
NVIDIA는 MLPerf 벤치마크에서 NVIDIA AI 기반 시스템을 통해 훈련 성능을 입증했습니다!
NVIDIA AI를 사용해 클라우드 서비스 및 OEM 선도기업인 델 테크놀로지스(Dell Technologies), 인스퍼(Inspur), 슈퍼마이크로(Supermicro), 마이크로소프트 애저(Microsoft Azure)는 MLPerf 벤치마크 AI 트레이닝 부문에서 신기록을 세웠습니다. 해당 시스템들은 새롭게 발표된 MLPerf 트레이닝(training) 1.1의 주요 워크로드 8개 부문 모두에서 기록을 경신했죠.
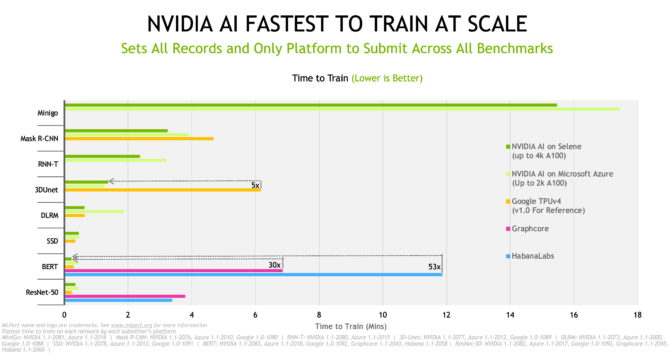
MLPerf 벤치마크에서 NVIDIA A100 Tensor Core GPU는 각 시스템에 최고 수준의 표준화된 칩당 성능(per-chip performance)을 제공했는데요. NVIDIA InfiniBand 네트워킹과 소프트웨어 스택은 NVIDIA DGX SuperPOD 기반 AI 슈퍼컴퓨터 Selene의 훈련 시간을 획기적으로 단축했습니다.
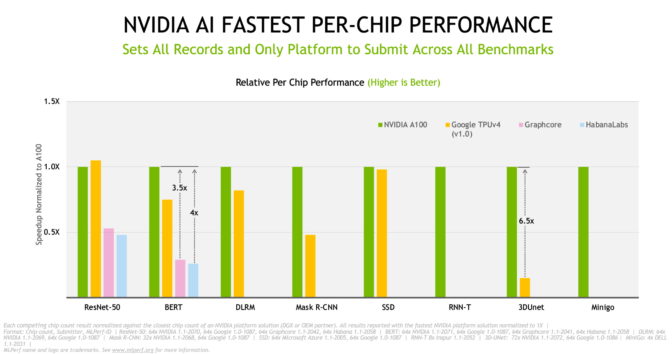
최고 수준으로 발돋움한 클라우드 성능
최근 결과에 따르면 AI 모델 훈련 부문에서 애저의 NDm A100 v4 인스턴스가 전세계에서 가장 빠른 것으로 입증됐습니다. NDm A100 v4는 해당 벤치마크의 모든 테스트를 거쳤으며 2,048개의 A100 GPU로 확장된 시스템입니다.
테스트에서 우수한 성능을 보여준 애저의 시스템은 현재 미국 전역 6개 지역에서 대여, 사용이 가능합니다.
AI 훈련은 고도의 사양을 요구하는 복잡한 작업인데요. NVIDIA는 사용자가 선호하는 서비스나 시스템을 사용해 기록적인 속도로 모델을 훈련하도록 지원합니다. 이는 NVIDIA AI가 클라우드 서비스, 코로케이션(co-location) 서비스, 기업과 과학 컴퓨팅 센터용 제품을 폭넓게 지원하는 이유이죠.
서버 제조사, NVIDIA AI로 성능 강화
OEM 중 인스퍼는 8방향 GPU 시스템 NF5688M6과 액상 냉각식 NF5488A5를 사용해 단일 노드 성능에서 가장 우수한 기록을 세웠습니다. 한편, 델과 슈퍼마이크로는 4방향 A100 GPU 시스템에서 신기록을 세웠죠.
8개의 OEM과 2개의 클라우드 서비스를 비롯해 총 10개의 NVIDIA 파트너가 테스트 결과를 제출했으며, 이는 제출된 모든 결과의 90% 이상을 차지했습니다. NVIDIA 생태계와 관련해 진행된 역대 MLPerf 트레이닝 테스트에서 5번째로 우수한 결과입니다.
NVIDIA 파트너들이 참여하는 MLPerf는 AI 훈련과 추론을 위한 유일한 업계 표준 벤치마크이며, AI 플랫폼과 공급업체를 평가하는 고객에게 중요한 지표가 됩니다.
뛰어난 속도로 입증된 서버
바이두 패들패들(Baidu PaddlePaddle), 델 테크놀로지스, 후지츠(Fujitsu), 기가바이트(GIGABYTE), 휴렛 팩커드 엔터프라이즈(Hewlett Packard Enterprise), 인스퍼, 레노버(Lenovo), 슈퍼마이크로는 단일, 다중 노드의 작업에서 실행되는 결과를 로컬 데이터 센터에 제출했습니다.
대부분의 OEM 파트너는 가속화 컴퓨팅을 추구하는 기업 고객을 위해 검증된 서버인 NVIDIA-Certified Systems에서 테스트를 실행했습니다.
광범위하게 제출된 결과를 통해 NVIDIA는 모든 규모의 기업에 최적의 솔루션을 제공하는 NVIDIA 플랫폼의 다양성과 전문성을 입증했습니다.
빠르고 유연한 성능
NVIDIA AI는 모든 벤치마크와 활용사례를 제출하는 데 사용된 유일한 플랫폼 참가자이며, 고성능과 다용도성을 증명했죠. 빠르고 유연한 시스템은 고객이 작업 속도를 높이는 데 필수적인 생산성을 지원합니다.
AI 훈련 벤치마크는 컴퓨터 비전, 자연어 처리, 추천 시스템, 강화 학습 등 오늘날 가장 인기있는 AI 워크로드와 시나리오 8가지를 다룹니다.
MLPerf 테스트의 투명하고 객관적인 결과를 활용해 사용자들은 정보에 입각한 구매결정을 내릴 수 있는데요. 2018년 5월 결성된 업계 벤치마킹 그룹은 알리바바(Alibaba), Arm, 구글(Google), 인텔(Intel)과 NVIDIA를 비롯한 수많은 업계 리더들의 지원을 받고 있습니다.
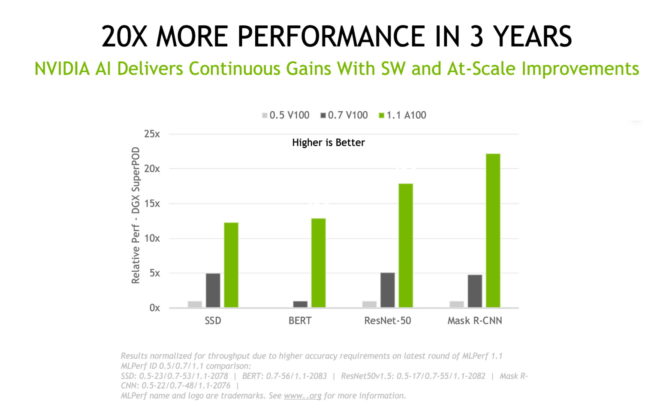
3년 동안 20배 속도 향상
이와 같은 수치는 지난 18개월 동안 A100 GPU의 성능이 5배 이상 향상됐음을 보여줍니다. 이는 오늘날 NVIDIA의 작업에서 큰 비중을 차지하는 소프트웨어의 지속적인 혁신 덕분이죠.
NVIDIA의 성능은 3년 전 처음 MLPerf 테스트가 실행된 이후 20배 이상 향상됐습니다. 이렇게 획기적인 속도 향상은 GPU, 네트워크, 시스템 및 소프트웨어의 풀 스택 제품 전반에 걸친 발전의 결과입니다.
지속적인 소프트웨어 개선
NVIDIA는 여러 소프트웨어 개선을 통해 지속적으로 발전해 왔습니다. 예를 들어, 새로운 클래스의 메모리 복사 작업을 통해 의료 영상용 3D-UNet 벤치마크에서 2.5배 빠른 속도를 달성했죠.
병렬처리를 위한 GPU 미세 조정 방법 덕분에 객체감지를 위한 Mask R-CNN 테스트 속도가 10%가량 향상됐고, 추천 시스템의 경우 27% 향상됐습니다. NVIDIA는 많은 GPU에서 실행되는 작업에 특히 효과적인 기술로서 독립적인 작업을 중첩했습니다.
NVIDIA는 호스트 CPU와의 통신을 최소화하기 위해 CUDA 그래프 사용을 확대했습니다다. 이를 통해 이미지 분류를 위한 ResNet-50 벤치마크에서 6% 향상된 성능을 제공했죠.
또한 GPU 간 통신을 최적화하는 라이브러리인 NCCL에서 두 가지 새로운 기술을 구현했습니다. 그 결과 BERT와 같은 대규모 언어 모델에서 최대 5% 가속화된 성능을 기록했습니다.
NVIDIA의 지속적인 지원
NVIDIA가 사용한 모든 소프트웨어는 누구든지 MLPerf 리포지토리에서 이용할 수 있습니다. NVIDIA는 GPU 애플리케이션을 위한 소프트웨어 허브 NGC의 컨테이너에 다양한 최적화 사항을 지속적으로 추가하고 있습니다.
이는 최신 업계 벤치마크에서 입증된 풀 스택 플랫폼의 일부이며, 오늘날 실질적인 AI 작업을 처리하는 다양한 파트너에게 제공됩니다.