
NVIDIA는 최신 MLPerf 결과에서 클라우드에서 엣지까지 AI 추론의 성능과 효율성을 새로운 차원으로 끌어올렸습니다.
MLPerf는 독립적인 타사 벤치마크로서 AI 성능에 대한 최종적인 측정치로 남아 있는데요. NVIDIA의 AI 플랫폼은 MLPerf 추론 3.0 벤치마크를 포함해 MLPerf가 시작된 이래 훈련과 추론 모두에서 지속적으로 리더십을 보여 왔습니다.
NVIDIA 창립자 겸 CEO인 젠슨 황(Jensen Huang)은 “3년 전 A100을 출시했을 때 AI 세계는 컴퓨터 비전이 지배했습니다. 하지만 이제는 생성형 AI가 등장했습니다. 이것이 바로 우리가 트랜스포머 엔진(Transformer Engine)을 통해 GPT에 특별히 최적화된 Hopper를 개발한 이유입니다. MLPerf 3.0은 A100보다 4배 더 높은 성능을 제공하는 Hopper를 강조합니다”라고 말했습니다.
젠슨 황은 “다음 단계 생성형 AI는 뛰어난 에너지 효율로 대규모 언어 모델을 훈련할 수 있는 새로운 AI 인프라를 필요로 합니다. 고객은 수만 개의 Hopper GPU를 NVIDIA NVLink와 InfiniBand로 연결해 AI 인프라를 구축하면서 대규모로 Hopper를 확장하고 있습니다. 업계는 안전하고 신뢰할 수 있는 생성형 AI의 새로운 발전을 위해 열심히 노력하고 있습니다. Hopper는 이러한 필수적인 작업을 가능하게 합니다”고 덧붙였죠.
최신 MLPerf 결과에 따르면 NVIDIA는 클라우드에서 엣지까지 AI 추론의 성능과 효율성을 새로운 차원으로 끌어올렸습니다.
특히, DGX H100 시스템에서 실행되는 NVIDIA H100 Tensor Core GPU는 생산에서 신경망을 실행하는 작업인 AI 추론의 모든 테스트에서 최고 성능을 제공했습니다. 소프트웨어 최적화 덕분에 GPU는 9월에 출시된 제품 대비 최대 54%의 성능 향상을 달성했죠.
헬스케어 분야에서 H100 GPU는 의료 영상용 MLPerf 벤치마크인 3D-UNet에서 9월 이후 31%의 성능 향상을 달성했습니다.
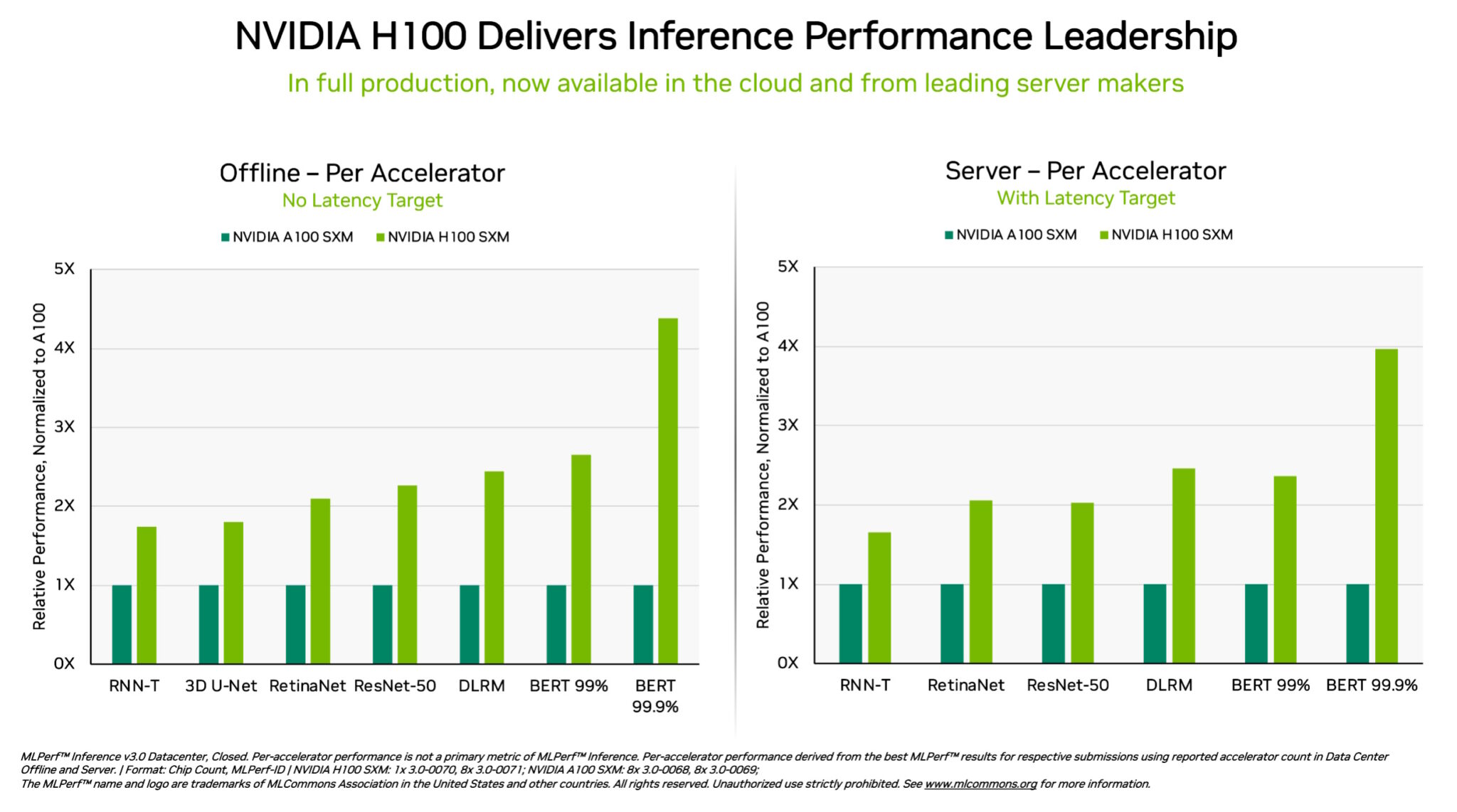
트랜스포머 엔진으로 구동되는 Hopper 아키텍처 기반 H100 GPU는 트랜스포머 기반 대규모 언어 모델인 BERT에서 탁월한 성능을 발휘해 생성형 AI의 광범위한 사용의 토대를 마련했습니다.
생성형 AI를 통해 사용자는 텍스트, 이미지, 3D 모델 등을 빠르게 만들 수 있습니다. 이는 스타트업부터 클라우드 서비스 제공업체에 이르기까지 다양한 기업이 새로운 비즈니스 모델을 구현하고 기존 비즈니스 모델을 가속화하기 위해 빠르게 도입하고 있는 기능이죠.
현재 수억 명의 사람들이 즉각적인 응답을 기대하며 트랜스포머 모델인 챗GPT(ChatGPT)와 같은 생성형 AI 도구를 사용하고 있습니다.
이러한 AI의 시대에는 추론 성능이 매우 중요한데요. 딥 러닝은 이제 거의 모든 곳에 배포되고 있으며 공장 현장부터 온라인 추천 시스템에 이르기까지 추론 성능에 대한 요구가 끊임없이 증가하고 있습니다.
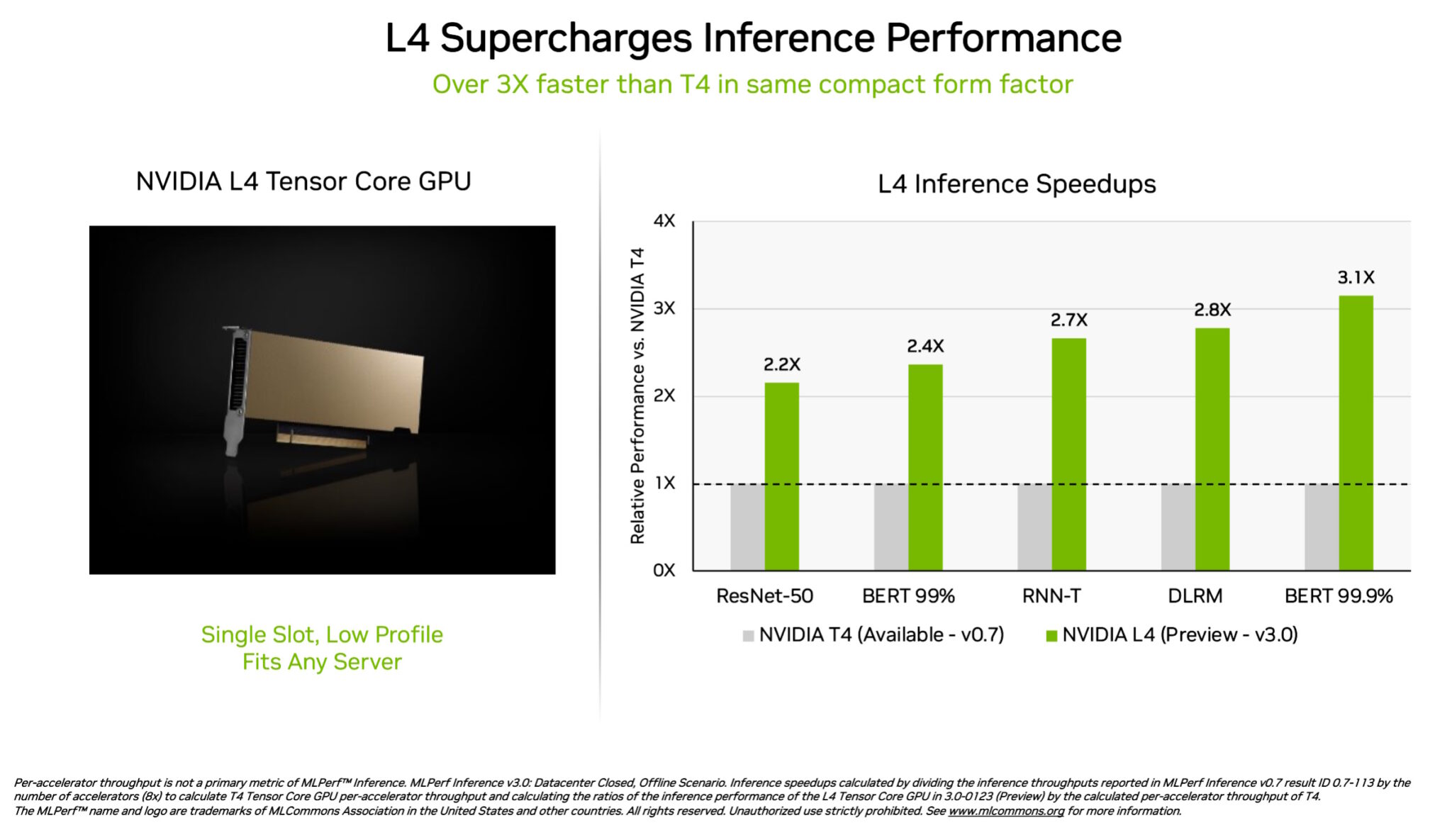
L4 GPU의 빠른 속도
NVIDIA L4 Tensor Core GPU는 이전 세대 T4 GPU보다 3배 이상 빠른 속도로 MLPerf 테스트에 데뷔했습니다. 프로파일이 낮은 폼 팩터(low-profile form factor)로 패키징된 가속기는 거의 모든 서버에서 높은 처리량과 짧은 지연 시간을 제공하도록 설계됐습니다.
L4 GPU는 모든 MLPerf 워크로드를 실행했습니다. 주요 FP8 형식을 지원하므로 성능에 민감한 BERT 모델에서 특히 뛰어난 결과를 보였죠.
L4 GPU는 탁월한 AI 성능 외에도 최대 10배 빠른 이미지 디코드, 최대 3.2배 빠른 영상 처리, 4배 이상 빠른 그래픽과 실시간 렌더링 성능을 제공합니다.
GTC 2023에서 발표된 이 가속기는 이미 주요 시스템 제조업체와 클라우드 서비스 제공업체에서 사용할 수 있습니다. L4 GPU는 GTC 2023에서 발표된 NVIDIA의 AI 추론 플랫폼 포트폴리오에 가장 최근에 추가된 제품입니다.
시스템 테스트에서 빛나는 소프트웨어, 네트워크
NVIDIA의 풀스택 AI 플랫폼이 새로운 MLPerf 테스트에서 리더십을 입증했습니다.
이른바 네트워크 분할 벤치마크는 데이터를 원격 추론 서버로 스트리밍합니다. 이 테스트는 기업 방화벽 뒤에 데이터를 저장한 채 클라우드에서 AI 작업을 실행하는 기업 사용자의 일반적인 시나리오를 반영합니다.
BERT에서 원격 NVIDIA DGX A100 시스템은 최대 로컬 성능의 96%까지 제공했으며, 일부 작업의 경우 CPU가 완료될 때까지 기다려야 하기 때문에 부분적으로 속도가 느려졌습니다. GPU로만 처리되는 컴퓨터 비전을 위한 ResNet-50 테스트에서는 100%를 기록했습니다.
두 결과 모두 NVIDIA Quantum Infiniband 네트워킹, NVIDIA ConnectX SmartNIC, NVIDIA GPUDirect와 같은 소프트웨어 덕분입니다.
엣지에서 3.2배의 성능 향상을 보여준 Orin
이와는 별도로 NVIDIA Jetson AGX Orin 시스템 온 모듈은 1년 전 결과에 비해 에너지 효율성은 최대 63%, 성능은 81% 향상됐습니다. Jetson AGX Orin은 배터리로 구동되는 시스템을 포함해 저전력 수준의 제한된 공간에서 AI가 필요할 때 추론을 제공합니다.

더 적은 전력을 소비하는 더 작은 모듈을 필요로 하는 애플리케이션의 경우, 벤치마크에서 첫 선을 보인 Jetson Orin NX 16G가 빛을 발했는데요. 이전 세대 Jetson Xavier NX 프로세서보다 최대 3.2배의 성능을 제공했습니다.
광범위한 NVIDIA AI 생태계
MLPerf 결과는 NVIDIA AI가 업계에서 가장 광범위한 머신 러닝 생태계의 지원을 받고 있음을 보여줍니다.
이번 라운드에는 10개 기업이 NVIDIA 플랫폼에 대한 결과를 제출했습니다. 여기에는 마이크로소프트 애저(Microsoft Azure) 클라우드 서비스, 에이수스(ASUS), 델 테크놀로지스(Dell Technologies), 기가바이트(GIGABYTE), H3C, 레노버(Lenovo), 네트릭스(Nettrix), 슈퍼마이크로(Supermicro), 엑스퓨젼(xFusion)을 비롯한 시스템 제조업체가 포함됐습니다.
이들의 연구는 사용자가 클라우드와 자체 데이터센터에서 실행되는 서버 모두에서 NVIDIA AI를 통해 뛰어난 성능을 얻을 수 있음을 보여주죠.
NVIDIA 파트너는 MLPerf가 AI 플랫폼과 공급업체를 평가하는 고객에게 유용한 도구라는 것을 알고 있기 때문에 MLPerf에 참여하는데요. 최신 라운드의 결과는 그들이 현재 제공하는 성능이 NVIDIA 플랫폼과 함께 성장할 것임을 입증합니다.
사용자에게 필요한 다목적 성능
NVIDIA AI는 데이터센터와 엣지 컴퓨팅에서 모든 MLPerf 추론 워크로드, 시나리오를 실행할 수 있는 유일한 플랫폼입니다. 다재다능한 성능과 효율성은 사용자를 진정한 승자로 만듭니다.
실제 애플리케이션은 일반적으로 실시간으로 답을 제공해야 하는 다양한 종류의 신경망을 많이 사용합니다.
예를 들어, AI 애플리케이션은 사용자의 음성 요청을 이해하고, 이미지를 분류하고, 추천한 후 사람 목소리가 담긴 음성 메시지로 응답을 전달해야 할 수 있습니다. 따라서 각 단계마다 다른 유형의 AI 모델이 필요합니다.
MLPerf 벤치마크는 이러한 워크로드와 기타 인기있는 AI 워크로드를 다룹니다. 따라서 IT 의사 결정권자는 이 테스트를 통해 신뢰할 수 있고 유연하게 배포할 수 있는 성능을 얻을 수 있죠.
테스트는 투명하고 객관적이기 때문에 사용자는 정보에 입각한 구매 결정을 내릴 때 MLPerf 결과를 신뢰할 수 있습니다. 이 벤치마크는 Arm, 바이두(Baidu), 페이스북 AI(Facebook AI), 구글(Google), 하버드(Harvard), 인텔(Intel), 마이크로소프트(Microsoft), 스탠포드(Stanford), 토론토 대학교(University of Toronto)를 포함한 광범위한 그룹의 지원을 받고 있습니다.
사용 가능한 소프트웨어
NVIDIA AI 플랫폼의 소프트웨어 계층인 NVIDIA AI Enterprise는 사용자가 인프라 투자에서 최적화된 성능을 얻을 수 있도록 보장할 뿐만 아니라 기업 데이터센터에서 AI를 실행하는 데 필요한 엔터프라이즈급 지원, 보안과 안정성을 제공합니다.
이 테스트에 사용된 모든 소프트웨어는 MLPerf 리포지토리에서 사용할 수 있으므로 누구나 이러한 세계적 수준의 결과를 얻을 수 있습니다.
최적화는 NVIDIA의 GPU 가속 소프트웨어용 카탈로그인 NGC에서 사용할 수 있는 컨테이너에 지속적으로 접혀 있습니다. 이 카탈로그에는 이번 라운드의 모든 출품작에서 AI 추론을 최적화하는 데 사용되는 NVIDIA TensorRT가 호스팅됩니다.
NVIDIA의 MLPerf 성능과 효율성을 촉진하는 최적화에 대해 자세한 내용은 개발자 블로그에서 확인하세요.