 엔비디아 GPUDirect RDMA
최신 DGX A100 멀티 시스템 클러스터는 고도화된 멜라녹스 적응 라우팅과 샤프(Sharp) 집합 기술을 사용하는 팻트리(fat tree) 토폴로지 기반 네트워크를 사용해 각 시스템에서 다른 모든 시스템으로 원활히 라우팅되고 예측 가능하며 비경합 통신을 제공합니다.
팻트리는 각층의 여러 스위치를 통해 최상층에 있는 중앙 스위치로 연결되는 지점들이 있는 시스템들로 구성된 나무 구조형 네트워크 토폴로지입니다. 팻트리의 각각의 층은 모두 동일한 수의 링크를 갖춰 동일한 논-블록킹(non-blocking) 대역폭을 제공합니다. 팻트리 토폴로지는 컴퓨팅·딥러닝 애플리케이션에 공통적으로 있는 올-투-올(all-to-all) 또는 올-개더(all-gather) 유형의 집합요소(collectives)에 최고의 통신 바이섹션 대역폭과 낮은 레이턴시를 보장합니다.
엔비디아 DGX A100는 모든 DGX 시스템 중에 최고 속도의 I/O 아키텍처를 갖춰 확장가능한 AI 인프라 업계 표준인 엔비디아 DGX SuperPOD와 같은 대규모 AI 클러스터의 기본 구성요소의 역할을 합니다.
모든 PCIe Gen4가 탑재된 최초의 가속 시스템
엔비디아 A100 GPU는 총 252 GB/s에 대해 각각 31.5 GB/s를 제공하는 x16 PCIe Gen4 버스(bus)를 통해 PCI 스위치 인프라에 연결되어 PCIe 3.0/3.1의 대역폭을 두 배로 늘립니다. 이런 링크들은 멜라녹스ConnectX-6, NVMe 스토리지와 CPU에 대해 액세스를 제공합니다.
워크로드 훈련은 보통 정확도 향상을 위해 동일한 데이터세트를 반복해서 읽습니다. 데이터를 반복해서 전송하기 위해 모든 네트워크 대역폭을 사용하는 대신, 고성능 로컬 스토리지를 NVMe 드라이브와 함께 구축해 이 데이터를 캐싱(cache)합니다. 이는 데이터의 메모리 읽기 속도를 향상시키고 네트워크와 스토리지 시스템 혼잡도를 감소시킵니다.
각 DGX A100 시스템에는 RAID 1 볼륨에 구성된 이중 1.92TB NVMe M.2 boot OS SSD와 RAID 0 볼륨에 구성된 4개의 3.84TB PCIe gen4 NVMe U.2 캐시 SSD가 있습니다. 기본 RAID 0 볼륨은 총 용량이 15TB이지만, 총 용량 30TB에 4개의 SSD를 시스템에 추가할 수 있습니다. 이런 드라이브는 워크로드의 데이터 액세스 속도를 높이고 네트워크 데이터 전송을 낮추기 위해 CacheFS를 사용합니다.
DGX A100 시스템에는 부팅, 스토리지 관리, 딥 러닝 프레임워크 조정을 위해 2개의 CPU가 있습니다. 각 CPU는 최대 3.4GHz에서 실행되며 코어당 2개의 스레드가 있는 64개의 코어가 탑재되며 I/O 와 소켓 간 통신에 사용되는 128개의 PCIe Gen4 링크를 제공합니다. DGX A100 시스템은 1TB의 기본 메모리로 구성되며 2TB로 업그레이드할 수 있습니다.
DGX A100은 기존 DGX 시스템과 유사하게 작동온도가 5℃~30℃로 맞춰진 데이터센터에서 공랭되도록 설계됐습니다.
완벽히 최적화된 DGX 소프트웨어 스택
DGX A100 소프트웨어는 대규모 AI 워크로드 실행용으로 구축됐습니다. DGX A100 소프트웨어의 핵심 목표는 설정시에 최소한의 노력으로 DGX A100 상에 딥 러닝 프레임워크, 데이터 분석, HPC 애플리케이션을 구축하도록 돕는 것입니다. DGX A100 플랫폼 소프트웨어는 서버에 최소한의 OS와 드라이버 설치, NGC 프라이빗 레지스트리( NGC Private Registry)를 통해 이용가능한 모든 애플리케이션과 SDK 소프트웨어 프로비저닝을 중심으로 구성됩니다.
NGC 프라이빗 레지스트리는 사전 훈련된 모델, 모델 스크립트, 헬름(Helm) 차트, SDK와 더불어 딥 러닝, 머신 러닝, HPC 애플리케이션을 위한 GPU 최적화 컨테이너들을 제공합니다. NGC 프라이빗 레지스트리는 DGX 시스템에서 개발되고 테스트되고 조정됐습니다. 또한 DGX-1, DGX-2, DGX 스테이션(Station), DGX A100와 같은 모든 DGX 제품과 호환됩니다.
또한 NGC 프라이빗 레지스트리는 기업 내에서 커스텀 컨테이너, 모델, 모델 스크립트, 헬름 차트를 안전하게 저장하고 공유할 수 있는 공간입니다. 더 자세한 사항은 ‘NGC 프라이빗 레지스트리로 엔드투엔드 AI 워크플로우의 보안과 속도 향상시키기’를 클릭해 살펴보세요.
다음의 그림 6은 위의 요소들이 DGX 소프트웨어 스택에 구성된 모양을 보여줍니다.
DGX 소프트웨어 스택의 주요 구성요소:
- GPU 가속 도커(Docker) 컨테이너를 구축하고 실행시키는 엔비디아 컨테이너 툴킷. 툴킷에는 컨테이너를 자동으로 구성하고 엔비디아 GPU를 활용할 수 있는 컨테이너 런타임 라이브러리와 유틸리티 포함
- GPU 가속 컨테이너가 지원하는 기능:
- PyTorch, MXNet, TensorFlow 등의 훈련용 딥 러닝 프레임워크
- TensorRT 등 추론 플랫폼
- 엔드투엔드 데이터 사이언스와 분석 파이프라인을 전적으로 GPU에서 실행할 수 있도록 한 소프트웨어 라이브러리 제품군, 래피즈(RAPIDS)와 같은 데이터 애널리틱스
- CUDA-X HPC, OpenACC, CUDA와 같은 고성능 컴퓨팅(HPC)
- 각각의 GPU 가속 컨테이너 내에 구축된 엔비디아 CUDA 툴킷은 고성능 GPU 가속 애플리케이션을 생성하는 개발 환경임. CUDA11을 사용해 소프트웨어 개발자와 데브옵스(DevOps) 엔지니어가 새로운 엔비디아 A100 GPU의 이점을 누릴 수 있는 혁신적인 주요 기능은 다음과 같음:
- 선형 대수 · FFT 행렬 곱셈을 위한 CUDA 라이브러리의 새로운 입력 데이터 유형 형식, 텐서 코어, 성능 최적화 지원
- DGX 소프트웨어 스택의 일부인 리눅스(Linux) 운영 체제에서 MIG 인스턴스 구성 및 관리
- 업무 그래프, 비동기 데이터 이동, 미세 조정된 동기화, L2 캐시 레지던시(residency) 컨트롤을 위한 프로그래밍과 API
자세한 사항은 여기를 클릭해 CUDA 11 기능을 살펴보세요.
성능의 게임 체인저
DGX A100는 혁신적인 기능과 균형 잡힌 시스템 설계로 구축돼 딥 러닝 훈련과 추론에서 획기적 성능을 제공합니다. 그림 7에 담긴 그래프는 다음과 같은 성능을 보여줍니다.
- DGX-1과 같은 8개의 V100 GPU시스템보다 훈련 성능 6배 향상. DGX-1가 FP32 정밀도를 사용해 초당 216 시퀀스 성능을 보이는 반면 DGX A100는 TF32정밀도를 통해 초당1289 시퀀스 달성
- CPU 서버의 172배에 달하는 추론 성능 제공. 구조적 희소성을 갖춘 INT8를 사용하는 DGX A100는 동일한 INT8를 사용하는 2개의 인텔 플래티늄(Intel Platinum) 8280 CPU 서버의 초당 58 TOPS(초당 1조회)과 대비해 최대 10페타OPS(페타=1000조)의 추론 컴퓨팅 성능 제공
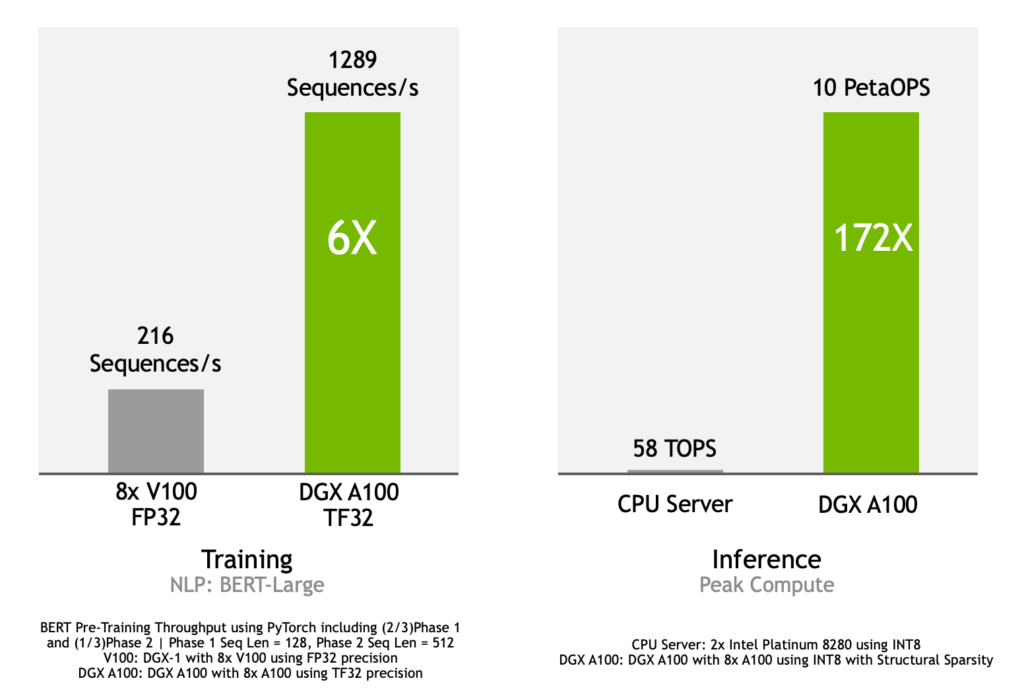
벤치마크의 세부 사항은 다음과 같습니다.
훈련:
- TF32 정밀도의 엔비디아 A100 GPU가 8개 탑재된 DGX A100 대비 FP32 정밀도의 엔비디아 V100 GPU가 8개 탑재된 DGX-1T시스템
- 딥러닝 언어 모델: 대중화된 PyTorch 프레임워크에 최고로 진보된 AI 언어 모델인 BERT(Bidirectional Encoder Representations from Transformer)의 대규모 버전
- (2/3) 단계 1과 (1/3) 단계 2 | 단계 1 시퀀스 길이 = 128, 단계 2 시퀀스 길이 = 512를 포함한 PyTorch를 사용해 처리량 사전 훈련
- 추론:
- 구조 희소성을 갖춘 INT8을 사용하는 엔비디아 A100 GPU 8개가 탑재된 DGX A100 시스템 대비 INT8을 사용하는 인텔 플래티넘 8280 2개를 탑재한 CPU 서버
혁신적인 A100 GPU가 대규모 컴퓨팅 성능, 대형 DRAM로의 고대역폭 액세스, 빠른 인터커넥트 기술과 결합돼 BERT같은 복잡한 네트워크를 극적으로 가속화하는 데 최적화된 엔비디아 DGX A100 시스템을 구축합니다.
단일 DGX A100시스템은 복잡한 모델을 처리하는 5페타 플롭스(FLOP) AI 컴퓨팅 성능을 제공합니다. BERT의 대형 모델 크기는 대량의 메모리가 필요하며 각 DGX A100는 320 GB의 고대역폭 GPU 메모리를 제공합니다. NVLink, NVSwitch, 멜라녹스 네트워킹과 같은 엔비디아 인터커넥스 기술들은 모든 GPU를 하나로 통합해 효율적인 스케일링을 위한 고대역폭 통신으로 대형 AI 모델에서 작동합니다.
DGX A100는 INT8의 텐서 코어 가속과 엔비디아 A100 GPU의 구조적 희소성을 통해 추론 워크로드를 새로운 차원으로 이끌었습니다. A100 GPU의 MIG 기능을 통해 특정한 워크로드에 적합한 크기의 리소스를 할당할 수 있습니다.
엔비디아 DGXpert 직접 액세스
엔비디아 DGXpert 프로그램은 수천번의 DGX 시스템 구축 경험과 풀스택 AI 개발에 전문지식을 갖춘 14,000이 넘는 AI 전문가들로 구성됐습니다. 이들은 시스템 설계, 플래닝, 데이터 센터 설계, 워크로드 테스팅, 작업 스케줄링, 리소스 관리, 지속적 최적화 등의 전문기술을 제공합니다.
엔비디아 DGX A100 혹은 기타 DGX 시스템을 갖춘다면 DGXpert의 AI 전문가들에게 직접 액세스할 수 있습니다. 이 프로그램은 사내 AI 전문성을 보완하고 기업 수준의 플랫폼을 뛰어난 AI 분야 인재들과 연결하여 조직의 AI 프로젝트 목표를 달성하도록 지원합니다.
요약
DGX A100 혁신은 개발자, 연구자, IT 관리자, 비즈니스 리더 등이 가능성의 지평을 넓히고 프로젝트와 조직에 걸쳐 AI의 강점을 최대로 활용할 수 있도록 지원합니다.
더욱 자세한 내용은 다음 웹페이지를 참조하세요.
- 엔비디아 DGX A100 웹페이지
- 엔비디아 DGX A100 데이터 시트
- 엔비디아 암페어 아키텍처(Ampere Architecture) 분석 게시글
2020년 5월 20일 오전 9시(태평양 표준시)에 웨비나에서 생방송으로 열린 GTC 2020를 찾아보시면 엔비디아 부사장 겸 DGX 시스템 총책임자 찰리 보일(Charlie Boyle), 컴퓨팅 소프트웨어 부사장 크리스토퍼 램(Christopher Lamb), GPU 시스템 엔지니어링 부사장 라지브 자이아반트(Rajeev Jayavant)이 엔비디아 DGX A100에 대해 논의하는 세션을 보실 수 있습니다.