이종환 과장, Data Scientist, NVIDIA
TensorRT는 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU 상에서의 Inference 속도를 수배 ~ 수십배 까지 향상시켜 Deep Learning 서비스 TCO (Total Cost of Ownership) 를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진입니다. 본 포스트에서는 Deep Learning 기술의 제품 및 서비스 양산화에 관심 있는 개발자 및 엔지니어들을 위해 TensorRT를 간단히 소개하여, 향후 연재될 TensorRT 적용 방안에 대한 이해도를 높이는데 도움을 드리고자 합니다. TensorRT를 project에 적용하고자 하시거나, 적용 시 어려움이나 궁금하신 부분이 있으실 경우, NVIDIA의 Deep Learning 관련 전문가인 Solutions Architect 및 Data Scientist에게 언제든 연락주시기 바랍니다.
- Introduction
TensorRT는 NVIDIA GPU 연산에 적합한 최적화 기법들을 이용하여 모델을 최적화하는 Optimizer와 다양한 GPU에서 모델연산을 수행하는 Runtime Engine을 포함합니다. TensorRT는 대부분의 Deep Learning Frameworks (TensorFlow, PyTorch 등) 에서 학습된 모델을 지원하며, NVIDIA Datacenter, Automotive, Embedded 플랫폼 등 대부분의 NVIDIA GPU 환경에서 동일한 방식으로 적용 가능하여, 최적의 Deep Learning model Inference 가속을 지원합니다.
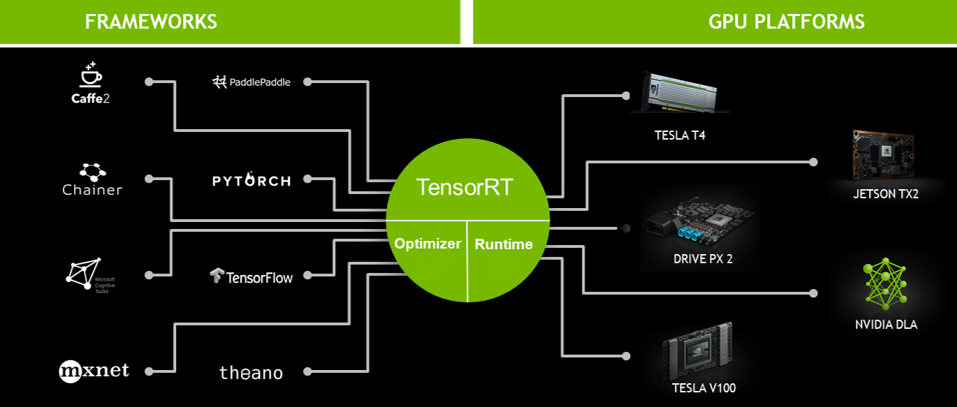
- TensorRT developments
TensorRT는 C++ 및 Python 모두를 API 레벨에서 지원하고 있기 때문에, GPU programming language인 CUDA 지식이 별도로 없더라도 Deep Learning 분야의 개발자들이 쉽게 사용할 수 있으며, Figure 2.의 절차와 같이 사용할 수 있습니다.
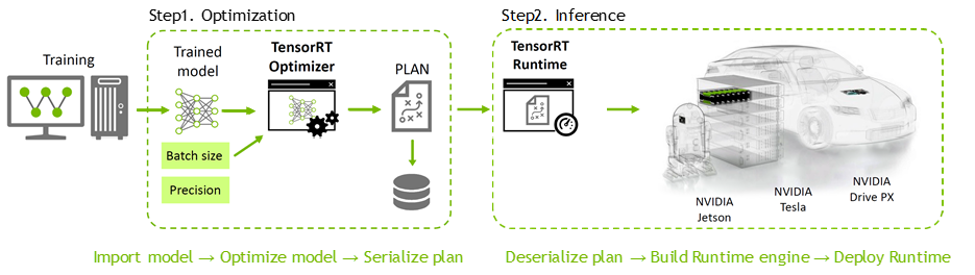
TensorRT는 GPU가 지원하는 활용 가능한 최적의 연산 자원을 자동으로 사용할 수 있도록 Runtime binary를 빌드해주기 때문에, Latency 및 Throughput을 쉽게 향상시킬 수 있고, 이를 통해 Deep Learning 응용 프로그램 및 서비스의 효율적인 실행이 가능합니다. 또한 앞서 언급한 NVIDIA의 Datacenter, Automotive, Embedded 등의 여러 플랫폼에 가장 적합한 Kernel을 선택하여 각 제품, 각 아키텍쳐에 맞는 가속을 자동으로 도와줍니다. 그리고 다양한 Deep Learning layer 및 연산에 대하여 customization할 수 있는 방법론을 제공하고 이를 통해 개발자들이 유연하게 TensorRT를 활용할 수 있다는 장점이 있습니다. 이와 관련한 자세한 개발방법은 차후 연재되는 포스트를 통하여 찾아 뵙도록 하겠습니다.
- TensorRT optimizations
TensorRT는 NVIDIA platform에서 최적의 Inference 성능을 낼 수 있도록 Network compression, Network optimization 그리고 GPU 최적화 기술들을 대상 Deep Learning 모델에 자동으로 적용합니다. 관련하여, TensorRT에서 Inference 가속을 위해 사용하는 대표적인 기법들에 대하여 알아보도록 하겠습니다.
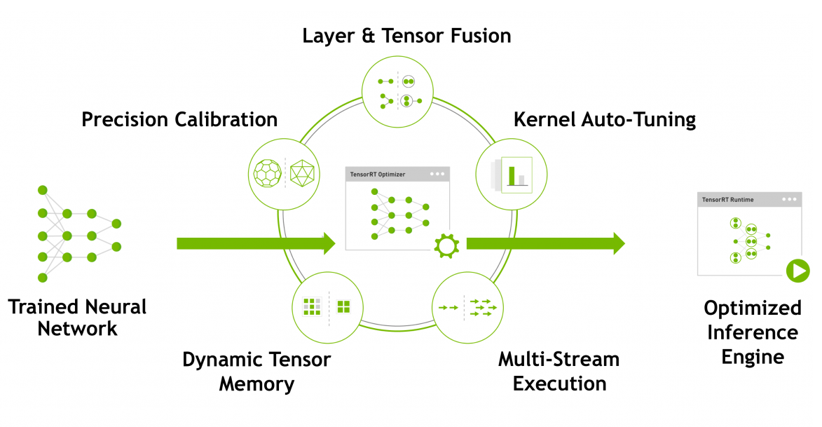
- Quantization & Precision Calibration
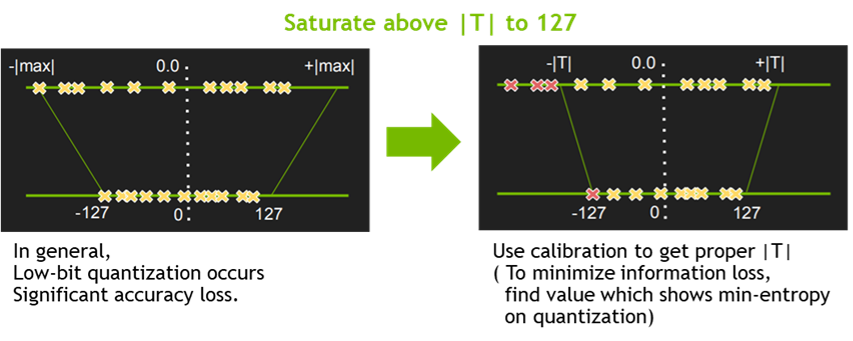
최근 Deep Learning Training 및 Inference에서의 Precision reduction 은 거의 일반적인 방법이 되었습니다. 낮은 Precision의 Network일 수록 data의 크기 및 weight들의 bit수가 작기 때문에 더 빠르고 효율적인 연산이 가능합니다. 이를 위한 Quantization 기법들 중, TensorRT는 Symmetric Linear Quantization(Figure 4.)을 사용하고 있으며, 이를 통하여 Deep Learning Framework의 일반적인 FP32의 data를 FP16 및 INT8의 data type으로 precision을 낮출 수 있습니다.
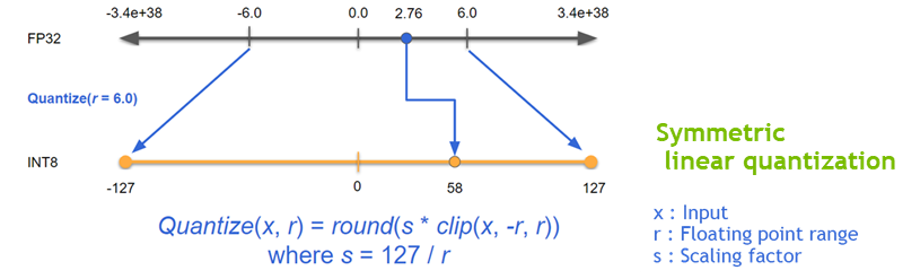
일반적으로 FP16으로의 precision down-scale은 Network의 accuracy drop에 큰 영향을 주지는 않지만, INT8로의 down-scale은 accuracy drop을 보이는 몇 부류의 Network이 존재하므로 추가적인 calibration 방법들이 필요합니다. (Figure 5. 참조) 이를 위하여 TensorRT에서는EntronpyCalibrator, EntropyCalibrator2 그리고 MinMaxCalibrator를 지원하고 있으며, 이를 이용하여 quantization시 weight 및 intermediate tensor들의 정보의 손실을 최소화 할 수 있습니다.
- Graph Optimization
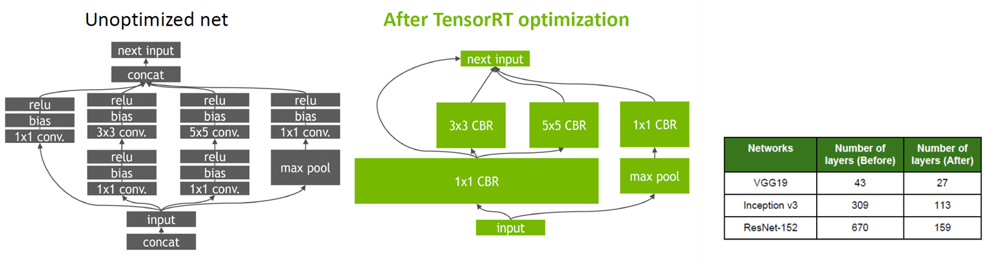
일반적으로 Graph Optimization은 Deep Learning Network에서 사용되는 primitive 연산 형태, compound 연산 형태의 graph node들을 각 platform에 최적화된 code를 구성하기 위하여 사용됩니다. TensorRT에서는 이를 기반으로 Layer Fusion 방식과 Tensor Fusion 방식을 동시에 적용하고 있습니다. Figure 6과 같이 Layer Fusion은 Vertical Layer Fusion, Horizontal Layer Fusion 그리고 Tensor Fusion이 적용되어 model graph를 단순화 시켜주고 이를 통하여 model의 layer 갯수가 크게 감소하게 됩니다.
- Kernel Auto-tuning
앞서 언급한 바와 같이 TensorRT는 NVIDIA의 다양한 platform 및 architecture에 맞는 Runtime 생성을 도와 줍니다. 각 제품들은 CUDA engine의 갯수, architecture, memory 그리고 specialized engine 포함 여부에 따라 optimize된 kernel 이 다르기 때문에 이를 TensorRT Runtime engine build시에 선택적으로 수행하여 최적의 engine binary 생성을 돕습니다.
- Dynamic Tensor Memory & Multi-stream execution
그 외에도 Memory management를 통하여 footprint를 줄여 재사용을 할 수 있도록 도와주는 Dynamic tensor memory 기능이 존재 하며, CUDA stream 기술을 이용하여 multiple input stream의 scheduling을 통해 병렬 효율을 극대화 할 수 있는 Multi-stream execution기능 또한 존재합니다.
- TensorRT performances
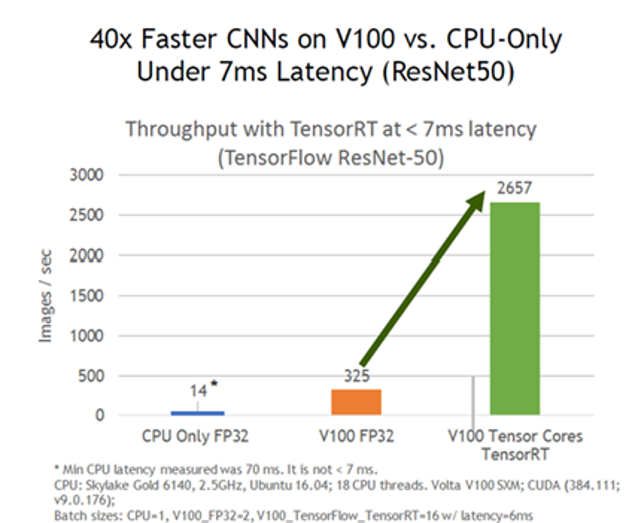
앞서 설명한 TenosrRT의 기능들을 통하여 얻을 수 있는 속도 향상을 알아보도록 하겠습니다. 기본적인 ResNet50 기준으로 볼때 동일한 GPU에서 TensorRT를 사용하는 것만으로도 대략 8배 이상의 성능 향상 효과가 있습니다. (Figure 7. 참조) 모델에 따라 성능 향상 비율의 차이가 있지만 TensorRT Inference가 Deep Learning 서비스의 효율성을 극대화 하는데 핵심적인 역할을 수행할 수 있다고 말씀 드릴 수 있습니다. 보단 자세한 속도 개선 효과는 다음의 URL (https://developer.nvidia.com/deep-learning-performance-training-Inference#deeplearningperformance_Inference) 에서 NVIDIA platform 별 Network들의 benchmark들을 자세히 확인 할 수 있습니다.
- 결론
지금까지 NVIDIA의 Deep Learning Inference 가속을 위한 solution인 TensorRT에 대하여 살펴보았습니다. TensorRT는 다양한 Deep Learning Framework를 이용하여 미리 training 된 Neural Network들을 각 domain에 맞는 NVIDIA의 GPU 플랫폼에서 효과적으로 Inference를 하기 위한 Toolkit 혹은 library입니다. 이를 이용하여 서비스 및 제품 양산을 위한 Deep Learning 모델 개발시 보다 빠른 성능과 높은 효율의 혜택을 누리시길 바랍니다. 사용법에 대한 문의 사항 및 문제 해결 요청 등의 사유로 NVIDIA와의 협업을 원하실 경우에는 언제든지 연락 주시기 바랍니다.