
NVIDIA가 MLPerf 벤치마크에서 x86과 Arm 기반 CPU를 통해 높은 수준의 AI 추론 성능과 에너지 효율을 달성했습니다.
NVIDIA는 ML커먼스(MLCommons)가 주최하는 추론 테스트의 성능과 에너지 효율 부문에서 3회 연속 신기록을 세웠습니다. ML커먼스는 2018년 5월에 결성된 벤치마킹 그룹인데요.
이번에는 사상 최초로 Arm 기반 시스템에서 데이터센터 부문 테스트가 진행됐습니다. 이로써 오늘날 가장 혁신적인 기술인 AI를 배포하는 방법과 관련해 선택의 폭이 더욱 넓어지게 됐습니다.
압도적 우위
NVIDIA와 알리바바(Alibaba), 델 테크놀로지스(Dell Technologies), 후지쯔(Fujitsu), 기가바이트(GIGABYTE), 휴랫패커드 엔터프라이즈(Hewlett Packard Enterprise), 인스퍼(Inspur), 레노버(Lenovo), 네트릭스(Nettrix), 슈퍼마이크로(Supermicro) 등 NVIDIA 생태계 파트너사 9곳의 시스템은 7개의 추론 성능 테스트 모두에서 1위를 차지했습니다. 또한 NVIDIA는 이번 라운드의 모든 MLPerf 테스트와 현재까지 진행된 라운드 전체에서 결과를 보고한 유일한 기업이기도 합니다.
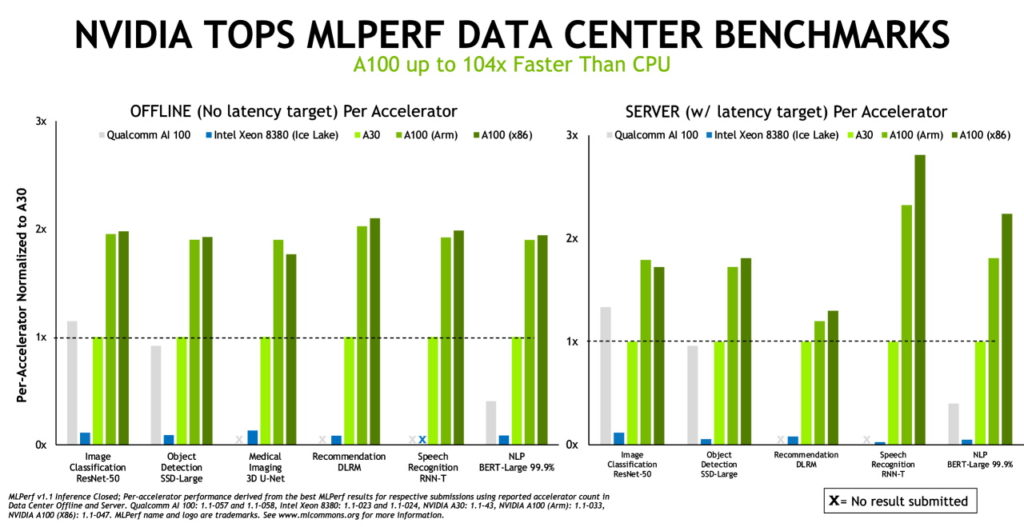
추론은 컴퓨터가 AI 소프트웨어를 실행해 오브젝트를 인식하거나 예측을 수행하는 작업을 의미한다. 이는 딥 러닝 모델로 데이터를 필터링하고, 인간이 포착할 수 없는 결과를 찾아내는 프로세스를 뜻하죠. MLPerf 추론 벤치마크는 컴퓨터 비전과 의료 이미징, 자연어 처리, 추천 시스템, 강화학습(reinforcement learning) 등 오늘날 가장 널리 사용되는 AI 워크로드와 시나리오를 기초로 구성됩니다. 따라서 사용자들은 배포하려는 AI 애플리케이션의 종류와 관계없이 NVIDIA의 기술을 활용해 자신만의 신기록을 달성할 수 있습니다.
성능에 주목해야 하는 이유
AI의 활용 사례가 데이터센터에서 엣지, 혹은 그 이상으로 확대됨에 따라 AI 모델과 데이터세트도 성장을 거듭하고 있습니다. 이런 상황에서 사용자는 신뢰성과 배포의 유연성을 보장하는 성능을 필요로 합니다. MLPerf는 알리바바와 Arm, 바이두(Baidu), 구글, 인텔, NVIDIA 등 업계의 선두주자 다수가 지원하는 만큼 테스트의 투명성과 객관성을 자랑합니다. 이를 바탕으로 충분한 정보를 제공해 유저들의 현명한 구매결정을 돕습니다.
엔터프라이즈급 AI로 영역 넓히는 Arm
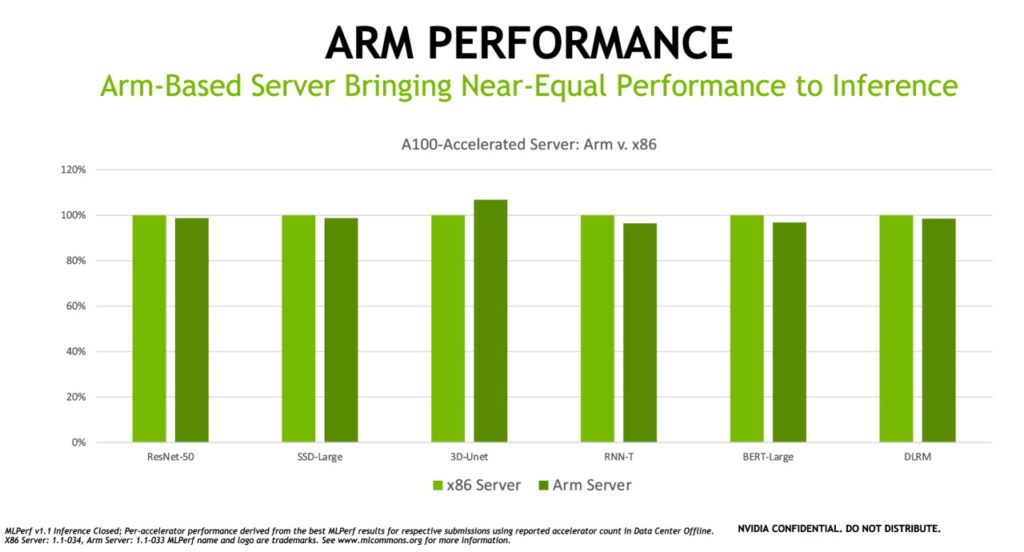
Arm 아키텍처는 에너지 효율과 성능의 향상, 소프트웨어 생태계의 확대에 힘입어 전세계 데이터센터로 진출하고 있습니다. 이번 벤치마크에 따르면 GPU 가속 플랫폼으로서 Arm 기반 서버들은 Ampere Altra CPU를 사용해 유사 구성의 x86 기반 추론용 서버와 거의 동일한 성능을 제공합니다. 실제로 일부 테스트에서는 Arm 기반 서버가 유사한 x86 시스템을 능가하기도 했죠. NVIDIA는 오랫동안 CPU 아키텍처 모두를 지원했으며, 동료 검토(peer-reviewed)가 이뤄지는 업계 벤치마크에서 Arm은 자사 AI의 우월성을 입증할 수 있게 됐습니다.
Arm의 데이비드 레콤버(David Lecomber) HPC 및 툴 부문 선임 디렉터는 “ML커먼스의 창립 멤버이기도 한 Arm은 가속 컴퓨팅 산업의 과제 해결과 혁신에 기여할 표준과 벤치마크를 수립하는 과정에 적극 동참하고 있습니다. 최근의 추론 결과는 Arm 기반 CPU와 NVIDIA GPU로 구동되는 Arm 기반 시스템이 데이터센터의 광범위한 AI 워크로드를 담당할 준비가 되었음을 보여줍니다”라고 말했습니다.
자사 AI의 저력을 보여준 파트너사들
성장을 거듭하는 대규모 생태계는 NVIDIA의 AI 기술을 뒷받침하고 있습니다. 최근의 벤치마크에는 7곳의 OEM 업체가 총 22개의 GPU 가속 플랫폼을 제출했습니다. 이 서버 모델의 대부분은 NVIDIA 인증 시스템을 통과해 다양한 범위의 가속 워크로드를 실행할 수 있는 것으로 검증됐습니다. 또한 이들 다수가 지난 달에 공식적으로 출시된 소프트웨어인 NVIDIA AI Enterprise를 지원합니다.
이번 벤치마크에 참여한 NVIDIA 파트너사로는 델 테크놀로지스, 후지쯔, 휴랫패커드 엔터프라이즈, 인스퍼, 레노버, 네트릭스, 슈퍼마이크로, 그리고 클라우드 서비스 제공업체인 알리바바 등이 있습니다.
소프트웨어의 저력
NVIDIA의 AI가 거둔 성공의 핵심에는 풀 소프트웨어 스택(full software stack)이 있습니다. 추론의 경우, 다양한 활용 사례를 위한 사전 훈련 AI 모델이 스택에 포함됩니다. NVIDIA TAO Toolkit은 전이학습을 활용해 사전 훈련 모델을 특정 애플리케이션에 맞춰 커스터마이징합니다.
NVIDIA TensorRT 소프트웨어는 AI 모델을 최적화해 메모리 활용성을 극대화하고 실행 속도를 높입니다. NVIDIA가 MLPerf 테스트에서 상시 활용하는 TensorRT는 x86과 Arm 기반 시스템 모두에서 사용 가능합니다.
NVIDIA는 또한 NVIDIA Triton Inference Server 소프트웨어와 Multi-Instance GPU(MIG) 기능도 벤치마크에 활용했습니다. 이는 전문 코더(coder)를 요하는 수준의 성능을 모든 개발자에게 제공합니다. 이 소프트웨어 스택의 지속적인 개선 덕분에 NVIDIA는 4개월 전에 진행한 MLPerf 추론 벤치마크와 비교해 성능 최대 20%, 에너지 효율 15% 향상을 달성했습니다.
최근의 테스트에서 NVIDIA가 사용한 소프트웨어 일체는 MLPerf 저장소에서 제공되고 있으며, NVIDIA의 벤치마크 결과를 누구나 재연할 수 있습니다. NVIDIA는 해당 코드를 딥 러닝 프레임워크와 NGC 컨테이너에 지속적으로 추가하고 있습니다.
해당 소프트웨어들은 풀 스택 AI를 구현하려는 노력의 일환으로 주요 프로세서 아키텍처를 모두 지원합니다. 최신 업계 벤치마크에서 입증받은 저력을 바탕으로 오늘날 진정한 AI 업무를 처리할 수 있습니다. NVIDIA 추론 플랫폼에 대한 더 자세한 정보는 NVIDIA Inference Technology Overview에서 확인할 수 있습니다.