
조직이 AI 파일럿에서 프로덕션 AI 팩토리로 이동함에 따라, 인프라 의사 결정의 기준은 최고 사양의 칩 스펙에서 토큰당 비용으로 옮겨가고 있습니다. 즉, 달러당, 와트당, 그리고 요구되는 지연 시간 목표 내에서 얼마나 많은 유용한 토큰을 제공할 수 있는가입니다.
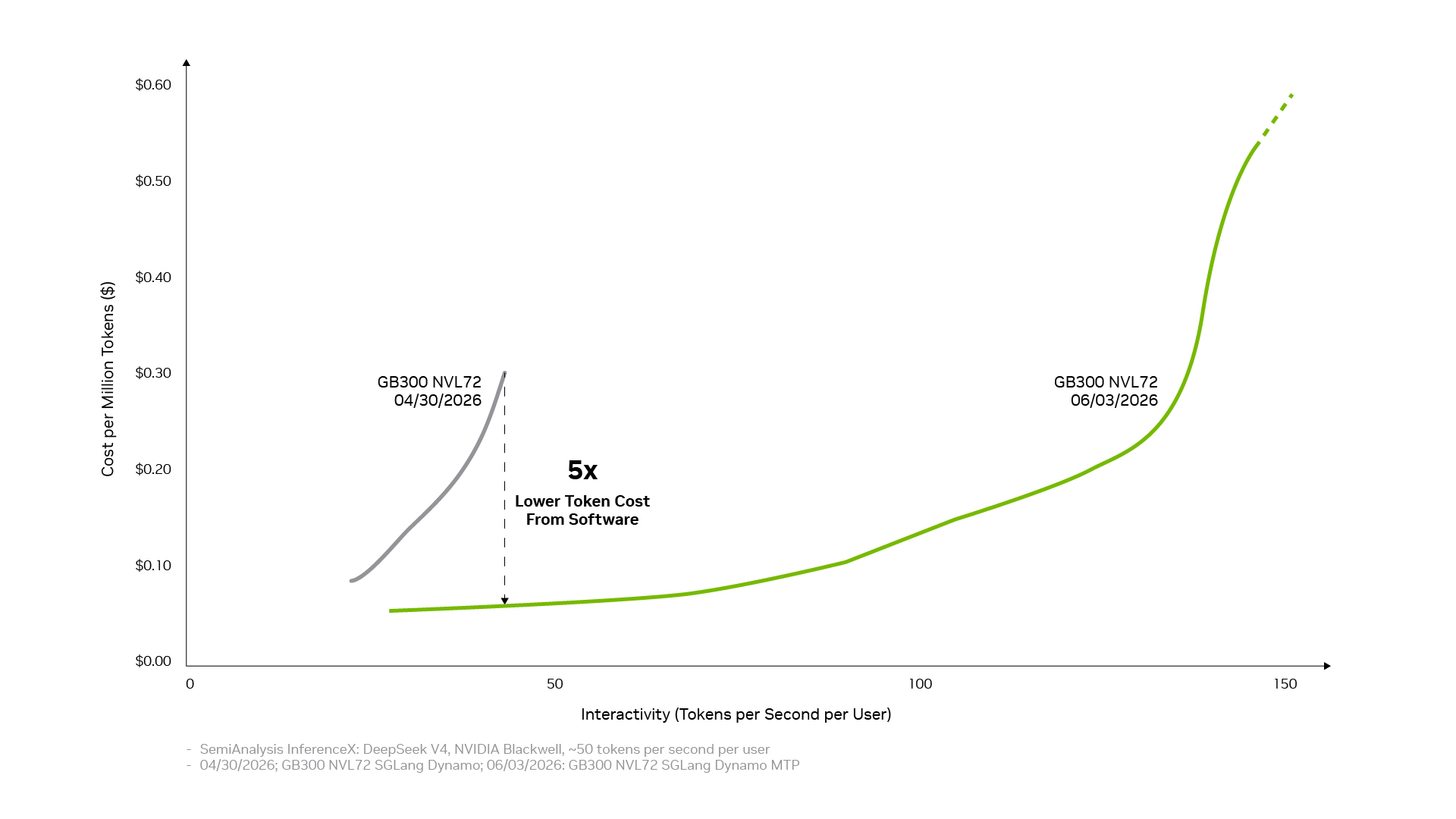
NVIDIA GPU, CPU, 네트워킹, 시스템과 함께 공동 설계되고 폭넓은 오픈 소스 생태계로 강화된 NVIDIA의 풀스택 추론 소프트웨어는 하드웨어 성능을 지속적으로 향상시키는데요, NVIDIA Blackwell 플랫폼에서 이 소프트웨어 스택은 단 한 달 만에 DeepSeek V4 모델의 토큰 비용을 최대 5배까지 절감했습니다.
주요 기업과 추론 제공업체들은 이미 Blackwell에서 NVIDIA 추론 소프트웨어 스택이 만들어내는 복합적 가치를 경험하고 있습니다:
- Baseten은 NVIDIA TensorRT-LLM 오픈 소스 라이브러리를 사용해 추론, 코딩, 롱 컨텍스트 워크로드를 위한 DeepSeek V4 Pro를 Blackwell GPU에서 서비스했으며, 독자적인 런타임 최적화를 적용해 초당 토큰 처리량을 최대 50%까지 높였습니다.
- Cognition은 NVIDIA Dynamo 추론 프레임워크를 사용해 추론 GPU를 관리하며, 인프라를 처음부터 구축할 필요 없이 강화 학습 워크로드를 확장할 수 있는 즉시 사용 가능한 경로를 팀에 제공합니다.
- Deep Infra는 NVIDIA 추론 소프트웨어 스택을 사용해 DeepSeek V4를 비롯한 프런티어 오픈 소스 모델을 출시 첫날(데이 제로)부터 Blackwell에서 고성능으로 서비스합니다.
- DigitalOcean은 Hippocratic AI가 Blackwell GPU에서 NVIDIA 추론 소프트웨어를 사용하도록 지원해 헬스케어 AI를 더 빠르고 효율적으로 서비스했으며, 1,000만 건의 환자 통화 전반에서 첫 응답까지의 시간을 0.5초 미만으로 유지하면서 추론 처리량을 30% 높였습니다.
- Together AI는 Blackwell에서 NVIDIA TensorRT-LLM을 사용해 Cursor가 실시간 코딩 경험을 위한 모델 최적화에서 프로덕션 엔드포인트에 이르는 과정을 가속하도록 지원했습니다.
소프트웨어가 추론 경제성에 중요한 이유
기존의 웹, 검색, 서비스형 소프트웨어(SaaS) 워크로드는 비교적 예측 가능했습니다. 사용자가 페이지를 불러오거나, 피드를 새로 고치거나, 비즈니스 레코드를 업데이트하는 식이었죠. 이러한 요청은 일반적으로 데이터베이스에서 읽거나 쓰는 유사한 소프트웨어 경로를 따랐고, 동일한 서버를 더 추가하는 방식으로 확장되었습니다.
그러나 에이전틱 AI는 다릅니다.
에이전틱 AI는 데이터센터 전반에 걸쳐 LLM, 도구, 메모리, 보안, 네트워킹, 가속 컴퓨팅을 아우르는 분산된 스테이트풀(stateful) 워크플로우를 실행합니다.
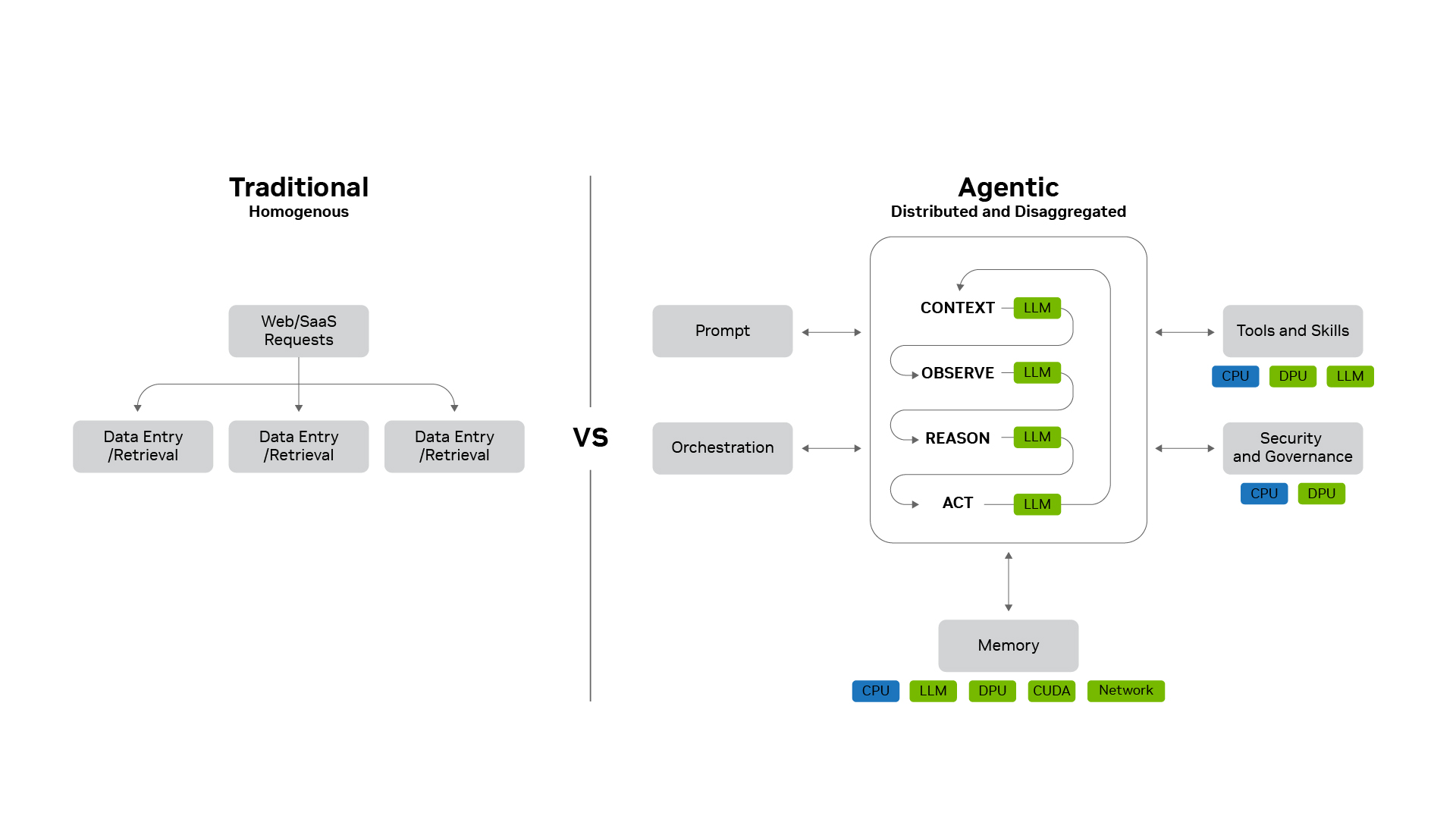
에이전트는 추론하고, 계획하고, 도구를 호출하고, 전문 하위 에이전트를 생성하며, 멀티턴 워크플로우 전반에서 방대한 컨텍스트를 관리할 수 있습니다. 이들은 하나의 요청을 수백 개의 하위 에이전트, 수천 개의 작업, 여러 개의 대규모 언어 모델에 걸쳐 GPU, CPU, DPU, 스토리지 시스템에서 실행되는 분산 컴퓨팅 문제로 전환합니다.
소프트웨어 스택은 이러한 복잡성이 낭비되는 용량으로 이어질지, 아니면 더 낮은 토큰당 비용으로 이어질지를 결정합니다.
토큰당 비용을 낮추는 것은 개별 최적화를 시스템 수준의 성능으로 전환하는 데서 비롯됩니다. NVIDIA의 추론 소프트웨어 스택은 다음 세 가지 계층을 연결해 이를 실현합니다:
- 프로덕션 운영(Production Operation): 분산 서빙, 오케스트레이션, 오토스케일링, 메모리 관리를 조율해 추론이 적절한 컴퓨팅 및 스토리지 리소스에서 실행되도록 합니다.
- 애플리케이션 가속(Application Acceleration): 컴퓨팅과 통신의 중첩, 커널 퓨전 같은 런타임 최적화를 활용해 개발자에게 튜닝과 커스터마이징의 여지를 제공하면서 모델을 고성능으로 실행합니다.
- 인프라 접근(Infrastructure Access): 개발자가 모든 디바이스 명령어 집합이나 데이터 전송 프로토콜을 직접 관리할 필요 없이 NVIDIA GPU, 네트워킹, 메모리, 시스템 기능을 개발자가 활용할 수 있도록 노출합니다.
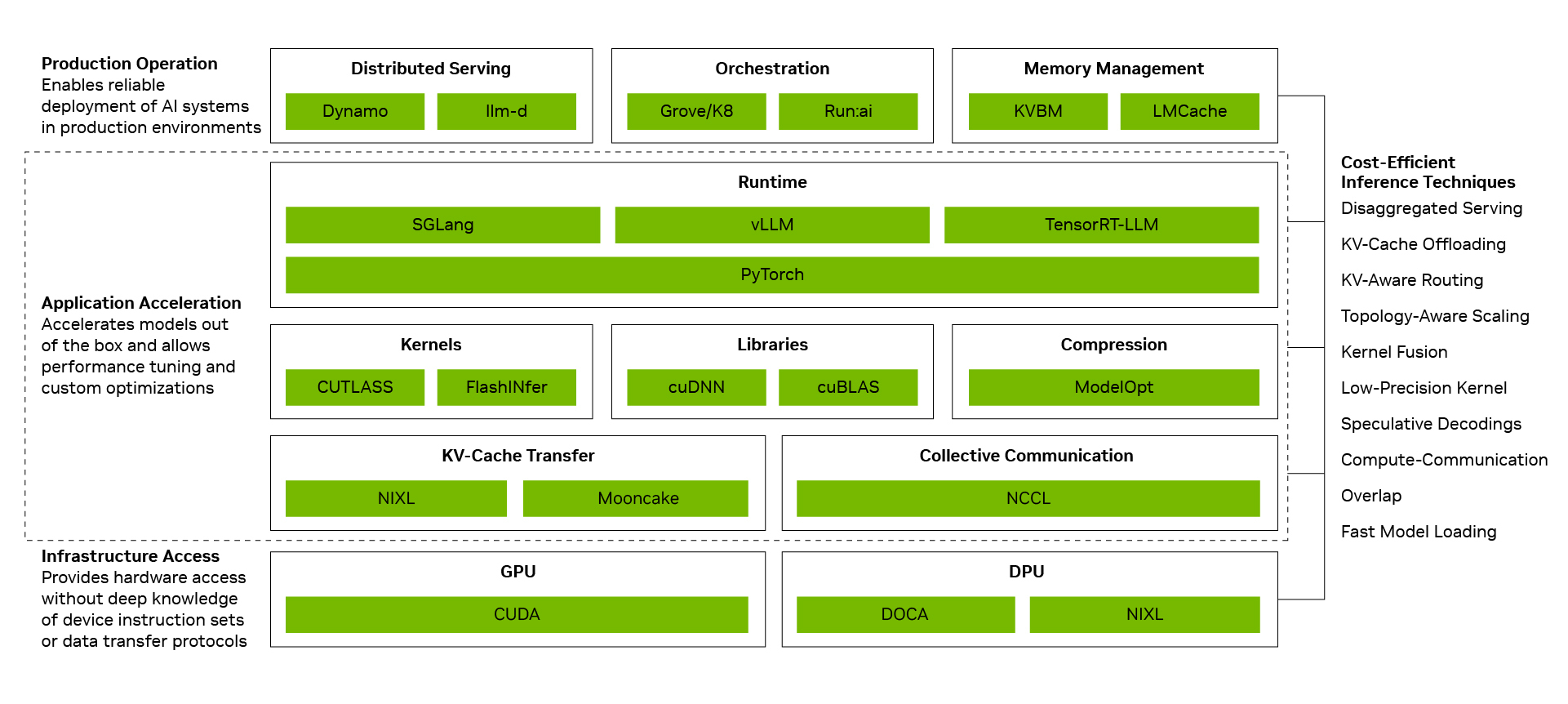
이러한 계층이 하나의 시스템으로 작동할 때, 개별 최적화는 복합적으로 누적됩니다.
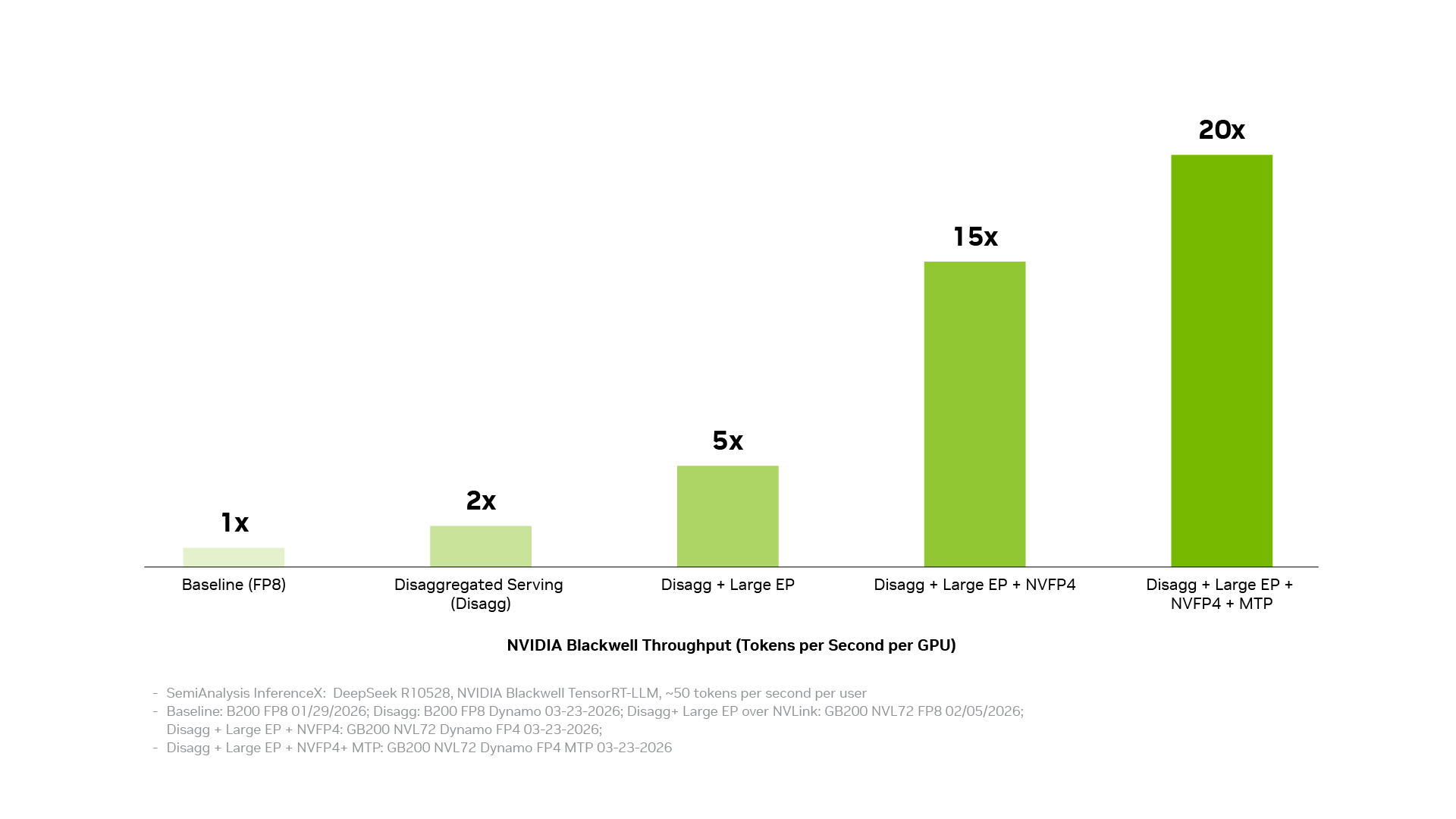
디스어그리게이티드 서빙(disaggregated serving), NVIDIA NVLink 인터커넥트 기술을 통한 대규모 전문가 병렬화(large expert parallelism), NVFP4 정밀도, 멀티 토큰 예측(multi-token prediction)은 각각 그 자체로 의미 있는 이점을 제공합니다. 이들을 결합하면 처리량이 최대 20배까지 증가합니다.
아래 차트는 그 결과를 보여줍니다. 프로덕션에서 이러한 이점을 확보하는 것은 복잡한 일이며, 프로덕션 운영과 모델 런타임에서 커널, 통신 라이브러리, 하드웨어 접근에 이르기까지 전체 추론 스택 전반의 조율이 필요합니다. NVIDIA의 추론 소프트웨어 스택은 이러한 계층이 함께 작동하도록 설계되어 각 최적화가 다른 최적화 위에 쌓일 수 있게 합니다.
오픈 소스가 풀스택 이점을 증폭합니다
바로 그 동일한 풀스택 기반이 오픈 소스 생태계에 의해 증폭됩니다. 오늘날 가장 널리 사용되는 오픈 소스 AI 프레임워크와 추론 프로젝트의 상당수는 NVIDIA CUDA 위에서 네이티브로 구축되어 있으며, 이는 새로운 연구와 소프트웨어 최적화가 출시 첫날(데이 제로)부터 NVIDIA GPU에서 선도적인 성능으로 실행됨을 의미합니다.
PyTorch가 대표적인 예입니다. 2016년 네이티브 CUDA 지원과 함께 출시된 PyTorch는 NVIDIA 아키텍처와 함께 발전해 왔으며, 개발자에게 Tensor Cores, Transformer Engine, NVFP4 같은 혁신 기술을 익숙한 프레임워크를 통해 직접 제공합니다.
기존 하드웨어에서 처리량을 최대 15배 높여주는 DFlash 스페큘레이티브 디코딩(speculative decoding)나 1080p 영상을 5초 이내에 생성하는 FastVideo 같은 혁신 기술이 PyTorch에 도입되면, 이는 NVIDIA에서 즉시 실행될 수 있어 AI 팩토리가 연구 성과를 더 낮은 토큰 비용으로 전환하도록 돕습니다.
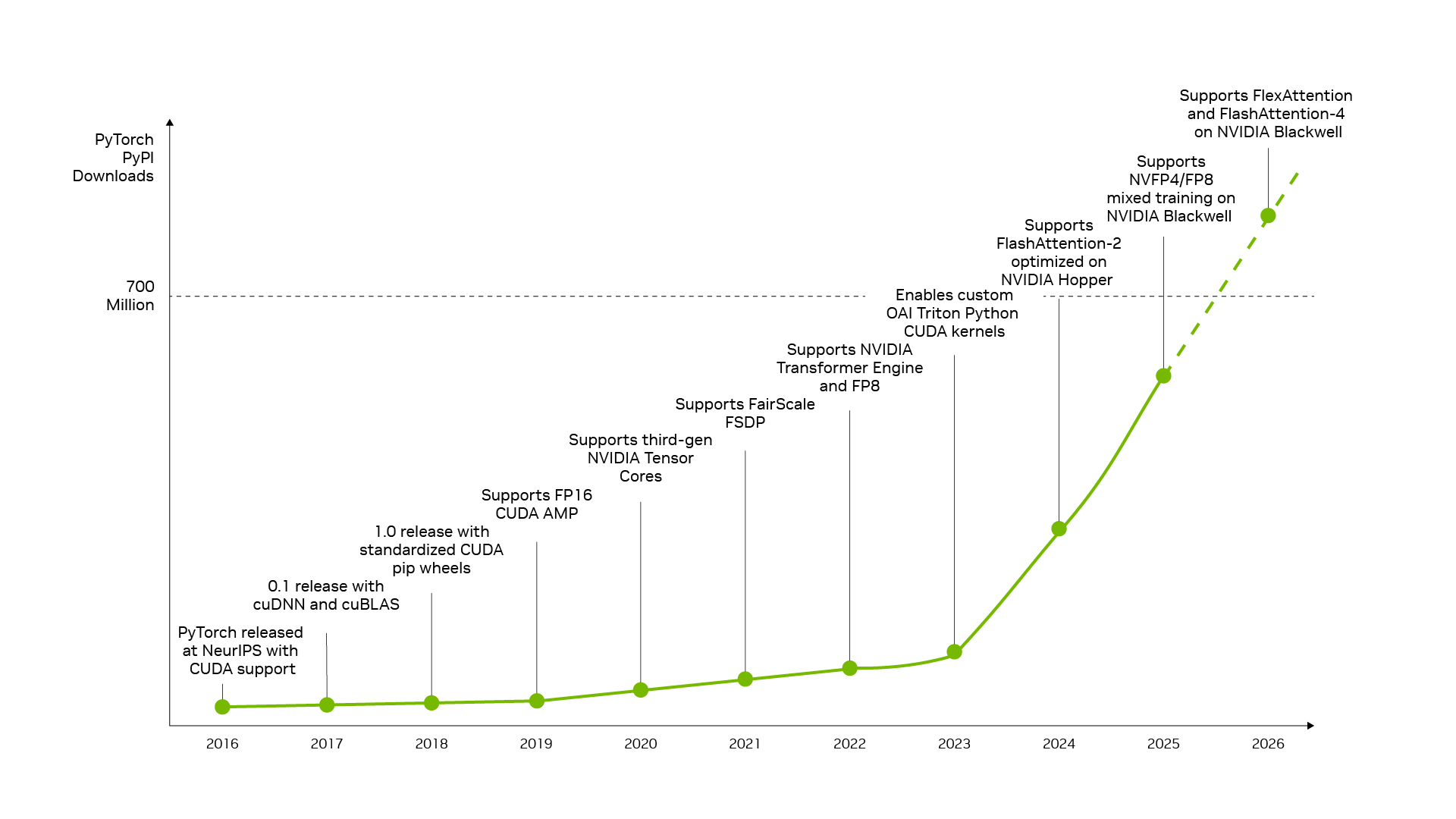
이와 동일한 오픈 소스 모멘텀 덕분에, DeepSeek V4 같은 새로운 프런티어 오픈 모델이 출시되면 vLLM, SGLang 같은 선도적인 추론 프레임워크가 NVIDIA Blackwell 아키텍처를 위한 데이 제로 배포 레시피를 갖추게 되어, 수백만 개의 Blackwell GPU 전반에서 해당 모델을 사용할 수 있습니다. 또한 이 덕분에 Blackwell에서의 DeepSeek V4 성능이 약 한 달 만에 vLLM과 SGLang 프레임워크 전반에서 최대 5배까지 향상되어, 토큰 비용을 이전 수준의 약 5분의 1로 절감했습니다.
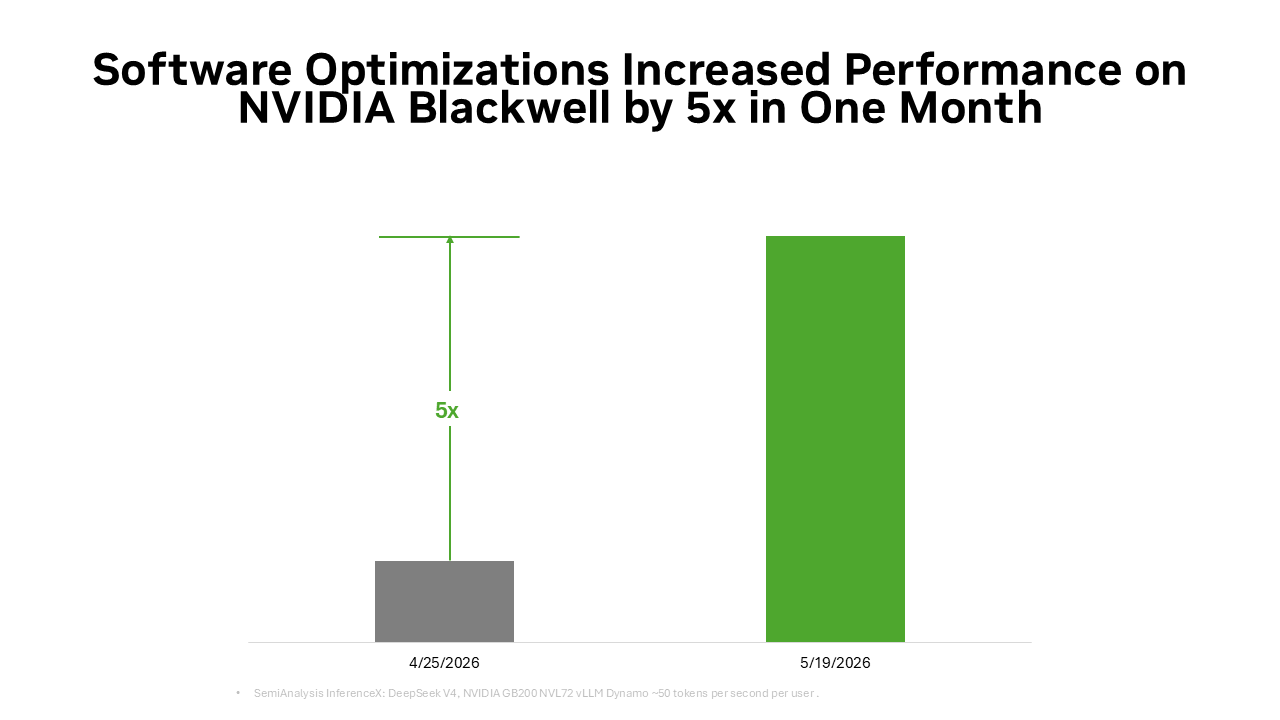
이것이 바로 오픈 소스 플라이휠(flywheel)입니다. 더 많은 개발자가 CUDA 네이티브 추론 경로를 최적화하고, 더 많은 프로덕션 배포가 생태계로 다시 피드백되며, 각 소프트웨어 개선은 제공되는 토큰 출력을 늘리는 동시에 시간이 지날수록 토큰당 비용을 낮춥니다.
소프트웨어가 하드웨어 성능을 어떻게 배가하는지 토크노믹스에 관한 NVIDIA AI 팟캐스트와 추론 솔루션 페이지에서 살펴보세요.