
서론
데이터 사이언티스트의 입장에서 효율적인 파이프라인의 설계는 대단히 중요합니다. 복잡한 엔드-투-엔드 워크플로우를 구성할 때면 다양한 빌딩 블록 중에서 특정 작업에 특화된 요소를 선택하게 되는데요. 이때 데이터 형식을 반복적으로 변환하면 오류가 발생하기 쉽고 성능도 저하됩니다. 이 문제를 한번 해결해봅시다!

효율적인 프레임워크 상호운용성의 여러 측면을 살펴볼 이번 시리즈는 다음의 내용으로 구성됩니다.
- 1부에서는 개별 메모리 레이아웃의 장단점과 비동기 메모리 할당으로 제로-카피(zero-copy) 기능을 구현하는 메모리 풀을 소개합니다.
- 2부에서는 데이터 로딩/전송 중에 발생하는 병목 현상과 이를 RDMA(원격 직접 기억 장치 접근) 테크놀로지로 완화하는 방법을 조명합니다.
- 3부에서는 앞서 논의한 기법들을 입증할 엔드-투-엔드 파이프라인을 구축해 데이터 사이언스 프레임워크 전반에서 최적의 데이터 전송을 달성하는 방법을 집중적으로 다룹니다.
프레임워크 상호운용성에 대한 추가 정보는 GTC 2021컨퍼런스의 NVIDIA 발표 세션에서 확인하세요.
제로-카피 기능은 GPU 가속 데이터 사이언스 프레임워크인 텐서플로우(TensorFlow)와 파이토치(PyTorch), MXNet, cuDF, CuPy, 넘바(Numba), JAX 전반에서 데이터를 효율적으로 복사하는 핵심 기법입니다(Figure 2 참조). 지금부터 이를 체계적으로 달성하는 방법을 살펴보겠습니다. 프레임워크 사이에서 데이터를 전송하는 명령어만을 원하는 경우 이 변환표를 참고하세요.
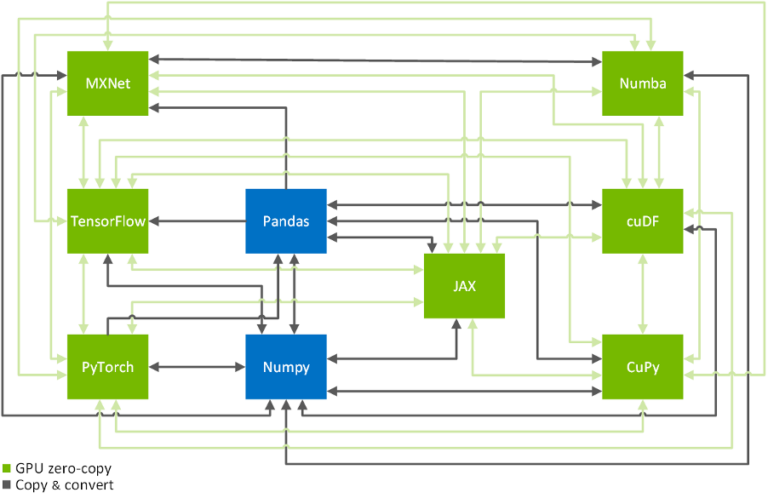
메모리 레이아웃과 데이터 형식, 그리고 메모리 풀
메모리 레이아웃
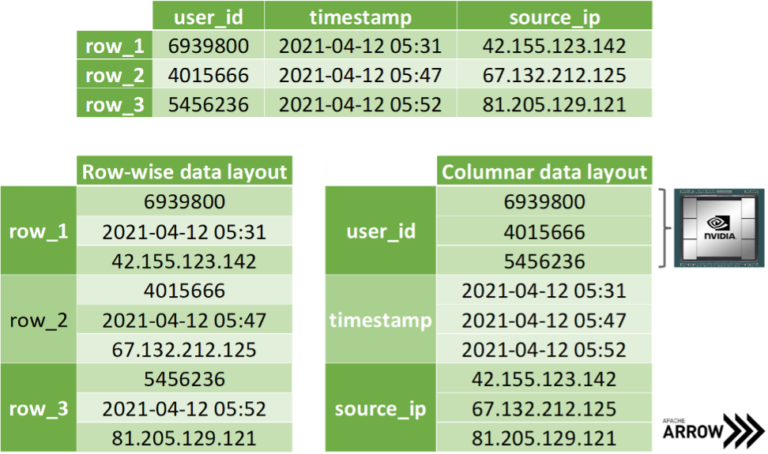
데이터를 효율적으로 복사하는 방법을 논하기에 앞서 표 형식 데이터의 저장 방식부터 살펴보겠습니다. 실질적으로 모든 데이터 형식은 컴퓨터 과학자들에게 널리 알려진 두 개의 메모리 레이아웃 중 하나에서 비롯됩니다(Figure 3 참조).
- 구조체의 배열(Array of Structures, AoS): 하나 이상의 데이터 포인트 x, y, z, …로 구성된 시퀀스의 잠정적 고유 유형이 structure S로 표시됩니다. 이 데이터 포인트의 인스턴스가 각각 새 데이터 유형 S의 s 배열로 할당됩니다. 따라서 k번째 인스턴스의 포인트 x, y, z, …의 원래 목록은 구조 인스턴스 s[k]의 멤버(member)인 s[k].x, s[k].y, s[k].z, …로 액세스됩니다.
- 배열의 구조체(Structure of Arrays, SoA): 데이터 포인트 x, y, z, …의 인스턴스 각각이 격리된 배열인 s_x, s_y, s_z, … 에 저장됩니다. 따라서 k번째 인스턴스의 원래 포인트인 x, y, z, …는 s_x[k], s_y[k], s_z[k], …로 액세스됩니다. 결국 이러한 배열들은 (순전히 가상으로 존재하는) 구조체의 단일 인스턴스로 해석될 수 있다는 점에서 SoA라고 불립니다.

프로그래밍과 추상화의 관점에서는 AoS 레이아웃이 SoA보다 구조화된 듯 보이는 반면, 달성 가능한 성능의 관점에서는 방대한 병렬 알고리즘에 대한 적합성이 떨어지는 경향이 있습니다. 이러한 현상은 이를테면 한 좌표축을 따라 값이 감소하는 동안 구조체 멤버의 서브셋(subset)에 지속적으로 액세스하면서 캐시 라인(cache line)의 효율성이 감소하기 때문으로 설명할 수 있습니다. AoS 메모리 레이아웃에서 단순 처리하는 대신 AoS와 SoA를 즉각적으로 변환할 때 성능이 크게 개선됨을 보여주는 연구 사례들도 존재합니다.
SoA 메모리 레이아웃은 데이터에서 잘라낸 좌표의 복사 시에도 추가적인 이점을 제공합니다. 모든 x좌표를 한 번에 전송하려는 상황이라면 AoS 레이아웃처럼 멤버를 잘라내느라 시간을 소요하는 일 없이 해당 배열에 바로 액세스할 수 있습니다. 또한 데이터 전송 시 바이트를 전혀 복사하지 않고 메모리 내 배열 주소만 노출하는 방식으로 예비 메모리의 할당을 피할 수 있어 유리합니다. 아파치 애로우(Apache Arrow)는 이 방법론을 기반으로 구축됩니다. 앞서 논의한 이유에 따라 개별 데이터 유형의 데이터를 서로 다른 배열에 저장하죠(Figure 4 참조). Figure 3에서 살펴본 바와 같이 주류 데이터 사이언스 프레임워크는 SoA 레이아웃의 배열 항목이 행(row) 대신 열(column)로 저장된 것처럼 취급합니다. 하지만 이는 관례에 불과합니다. 우리는 사실상 모든 메모리가 선형 구성이라는 점을 잘 알고 있기 때문이죠.
데이터 형식과 제로-카피 메커니즘
최근 몇 년간 다양한 요구에 부응하기 위한 각종 라이브러리들이 개발됐습니다. 이와 동시에 데이터 사이언스 파이프라인도 점차 복잡해지면서 다중의 라이브러리를 사용해 다양한 작업을 완수해야 하는 문제가 발생했습니다. 안타깝게도 이러한 라이브러리를 설계할 때 프레임워크 간 상호운용성은 최우선 과제로 고려되지 않았습니다. 결과적으로 데이터 사이언스 관련 업무에 적합한 표준 데이터 형식들이 부족하게 됐죠. 당시에는 데이터 표준에 우려를 표하는 이들도 있었습니다. 대표적인 인물이 웨스 매키니(Wes McKinney)인데요. 판다스 프로젝트(pandas project)의 창시자인 그는 2011년에 파이썬의 풍부한 과학적 데이터 구조를 위한 미래의 로드맵을 제시하는 글을 발표하기도 했습니다.
모든 라이브러리가 맞춤형 인메모리 데이터 레이아웃과 파일 형식을 도입했으므로 라이브러리 간 협업이 필요할 때면 큰 비용을 들여 복사와 변환 작업을 수행해야 했습니다. 전체 실행 시간의 상당 부분이 무의미한 복사와 변환에 투입되는 경우가 다반사였죠.
2016년 10월에 아파치 재단(Apache Foundation)이 애로우를 출시했습니다. 아파치 애로우는 CPU와 GPU 모두에서 수평적 데이터와 계층적 데이터를 효율적으로 처리하기 위한 언어 독립적 열 단위 데이터 형식 규격입니다. 그때부터 다양한 프레임워크가 애로우를 채택하면서 제로-카피 방식의 데이터 교환이 용이해졌습니다. 아파치 애로우 열 단위 데이터 형식의 핵심 기능은 다음과 같습니다.
- O(1) (상수-시간) 랜덤 액세스
- SIMD(단일 명령 다중 데이터 처리)와 벡터화에 적합
- 순차 접근(스캔)을 위한 데이터 인접성(adjacency)
- ‘포인터 스위즐링(pointer swizzling)’ 없이 재배치가 가능해 공유 메모리에서 진정한 의미의 제로-카피 액세스 가능
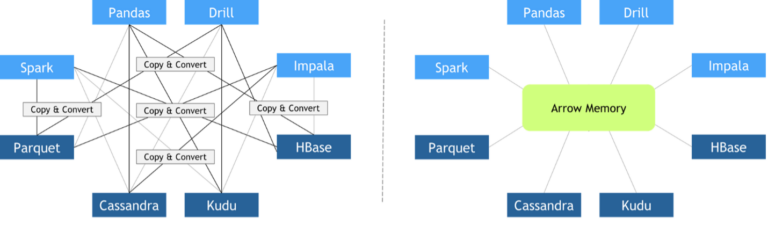
제로-카피 메커니즘은 불필요한 데이터 전송을 방지하여 애플리케이션의 실행 시간을 대폭 단축합니다. 데이터 사이언스 프레임워크는 디엘팩(DLPack)과 CUDA 어레이 인터페이스(Array Interface), 넘파이 어레이 인터페이스(NumPy Array Interface) 중 하나 이상의 데이터 형식에 대한 지원을 추가해 왔습니다.
디엘팩은 프레임워크 간 텐서를 공유하기 위한 개방형 인메모리 텐서 구조입니다. CUDA 어레이 인터페이스와 넘파이 어레이 인터페이스는 GPU나 CPU 배열과 유사한 오브젝트를 교환하는 사실상 표준에 해당합니다.
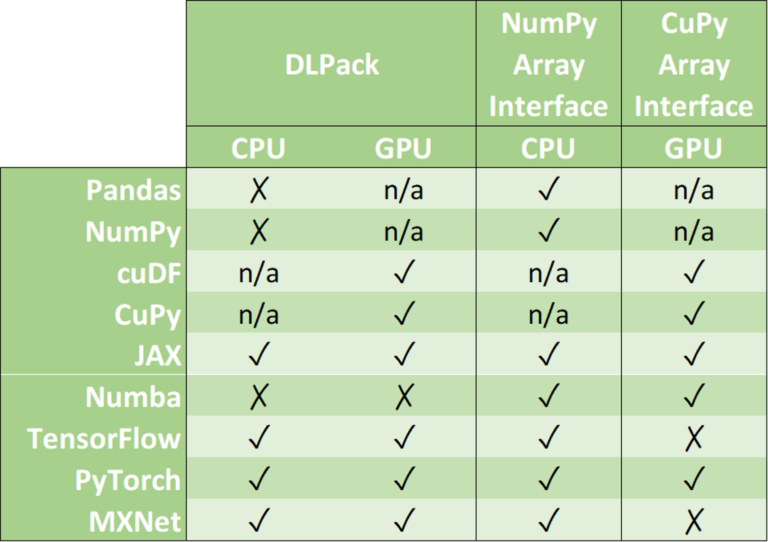
cuDF와 CuPy 같은 일부 라이브러리는 GPU 기반 장치에서만 실행된다는 사실에 주의하세요. 넘파이 어레이를 cuDF나 CuPy 오브젝트로 변환할 수는 있지만 이때 호스트 메모리(CPU)와 장치 메모리(GPU) 간 데이터 이동을 요하기 때문에 지원 내용에 n/a(해당 사항 없음)로 표시했습니다.
이제부터는 다양한 프레임워크 내 데이터 오브젝트의 메모리 레이아웃, 제로-카피를 활용한 데이터 오브젝트의 효율적 변환, 프레임워크 혼합 시 공동 메모리 풀의 사용법을 살펴보겠습니다.
메모리 풀
메모리 할당은 값비싼 작업입니다. 이를 위해 종종 전면적인 배리어(barrier)를 사용할 때도 있죠. 배리어는 메모리 할당이 완료될 때까지 나머지 운영을 막는 역할을 합니다. 따라서 신경망 훈련처럼 빡빡한 for 루프(for loop)로 메모리를 반복 할당하는 작업은 성능적 관점에서 막대한 대가를 요하는 셈입니다. 이 문제의 해결을 위해 현대의 데이터 사이언스와 딥 러닝 프레임워크는 전용 메모리 풀을 사용합니다. 프로그램 시작 시에 상당량의 메모리를 사전 할당해 두거나(예: 텐서플로우), 몇 차례의 드문 할당을 통해 메모리 풀을 점진적으로 늘립니다(예: 파이토치). 사전 할당된 메모리의 경우, 요청이 있기만 하면 이 메모리 범위의 서브셋을 비동기적으로 배정하고 회수하는 영리한 방식으로 재사용합니다. 일례로 래피즈 메모리 매니저(RAPIDS Memory Manager, RMM)는 RAPIDS 데이터 사이언스 프레임워크를 위해 만들어진 메모리 풀입니다. 호스트와 장치 메모리의 할당이 매우 신속히 진행되도록 해주죠. 마크 해리스(Mark Harris)는 2020년의 이 포스팅에서 RMM의 효과를 수치로 표현한 바 있습니다. “우리는 cuDF 메모리 관리의 중앙 집중화를 위해 ‘cudaMalloc’과 ‘cudaFree’로의 모든 호출을 RMM 할당으로 대체했습니다. 고된 작업이지만 그만큼의 보람이 있었습니다. RMM 호출은 ‘cudaMalloc’과 ‘cudaFree’보다 1,000배가량 빠릅니다. 그 결과 담보대출 분석 데모의 속도가 10배 향상됐습니다.”
별개의 데이터 사이언스 라이브러리들이 결합할 때 일부 라이브러리별 메모리 풀이 동일한 비디오 RAM을 놓고 경쟁할 수 있습니다. 손쉬운 대안은 각 메모리 풀의 용량을 사용 가능한 메모리의 고정 파티션으로 제한하는 것입니다. 그보다 나은 솔루션은 모든 프레임워크에서 동일한 메모리 풀을 사용하는 것이죠. 그렇다고 해서 모든 프레임워크가 기본 모델의 릴리스 때부터 동일한 메모리 풀 도입에 반드시 동의해야 하는 건 아닙니다. 벤더들이 자사 프레임워크 메모리의 요청과 확보를 위한 외부 할당자 인터페이스(External Allocator Interface, EAI) 사용에 동의하는 것으로 충분합니다.
void* allocate(std::size_t bytes, cudaStream_t stream) void deallocate(void* p, std::size_t bytes, cudaStream_t stream)
EAI는 간편한 로깅(logging)과 메모리 누출 검사, 속도 또는 리소스 제한 등 추가 기능을 제공합니다. 가령 래피즈 메모리 매니저는 통합 메모리를 사용해 GPU 메모리의 투명한 초과 요청을 보장하죠. 통합 메모리는 GPU 메모리에 부적합한 대규모 데이터세트로 작업할 때 아웃 오브 메모리(Out of Memory) 오류에 직면할 가능성을 크게 줄여줍니다.
여기서 좋은 점은 RAPIDS cuDF를 가장 먼저 가져오기 하는 단순한 방법으로 RMM을 CuPy나 Numba와 함께 사용할 수 있다는 사실입니다.
import cudf # <= now RMM is the global memory pool import cupy import numba
또는 RAPIDS cuDF를 사용하지 않고 Numba와 RMM을 결합할 수도 있습니다.
import rmm from numba import cuda cuda.set_memory_manager(rmm.RMMNumbaManager)
결론
NVIDIA 프레임워크 상호운용성 시리즈의 이번 포스팅에서는 각 메모리 레이아웃과 더불어 아파치 애로우 형식이 텐서플로우(TensorFlow)와 파이토치(PyTorch), MXNet, cuDF, CuPy, Numba, JAX 등의 데이터 사이언스, 머신 러닝 프레임워크 전반에서 데이터 전송 속도를 크게 높이는 방법을 살펴봤습니다. 또한 파이프라인 전체 런타임의 90%에 달하는 오버헤드(overhead)를 피하기 위해 메모리 풀이 촉진하는 비동기 메모리 할당의 중요성도 함께 논의했습니다.
이 시리즈의 두 번째 포스팅에서는 원격 직접 기억 장치 접근(RDMA)을 활용해 다중 GPU 설정에서 데이터 로딩과 전송을 가속하는 방법을 알아보겠습니다.