데이터 사이언티스트의 입장에서 효율적인 파이프라인의 설계는 대단히 중요합니다. 복잡한 엔드-투-엔드 워크플로우를 구성할 때면 다양한 빌딩 블록 중에서 특정 작업에 특화된 요소를 선택하게 되는데요. 이때 데이터 형식을 반복적으로 변환하면 오류가 발생하기 쉽고 성능도 저하됩니다. 이 문제를 한번 해결해봅시다!
효율적인 프레임워크 상호운용성의 여러 측면을 살펴볼 이번 시리즈는 다음의 내용으로 구성됩니다.
- 1부에서는 개별 메모리 레이아웃의 장단점과 비동기 메모리 할당으로 제로-카피(zero-copy) 기능을 구현하는 메모리 풀을 소개합니다.
- 2부에서는 데이터 로딩/전송 중에 발생하는 병목 현상과 이를 RDMA(원격 직접 기억 장치 접근) 기술로 완화하는 방법을 조명합니다.
- 3부에서는 앞서 논의한 기법들을 입증할 엔드-투-엔드 파이프라인을 구축해 데이터 사이언스 프레임워크 전반에서 최적의 데이터 전송을 달성하는 방법을 집중적으로 다룹니다.
프레임워크 상호운용성에 대한 추가 정보는 GTC 2021 컨퍼런스의 NVIDIA 발표 세션에서 확인할 수 있습니다.
데이터 로딩과 데이터 전송의 병목 현상
데이터 로딩 시 병목 현상
앞선 포스팅에서 우리는 데이터가 메모리에 이미 로드되어 있고 단일 GPU를 사용하는 상황이라고 가정했습니다. 이제부터는 데이터세트를 스토리지에서 장치 메모리로 로드하거나, 단일 노드 또는 다중 노드 설정에서 두 GPU 간에 데이터를 전송할 때 발생하는 병목 현상을 살펴보겠습니다. 또한 이 문제를 극복하는 방법도 함께 논의합니다.
전통적 워크플로우(Figure 1 참고)의 경우, 데이터세트를 스토리지에서 GPU 메모리로 로드할 때 해당 데이터가 CPU와 PCIe 버스(bus)를 거쳐 디스크에서 GPU 메모리로 복사됩니다. 이때 데이터 로딩에는 최소 2번의 데이터 복사 작업이 필요합니다. 먼저 스토리지에서 호스트 메모리(CPU RAM)로 데이터를 전송할 때 복사가 진행됩니다. 다음으로 호스트 메모리에서 장치 메모리(GPU VRAM)로 데이터를 전송할 때 두 번째 복사가 진행됩니다.
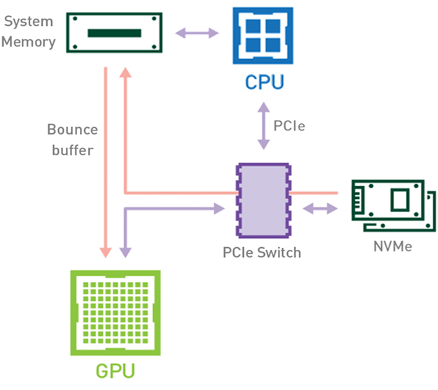
그 대신 NVIDIA Magnum IO GPUDirect Storage 기술이 도입된 GPU 기반 워크플로우(Figure 2 참고)를 사용하면 CPU와 호스트 메모리를 쓰지 않고 PCIe 버스만 이용해 데이터가 스토리지에서 GPU 메모리로 곧장 이동합니다. 이때 데이터는 1번만 복사되므로 전체 실행 시간이 줄어듭니다. 또한 이 과정에서 사용하지 않는 CPU와 호스트 메모리를 파이프라인 내 다른 CPU 기반 작업에 활용할 수 있습니다.
노드 내 데이터 전송 시 병목 현상
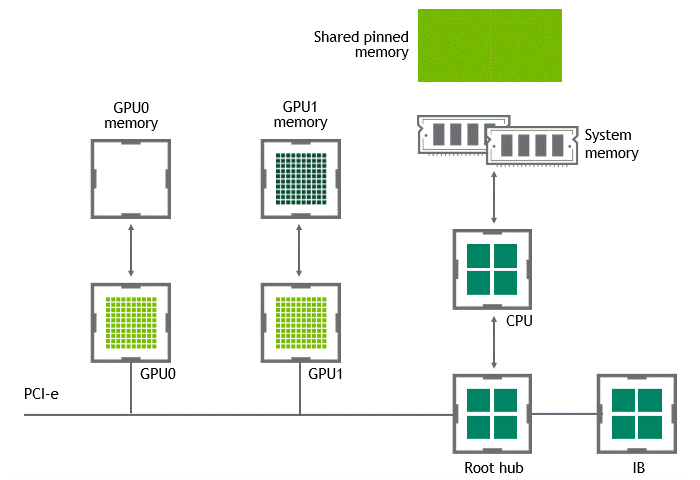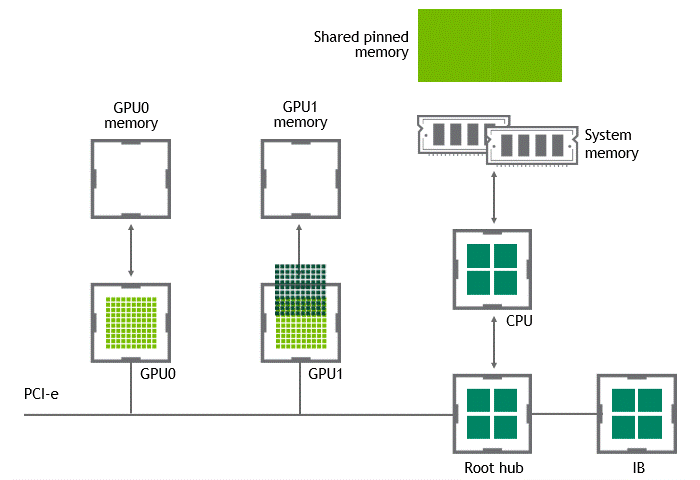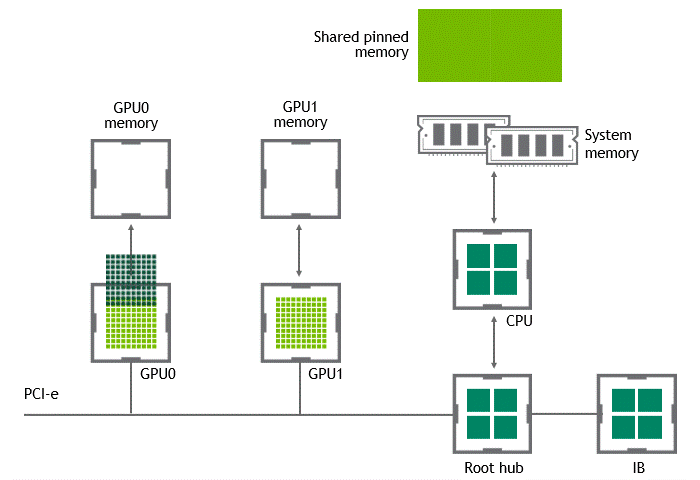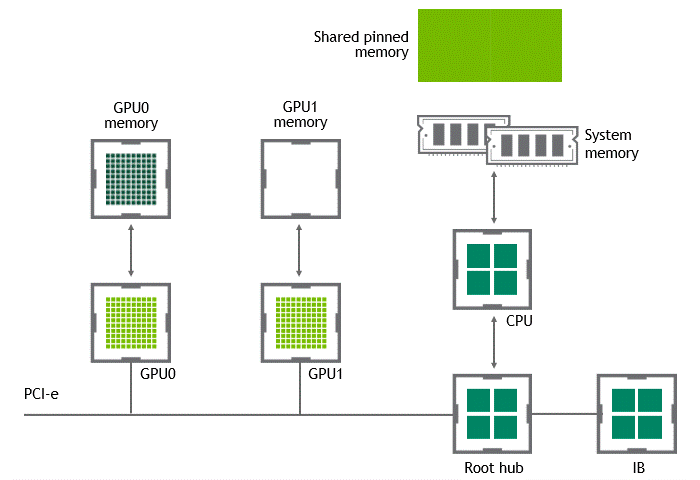
워크로드에 따라서는 동일한 노드(서버) 내에 위치한 복수의 GPU 간에 데이터를 교환하기도 합니다. NVIDIA GPUDirect Peer to Peer 기술이 활성화되지 않은 시나리오에서는 먼저 소스 GPU의 데이터가 CPU와 PCIe 버스를 거쳐 호스트 고정(host-pinned) 공유 메모리로 복사됩니다. 다음으로 호스트 고정 공유 메모리의 이 데이터가 CPU와 PCIe 버스를 거쳐 타깃 GPU로 복사됩니다. 이 프로세스는 CPU와 호스트 메모리가 모두 사용될 뿐 아니라, 데이터가 목표점에 도달하기까지 두 차례 복사가 진행된다는 점에 주목하세요. 이를 정리하면 Figure 3과 같습니다.
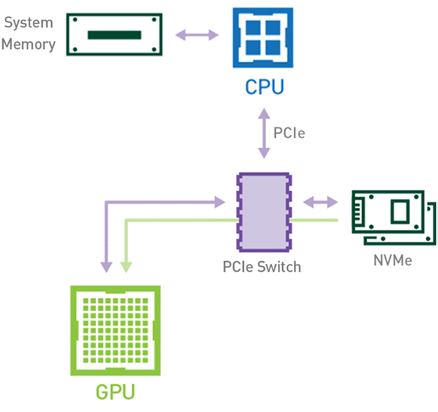
GPUDirect Peer to Peer 기술을 사용하면 소스 GPU에서 동일 노드 내의 다른 GPU로 복사하려는 데이터를 호스트 메모리에 임시 스테이징(staging)할 필요가 없습니다. 두 GPU가 동일한 PCIe 버스에 연결되어 있는 한 CPU를 거치지 않고도 해당 메모리에 액세스할 수 있죠. GPUDirect P2P는 동일한 작업의 수행에 필요한 복사 과정의 수를 절반으로 줄입니다. 이를 정리하면 Figure 4와 같습니다.
노드 간 데이터 전송 시 병목 현상
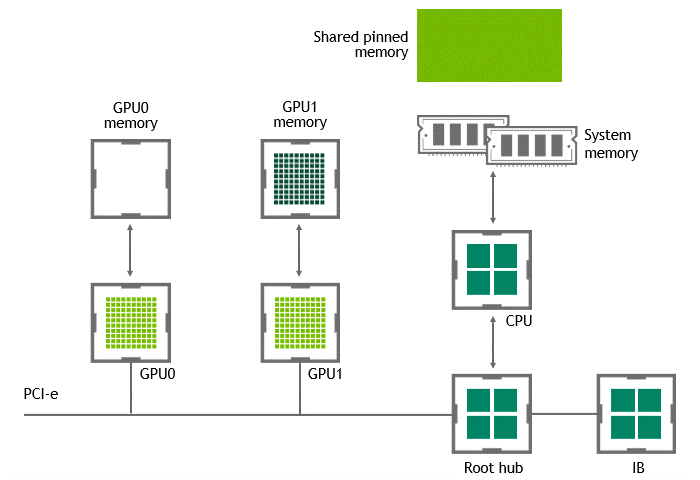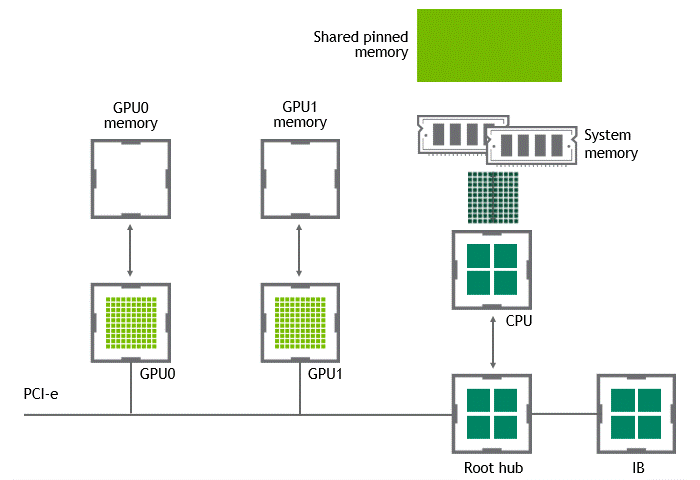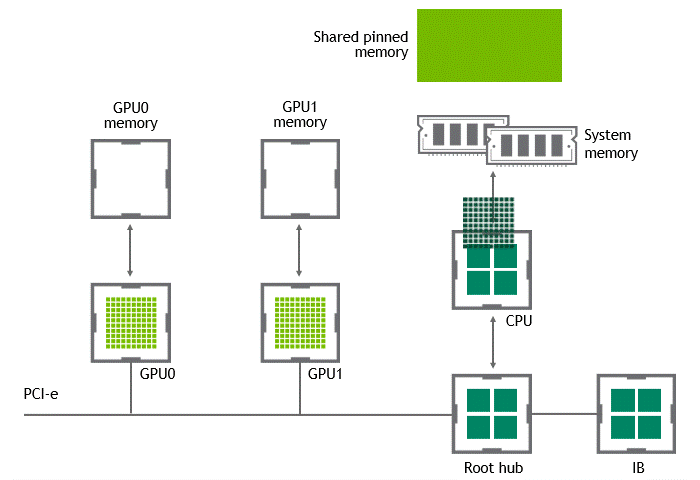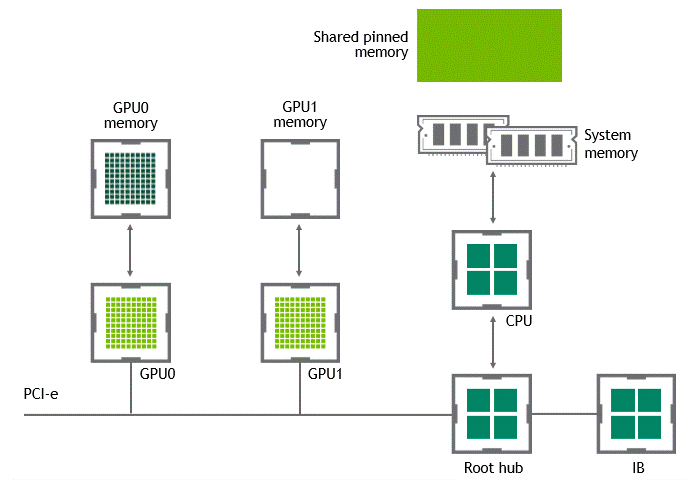
NVIDIA GPUDirect RDMA(Remote Direct Memory Access) 기술이 활성화되지 않은 다중 노드 환경에서는 서로 다른 노드에 있는 두 GPU 간 데이터 전송에 5번의 복사 작업이 필요합니다. 세부 내용은 다음과 같습니다.
- 1번째 복사: 데이터를 소스 GPU에서 소스 노드 내 호스트 고정 메모리 버퍼(buffer)로 전송할 때
- 2번째 복사: 해당 데이터가 소스 노드 NIC의 드라이버 버퍼에 복사될 때
- 3번째 복사: 데이터가 네트워크를 통과해 타깃 노드 NIC의 드라이버 버퍼로 전송될 때
- 4번째 복사: 데이터가 타깃 노드의 NIC 드라이버 버퍼에서 타깃 노드 내 호스트 고정 메모리 버퍼로 복사될 때
- 5번째 복사: PCIe 버스를 사용해 데이터를 타깃 GPU로 복사할 때
이렇게 총 다섯 차례의 복사 작업이 수행됩니다. 참으로 고된 여정이라고 할 수 있는데요. 이를 정리하면 Figure 5와 같습니다.
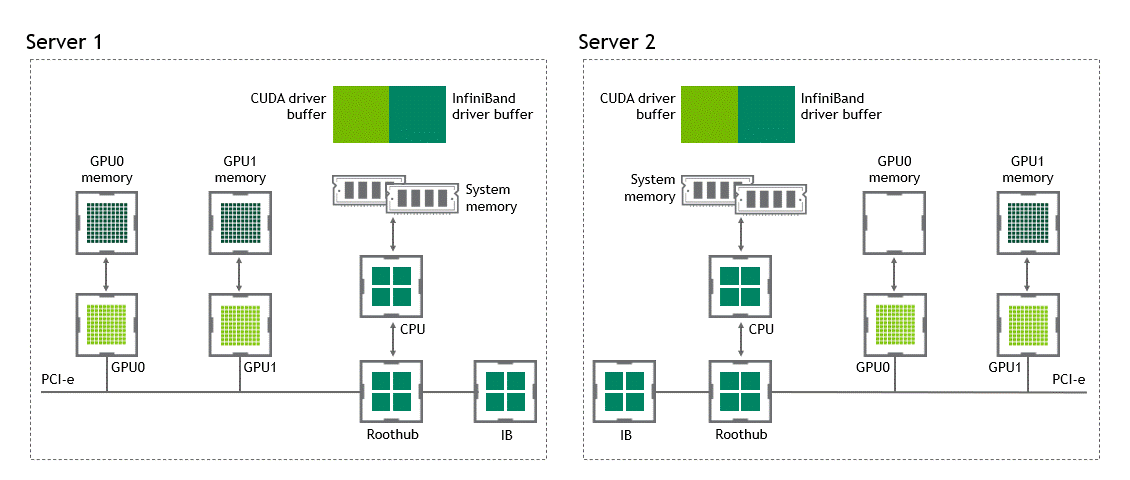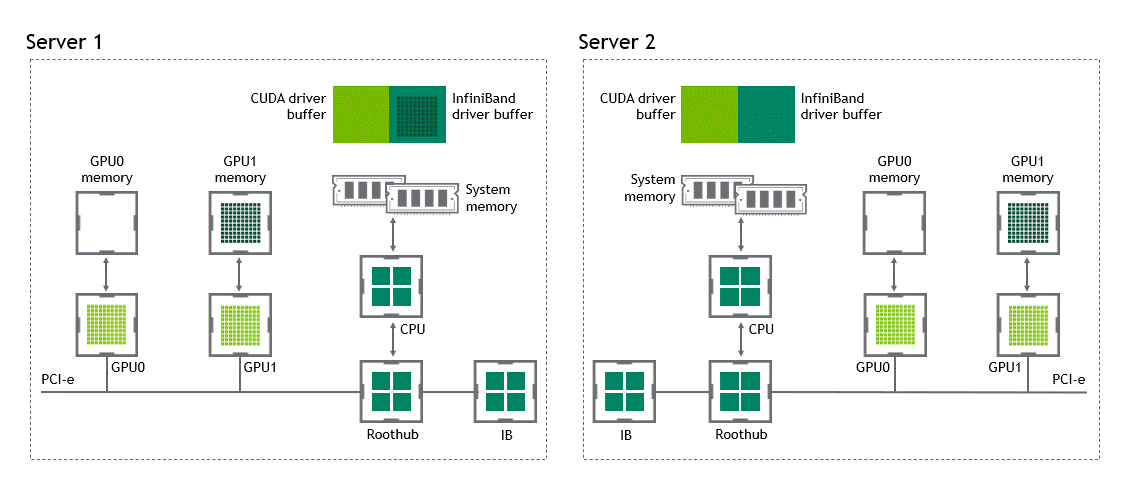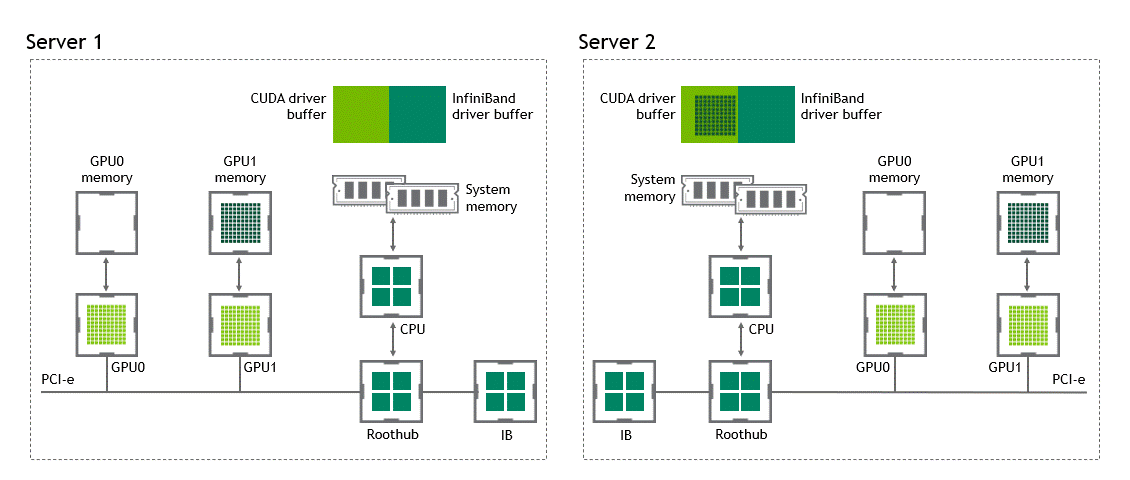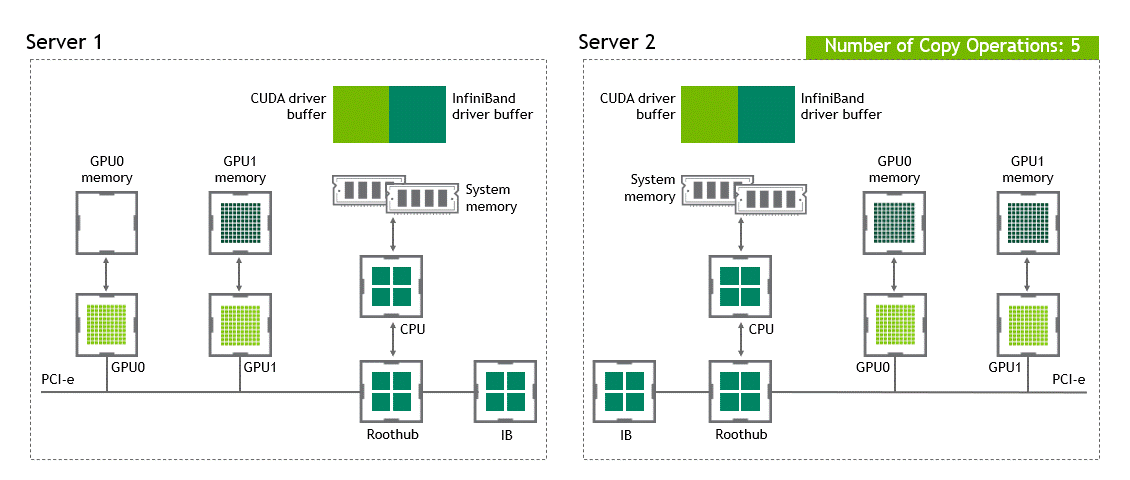
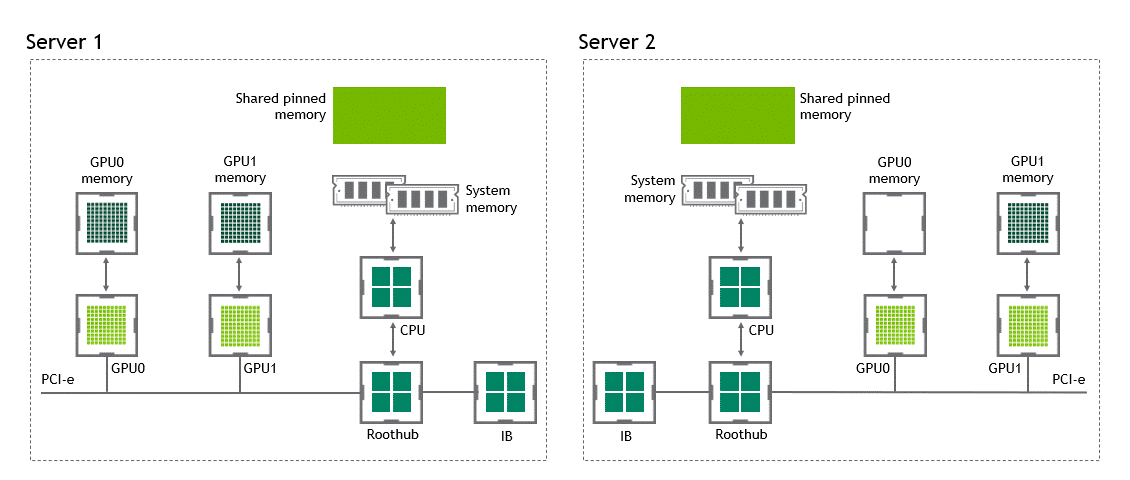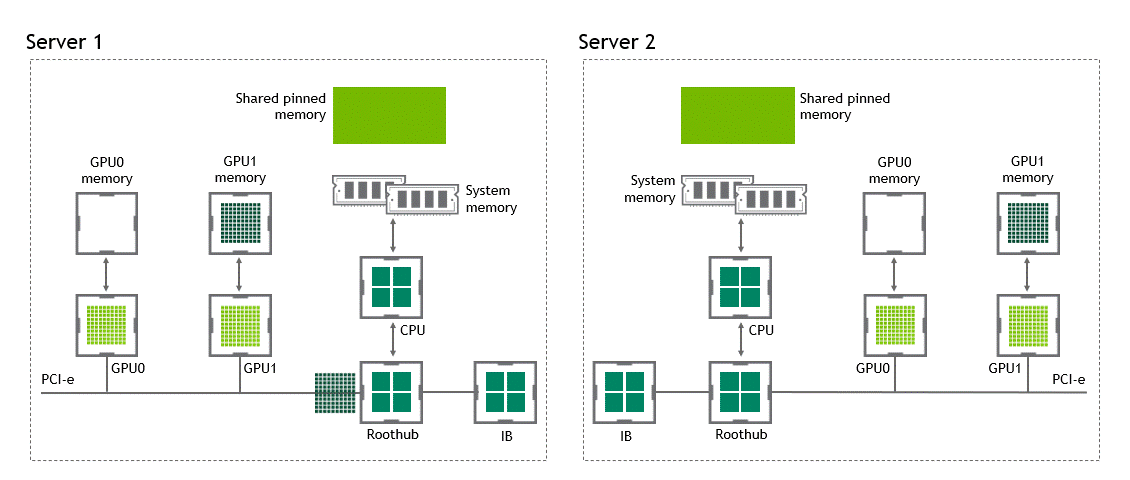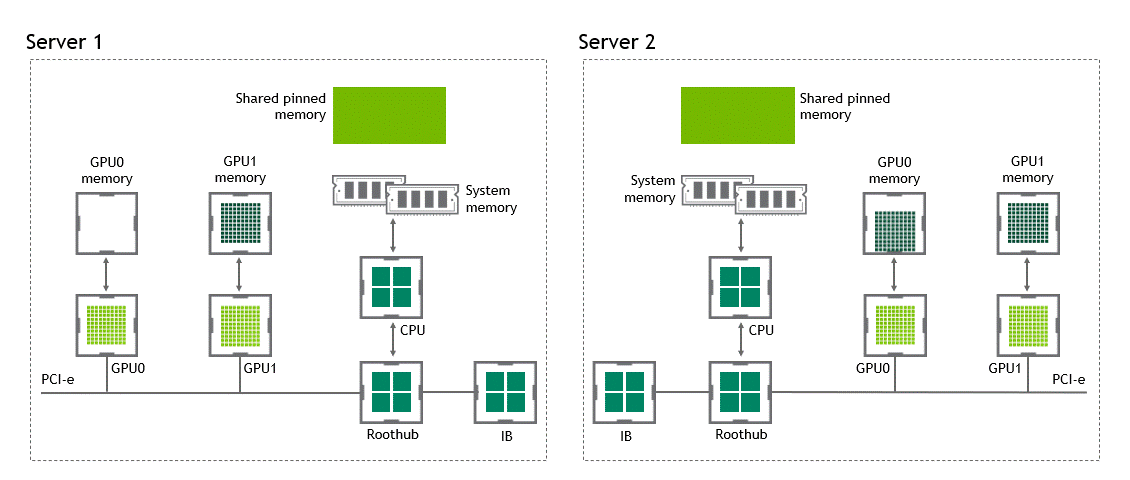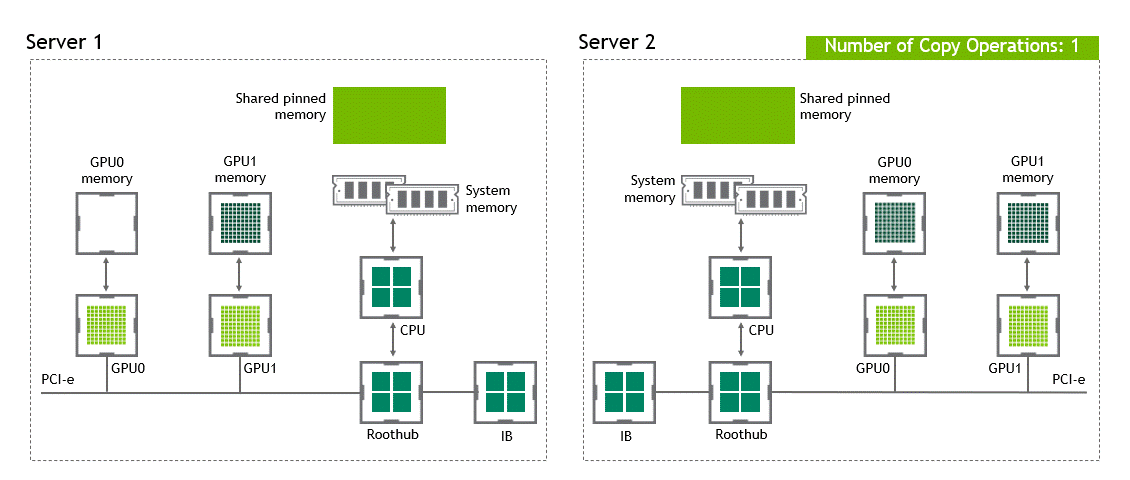
GPUDirect RDMA가 활성화되면 데이터 복사 작업을 1회로 줄여줍니다. 호스트 고정 공유 메모리에서 데이터를 복사하는 중간 과정이 더는 필요 없죠. 단 1번의 실행으로 소스 GPU의 데이터가 타깃 GPU에 복사되므로 전통적 워크플로우에 포함된 4번의 불필요한 복사 과정을 생략할 수 있습니다. 이를 정리하면 Figure 6과 같습니다.
결론
이번 포스팅에서는 NVIDIA GPUDirect 기능을 활용해 파이프라인의 데이터 로딩과 배포 단계를 가속하는 방법을 살펴봤습니다.
다음 포스팅에서는 연속 측정 심전도(ECG) 스트림에서 이상 심장 박동을 감지하는 의료 데이터 사이언스 파이프라인의 구현 요건을 집중적으로 알아보겠습니다.