
거대 언어 모델과 이를 지원하는 애플리케이션을 통해 조직은 데이터 저장소에서 더 깊은 인사이트를 얻고 완전히 새로운 종류의 애플리케이션을 구축할 수 있는 전례 없는 기회를 얻을 수 있습니다.
그러나 이러한 기회에는 종종 쉽지 않은 도전도 따릅니다.
온프레미스와 클라우드 모두에서 실시간으로 실행되어야 하는 애플리케이션은 하나의 플랫폼 투자로 높은 처리량과 짧은 지연 시간을 동시에 만족시켜야 하기 때문에 데이터센터 인프라에 대한 니즈가 상당히 높습니다.
지속적인 성능 개선을 추진하고 인프라 투자 수익을 개선하기 위해 NVIDIA는 Meta의 Llama, Google의 Gemma, Microsoft의 Phi, 그리고 몇 주 전에 출시된 자체 NVLM-D-72B를 비롯한 최첨단 커뮤니티 모델을 정기적으로 최적화하고 있습니다.
끊임없는 향상
성능 향상을 통해 고객과 파트너는 더 복잡한 모델을 서비스하고 이를 호스팅하는 데 필요한 인프라를 줄일 수 있습니다. NVIDIA는 최신 LLM에서 최첨단 성능을 제공하기 위해 특별히 제작된 라이브러리인 TensorRT-LLM을 비롯하여 기술 스택의 모든 계층에서 성능을 최적화합니다. 매우 높은 정확도를 제공하는 오픈 소스 Llama 70B 모델을 개선하여 1년 이내에 이미 최소 지연 시간 성능을 3.5배 향상시켰습니다.
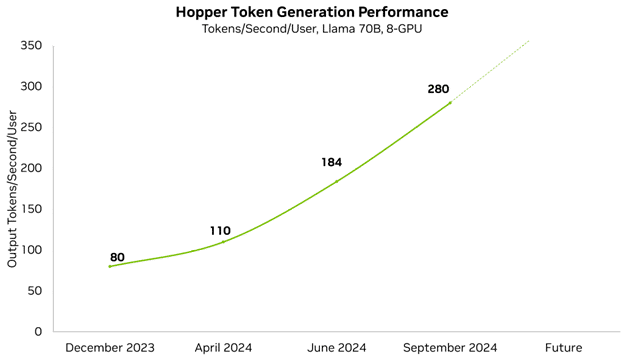
NVIDIA는 플랫폼 성능을 지속적으로 개선하고 있으며 정기적으로 성능 업데이트를 발표하고 있습니다. 매주 NVIDIA 소프트웨어 라이브러리에 대한 개선 사항이 게시되어 고객이 동일한 GPU에서 더 많은 것을 얻을 수 있습니다. 예를 들어, 불과 몇 달 만에 지연 시간이 짧은 Llama 70B 성능을 3.5배 향상시켰습니다.
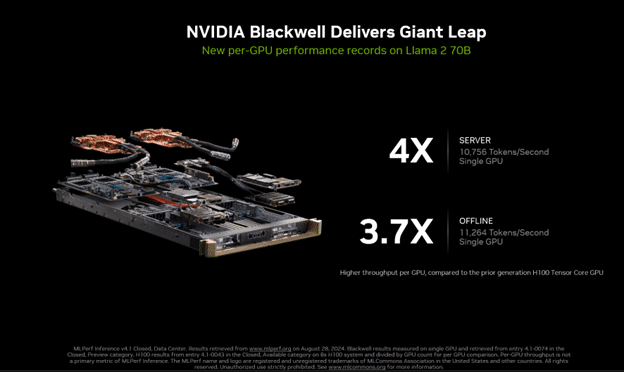
가장 최근의 MLPerf Inference 4.1에서는 처음으로 Blackwell 플랫폼으로 출품했습니다. 이 플랫폼은 이전 세대보다 4배 더 뛰어난 성능을 제공했습니다.
이 출품작은 또한 FP4 정밀도를 사용한 최초의 MLPerf 출품작이었습니다. FP4와 같이 정밀도가 낮은 포맷은 메모리 사용 공간과 메모리 트래픽을 줄이고 계산 처리량도 향상시킵니다. 이 프로세스는 Blackwell의 2세대 Transformer 엔진과 TensorRT Model Optmizer의 일부인 최첨단 양자화 기술을 활용한 Blackwell의 벤치마크 성능은 MLPerf 벤치마크의 엄격한 정확도 목표를 충족했습니다.
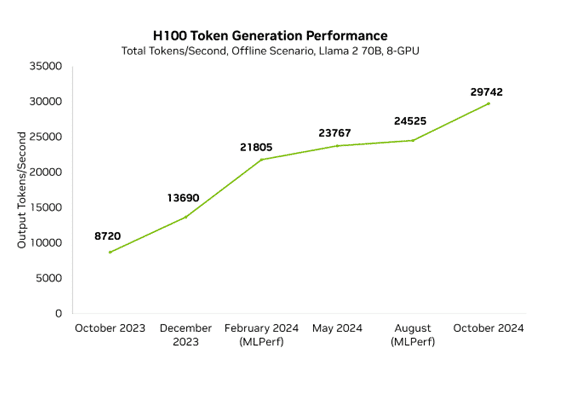
Blackwell의 향상이 Hopper의 지속적인 가속화를 막지는 못했습니다. 지난 1년 동안 정기적인 소프트웨어 개선 덕분에 H100의 MLPerf에서 Hopper 성능은 3.4배 향상되었습니다. 즉, 현재 Blackwell에서 NVIDIA의 최고 성능은 1년 전 Hopper에서보다 10배 더 빠릅니다.
현재 진행 중인 작업은 NVIDIA GPU에서 추론을 효율적으로 수행하기 위한 최첨단 최적화가 포함된 LLM을 가속화하기 위해 특별히 제작된 라이브러리인 TensorRT-LLM에 통합되어 있습니다. TensorRT-LLM은 TensorRT 딥 러닝 추론 라이브러리를 기반으로 구축되었으며, LLM에 특화된 추가적인 개선 사항과 함께 TensorRT의 딥 러닝 최적화를 대부분 활용합니다.
비약적으로 향상된 Llama 의 성능
최근에는 버전 3.1과 3.2는 물론 모델 크기 70B와 가장 큰 모델인 405B를 포함하여 Meta의 다양한 Llama 모델을 지속적으로 최적화하고 있습니다. 이러한 최적화에는 맞춤형 양자화 레시피와 병렬화 기술을 효율적으로 사용하여 여러 GPU에 걸쳐 모델을 보다 효율적으로 분할하고, NVIDIA NVLink 및 NVSwitch 인터커넥트 기술을 활용하는 것이 포함됩니다. Llama 3.1 405B와 같은 최첨단 LLM은 매우 까다롭기 때문에 빠른 응답을 위해 여러 최신 GPU의 성능을 결합해야 합니다.
병렬 처리 기술은 성능을 극대화하고 통신 병목 현상을 방지하기 위해 강력한 GPU 간 인터커넥트 패브릭을 갖춘 하드웨어 플랫폼이 필요합니다. 각 NVIDIA H200 Tensor 코어 GPU에는 4세대 NVLink가 탑재되어 있어 무려 900GB/s의 GPU-to-GPU 대역폭을 제공합니다. 또한 모든 8-GPU HGX H200 플랫폼에는 4개의 NVLink 스위치가 함께 제공되므로 모든 H200 GPU가 다른 H200 GPU와 동시에 900GB/s의 속도로 통신할 수 있습니다.
많은 LLM 배포는 단일 GPU에 워크로드를 유지하는 대신 병렬 처리를 사용하며, 이로 인해 컴퓨팅 병목 현상이 발생할 수 있습니다. LLM은 애플리케이션 니즈에 따라 최적의 병렬화 기술을 사용하여 짧은 지연 시간과 높은 처리량 간의 균형을 추구합니다.
예를 들어, 지연 시간을 최소화하는 것이 최우선이라면 Tensor 병렬 처리가 중요하며, 여러 GPU의 컴퓨팅 성능을 결합하여 사용자에게 토큰을 더 빠르게 제공할 수 있기 때문입니다. 그러나 모든 사용자의 최대 처리량이 우선시되는 사용 사례의 경우, 파이프라인 병렬 처리를 통해 전체 서버 처리량을 효율적으로 높일 수 있습니다.
아래 표는 Tensor 병렬 처리가 최소 지연 시간 시나리오에서 5배 이상의 처리량을 제공할 수 있는 반면, 파이프라인 병렬 처리는 최대 처리량 사용 사례에서 50% 더 많은 성능을 제공한다는 것을 보여줍니다.
주어진 지연 시간 예산 내에서 처리량을 극대화하려는 프로덕션 배포의 경우, 플랫폼은 TensorRT-LLM에서처럼 두 기술을 효과적으로 결합할 수 있는 기능을 제공해야 합니다.
이러한 기술에 대해 자세히 알아보려면 Llama 3.1 405B 처리량 향상 에 대한 기술 블로그를 읽어보세요.

선순환 구조
아키텍처의 수명 주기 동안 지속적인 소프트웨어 튜닝과 최적화를 통해 상당한 성능 향상을 제공합니다. 이러한 개선은 플랫폼에서 교육 및 배포하는 고객에게 추가적인 가치로 이어집니다. 고객은 더 뛰어난 성능의 모델과 애플리케이션을 만들고 더 적은 인프라를 사용하여 기존 모델을 배포할 수 있으므로 ROI가 향상됩니다.
새로운 LLM과 여러 생성형 AI 모델이 계속 출시됨에 따라, NVIDIA는 계속해서 플랫폼에서 이를 최적으로 실행하고 NIM 마이크로서비스 및 NIM Agent Blueprints와 같은 기술을 통해 보다 쉽게 배포할 수 있도록 지원할 것입니다.
이 리소스를 통해 자세히 알아보세요:
- NVIDIA 플랫폼 전반에서 Llama 3.1 강화하기
- NVIDIA NVLink and NVIDIA NVSwitch and Large Language Model Inference
- Boosting Llama 3.1 405B up to 1.44x With NVIDIA TensorRT Model Optimizer
- NVLink Switch가 탑재된 NVIDIA HGX H200의 Medusa로 최대 1.9배 향상된 Llama 3.1 성능
- Blackwell Is Coming. NVIDIA GH200 NVL32 Gives Signs of Big Leap in Time to First Token Performance
- Boosting Llama 3.1 405B Throughput by 1.5x on H200 Tensor Core GPUs