
AI와 고성능 컴퓨팅(HPC), 데이터 애널리틱스의 복잡성이 날로 증가함에 따라 대규모 언어 모델을 비롯한 일부 모델의 경우 파라미터의 수가 수조 개에 달하기도 하는데요.
NVIDIA Hopper 아키텍처는 거대한 컴퓨팅 파워와 고속 메모리로 차세대 AI 워크로드들을 가속하도록 새롭게 구축되어 날로 커져가는 네트워크와 데이터세트의 처리를 지원합니다.
새로운 Hopper 아키텍처에 포함된 트랜스포머 엔진(Transformer Engine)은 AI의 성능과 기능을 대폭 강화하고, 대규모 모델의 훈련을 수 일 혹은 수 시간 내에 마칠 수 있게 도와줍니다.
트랜스포머 엔진으로 AI 모델 훈련하기
트랜스포머 모델은 버트(BERT)나 GPT-3처럼 오늘날 널리 사용되는 언어 모델의 중추입니다. 원래 자연어 처리 분야의 활용 사례를 위해 개발됐지만, 이제 컴퓨터 비전과 신약 개발 등의 여러 영역으로 적용 범위가 확대되고 있습니다.
이 같은 모델들은 규모의 팽창을 거듭하며 수조 개의 파라미터를 보유하게 됐는데요. 이로 인해 계산할 양이 어마어마하게 늘었고, 그 결과 훈련에만 수개월의 시간이 소요되고 있습니다. 기업 차원에서 이는 상당한 부담이죠.
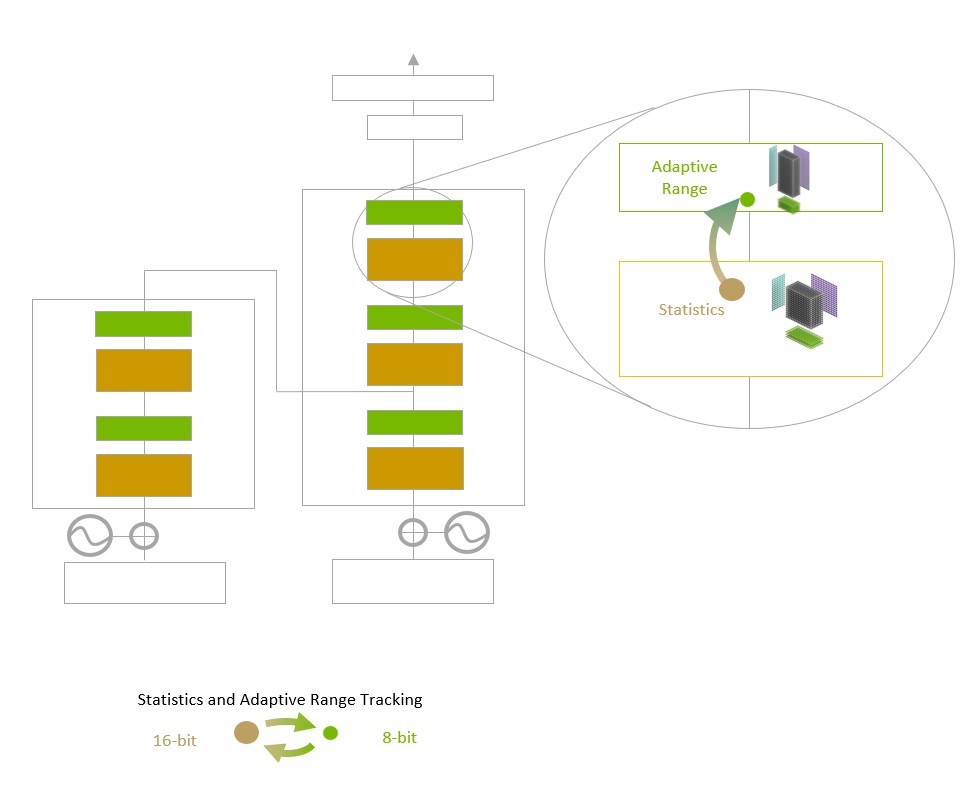
트랜스포머 엔진은 16비트 부동 소수점 정밀도와 새롭게 추가된 8비트 부동 소수점 데이터 포맷을 고급 소프트웨어 알고리즘과 결합해 AI의 성능과 기능을 향상시킵니다.
AI 훈련은 3.14처럼 소수점 단위로 이루어진 부동 소수점 숫자에 의존합니다. NVIDIA Ampere 아키텍처에 도입된 TensorFloat32(TF32) 부동 소수점 포맷은 현재 텐서플로우(TensorFlow)와 파이토치(PyTorch) 프레임워크에서 32비트 기본 포맷으로 사용되고 있습니다.
AI 부동 소수점 연산의 대부분은 16비트의 “반(half)” 정밀도(FP16)와 32비트의 “단(single)” 정밀도(FP32), 그리고 특수 연산의 경우 64비트의 “배(double)” 정밀도(FP64)를 사용합니다. 이 연산을 8비트로 줄임으로써 트랜스포머 엔진은 더 대규모의 네트워크를 더 신속히 훈련할 수 있습니다.
노드를 고속으로 직접 연결하는 NVLink Switch 시스템 등 Hopper 아키텍처의 신기능들과 H100 가속 서버 클러스터를 병용하면 거대 네트워크를 기업이 원하는 속도로 훈련할 수 있게 될 것입니다.
트랜스포머 엔진 이해하기
트랜스포머 엔진은 AI 모델의 빌딩 블록으로 널리 쓰이는 트랜스포머 기반 모델들의 훈련을 가속하도록 맞춤형으로 고안된 NVIDIA Hopper Tensor Core 테크놀로지와 소프트웨어를 사용합니다. 이 Tensor Core들은 FP8과 FP16의 혼합 포맷을 적용해 트랜스포머의 AI 계산을 획기적으로 가속하죠. FP8에서 Tensor Core 연산의 처리량은 16비트 연산 처리량의 2배입니다.
모델들은 정밀도를 지능적으로 관리해 정확도를 유지하는 한편, 보다 작고 빠른 숫자 포맷 수준의 성능을 확보해야 합니다. 이를 위해 트랜스포머 엔진은 NVIDIA가 조정해둔 맞춤형 휴리스틱(heuristics)으로 FP8과 FP16 계산 사이를 동적으로 오가면서 각 레이어 내 정밀도에 맞춰 리캐스팅(re-casting)과 스케일링(scaling)을 자동으로 처리합니다.
NVIDIA Hopper 아키텍처는 또한 이전 세대의 TF32와 FP64, FP16, INT8 정밀도 대비 초당 부동 소수점 연산을 3배까지 향상시켜 4세대 Tensor Core의 성능을 강화합니다. 트랜스포머 엔진, 그리고 4세대 NVLink와 결합한 Hopper Tensor Core는 HPC와 AI 워크로드의 속도를 크게 개선합니다.
트랜스포머 엔진 활용하기
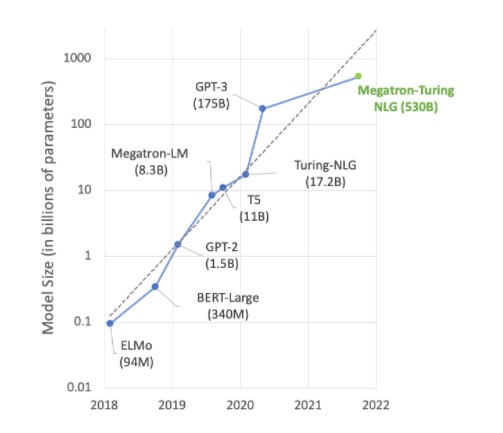
최첨단 AI 작업의 상당수가 메가트론(Megatron) 530B 같은 대규모 언어 모델 위주로 진행됩니다. 다음의 그래프는 최근 모델 규모의 확대를 보여주는데요. 이 같은 추세는 앞으로도 계속될 전망입니다. 다수의 연구자들이 자연어 이해와 기타 애플리케이션에서 수조 개의 파라미터를 보유한 모델을 사용 중이며, 이는 곧 AI 컴퓨팅 파워에 대한 끝없는 수요를 의미하는 것이기도 하죠.
이처럼 성장하는 모델의 필요를 충족하려면 고도의 연산 능력과 고속 메모리가 필요합니다. NVIDIA H100 Tensor Core GPU는 이 두 가지 요건 모두를 만족하며, 트랜스포머 엔진을 통한 가속화로 AI 훈련의 수준을 한 단계 더 업그레이드합니다.
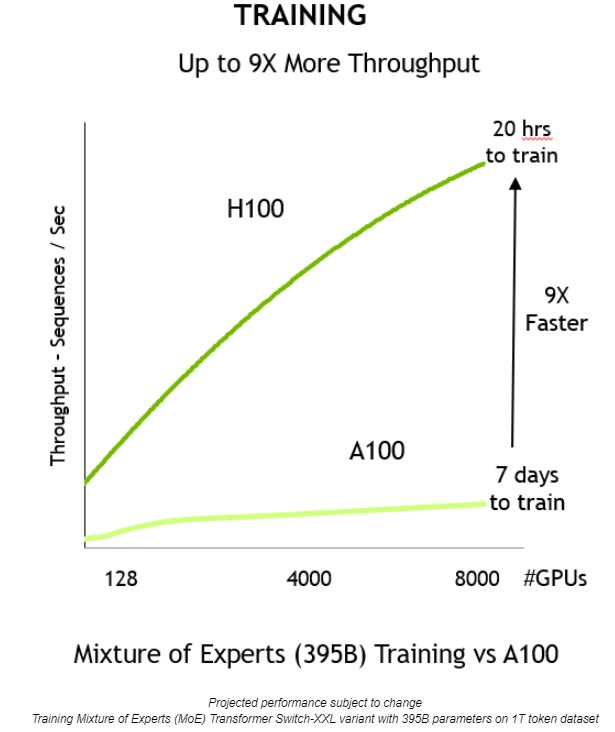
이 같은 혁신들이 서로 결합해 처리량을 개선하고, 훈련에 소요되는 시간 또한 일주일에서 20시간으로 9배가량 단축합니다.
트랜스포머 엔진을 사용하면 데이터 포맷을 변환하지 않고도 추론을 진행할 수 있습니다. 이전까지는 INT8이 최적의 추론 성능을 보장하는 정밀도였습니다. 그러나 이를 위해서는 훈련을 마친 네트워크를 INT8로 변환하는 최적화 프로세스가 필요한데요. 이 과정을 NVIDIA TensorRT 추론 옵티마이저가 간소화합니다.
FP8로 훈련한 모델의 경우, 이 변환 단계를 모두 건너뛰고 동일한 정밀도로 추론 연산을 수행할 수 있습니다. 또한 INT8 포맷의 네트워크와 마찬가지로, 트랜스포머 엔진을 사용해 배포된 모델들은 훨씬 적은 메모리 공간에서 실행이 가능합니다.
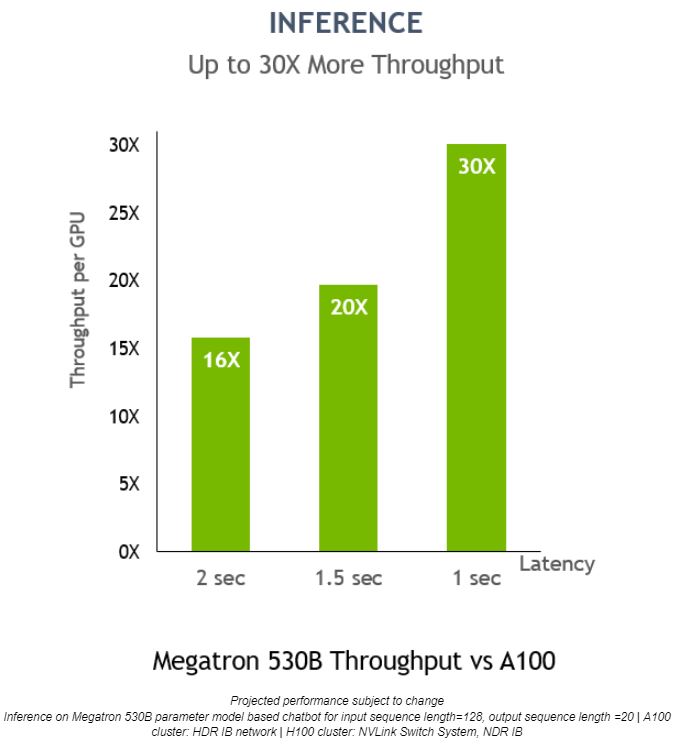
Megatron 530B 모델에서 NVIDIA H100의 GPU당 추론 처리량은 NVIDIA A100 대비 30배 많으며, 응답 지연시간(latency)은 1초입니다. 이는 NVIDIA H100이 AI 배포에 최적화된 플랫폼임을 보여주죠.
NVIDIA H100 GPU와 Hopper 아키텍처의 추가 정보를 NVIDIA 기술 블로그 포스팅(NVIDIA Technical Blog post)과 Hopper 아키텍처 백서(Hopper architecture whitepaper)에서 확인하세요.