
기후 변화의 영향 또한 완화해야 하는 상황에서 데이터센터의 효율 개선이 절실합니다. 데이터센터들은 연간 200테라와트시가 넘는 에너지를 사용하고 있으며, 이는 전세계 에너지 소비량의 약 2%에 해당하는데요.
고효율 슈퍼컴퓨터를 선별하는 그린500(Green 500)이 최근 새롭게 발표한 순위는 가속 컴퓨팅의 높은 에너지 효율을 다시 한번 실감하게 했습니다. 가속 컴퓨팅은 그린500의 상위 30대 시스템 일체에서 이미 사용되고 있으며, 에너지 효율에 어마어마한 영향을 미칩니다.
추산에 따르면 슈퍼컴퓨터 톱500(TOP500)에 드는 시스템들의 구동에는 연간 5테라와트시 이상, 다시 말해 7억5천만 달러 상당의 에너지가 필요합니다.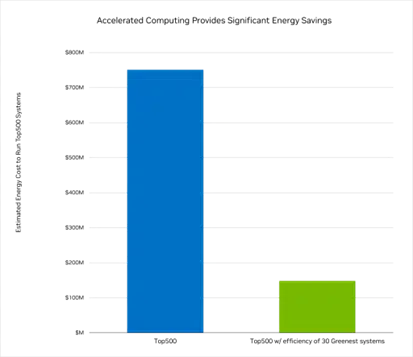
그러나 이들이 톱500 순위 내 가장 친환경적인 상위 30대 시스템만큼 효율적일 수 있다면 해당 비용을 80% 넘게 절감해 1억5천만 달러 수준으로 낮추게 됩니다. 이는 4테라와트시의 에너지 절약을 의미하죠.
역으로 이 슈퍼컴퓨터들이 톱500 시스템의 전력 예산(power budget)에 친환경성 상위 30대 시스템의 효율을 갖춘다면 현재보다 5배가량 향상된 성능을 제공할 수 있습니다.
그린500의 최신 순위에서 특히 돋보이는 효율성 개선은 이제 겨우 시작일 뿐입니다. NVIDIA는 CPU와 GPU, 소프트웨어와 시스템 포트폴리오 전반의 지속적인 에너지 효율 개선을 향해 질주하고 있습니다.
NVIDIA Hopper의 그린500 데뷔
최신 그린500의 상위 30대 슈퍼컴퓨터 중 23개 시스템이 NVIDIA 테크놀로지를 활용합니다.
그 중에서도 단연 돋보이는 건 뉴욕 플랫아이언 연구소(Flatiron Institute)의 슈퍼컴퓨터인데요. NVIDIA Hopper H100 GPU와 레노버(Lenovo)로 구축한 공랭식 싱크시스템(ThinkSystem)을 갖추고 그린500의 1위에 올랐습니다.
그린500의 설명에 따르면 헨리(Henri)라는 이름을 가진 이 슈퍼컴퓨터는 와트당 650억 배정밀도의 부동 소수점 연산을 제공합니다. 컴퓨터 기반 천체물리학과 생물학, 수학, 신경과학, 양자물리학의 여러 과제들을 해결해 나갈 예정이죠.
NVIDIA Hopper GPU 아키텍처 기반 H100 Tensor Core GPU의 경우, 이전 세대 A100 GPU와 비교해 AI 성능은 최대 6배, HPC 성능은 최대 3배까지 개선해 놀라운 효율을 달성하도록 설계됐습니다. 여기에 사용된 2세대 Multi-Instance GPU 테크놀로지는 GPU를 더 작은 컴퓨팅 유닛으로 분할해 데이터센터 사용자의 GPU 클라이언트 수를 획기적으로 늘립니다.
또한 올해 슈퍼컴퓨팅 컨퍼런스(SC22)의 전시장에는 아수스(ASUS)와 아토스(Atos), 델 테크놀로지스(Dell Technologies), 기가바이트(GIGABYTE), 휴렛팩커드 유한회사(Hewlett Packard Enterprise), 레노버, QCT, 슈퍼마이크로(Supermicro) 등 NVIDIA의 최신 테크놀로지를 장착한 새로운 시스템들이 가득합니다.
톱500에서 신규 슈퍼컴퓨터로는 가장 빠른 속도를 자랑한 레오나르도(Leonardo)는 비영리 컨소시엄 시네카(Cineca)가 구축과 관리를 주관했으며, 약 14,000개의 NVIDIA A100 GPU로 구동됩니다. 이 시스템은 톱500에서 4위를 차지했습니다.
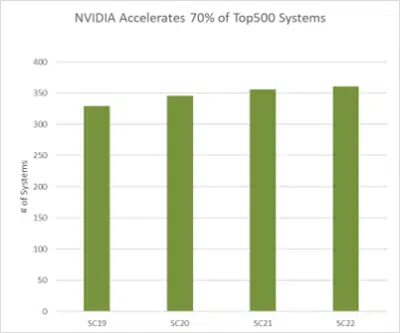
종합적으로 보면 톱500 순위 내 361개 시스템, 신규 슈퍼컴퓨터의 90%가 NVIDIA 테크놀로지를 활용하고 있습니다(그래프 참조).
차세대 가속 데이터센터
NVIDIA는 가속 데이터센터의 에너지 효율과 성능을 더욱 강화할 새로운 컴퓨팅 아키텍처도 개발 중입니다.
올해 초 발표된 Grace CPU와 Grace Hopper 슈퍼칩은 NVIDIA 가속 컴퓨팅 플랫폼의 에너지 효율을 한 단계 진화시킬 것입니다. Grace CPU 슈퍼칩은 Grace CPU의 놀라운 효율과 저전력 LPDDR5X 메모리에 힘입어 기존 CPU의 와트당 성능을 2배까지 향상합니다.
1메가와트 규모의 HPC 데이터센터가 전체 전력의 20%를 CPU 분할에, 나머지 80%를 Grace와 Grace Hopper의 가속화에 할당한다고 가정하면, 유사하게 분할된 x86 기반 데이터센터 대비 동일한 전력 예산으로 1.8배 많은 작업을 수행할 수 있습니다.
추가적 에너지 효율 달성하는 DPU
Grace와 Grace Hopper, 그리고 NVIDIA의 네트워킹 테크놀로지는 시뮬레이션의 활용도 증가가 슈퍼컴퓨팅 서비스의 수요를 가속하듯 클라우드 네이티브 슈퍼컴퓨팅의 필요성을 높이고 있습니다.
NVIDIA BlueField-3 DPU 기반 Quantum-2 InfiniBand 플랫폼은 클라우드 컴퓨팅 사업자와 슈퍼컴퓨팅 센터에 필요한 최고의 성능과 광범위한 접근성, 강력한 보안을 제공합니다.
최근의 백서에 따르면 NVIDIA의 이 같은 테크놀로지는 DPU가 네트워킹과 보안, 스토리지 또는 기타 인프라 기능과 제어부 애플리케이션의 오프로드/가속을 통해 서버의 전력 소비를 최대 30%까지 절감할 수 있음을 입증했습니다.
서버의 부하 증가로 절약이 가능한 전력량도 늘어 3년의 수명 주기를 가진 서버 1만 개를 보유한 대형 데이터센터의 경우, 500만 달러에 달하는 전력비를 손쉽게 절감하고 냉각과 전력 전달, 랙 공간과 서버의 자본 비용을 추가로 줄일 수 있습니다.
DPU 기반 가속 컴퓨팅을 응용한 네트워킹과 보안, 스토리지 작업은 데이터센터의 에너지 효율 강화로 가는 또 하나의 커다란 혁신입니다.
고효율의 미래
이러한 혁신은 데이터 애널리틱스와 AI, 물리 기반 시뮬레이션이 새로운 과학 기법으로 발빠르게 자리잡는 가운데 등장했으며, 차세대 과학 혁신에서 고효율 컴퓨터의 중요성을 더욱 강화합니다.
NVIDIA는 이 새로운 접근 방식에 최적화된 한편, 성능과 효율 모두를 잡을 종합적이고 고성능의 컴퓨팅 플랫폼을 통해 우리 모두를 이롭게 할 중차대한 발견들의 유용한 도구들을 제공합니다.
추가 자료
아래의 블로그에서 추가적인 내용을 더 확인해보세요.