4개 대륙에 흩어져 있는 5명의 머신 러닝 전문가로 구성된 엔비디아 팀이 최첨단 추천 시스템을 구축하기 위해 치열한 경쟁을 벌이는 세계적인 대회에서 세 가지 부문에서 모두 우승을 차지했습니다!
이는 디지털 경제의 엔진이 되는 추천 시스템 구축 분야에서 엔비디아 AI 플랫폼을 적용한 이 참가팀의 기술력이 얼마나 노련했는가를 보여줍니다. 현재 추천 시스템은 매일 수십 억 명의 전 세계 사용자들에게 수조 개의 검색 결과, 광고, 제품, 음악 및 뉴스 기사를 제공하고 있습니다.
450곳 이상의 데이터 사이언티스트로 구성된 팀들이 Amazon KDD Cup ’23에 참가했는데요, 3개월에 걸쳐 진행된 이 대회는 우여곡절도 많았고 치열한 접전이 펼쳐졌습니다. 그 자세한 이야기를 지금부터 소개합니다!
순탄한 출발과 다가온 과제
대회의 첫 10주 동안, 엔비디아 팀은 편안한 선두를 달렸습니다. 하지만 마지막 단계에서 주최 측이 새로운 테스트 데이터 세트로 전환하면서 다른 팀들이 급격하게 앞서나가기 시작했습니다.
엔비디아 팀은 이를 따라잡기 위해 밤과 주말을 반납한 채 고도의 집중력을 발휘했습니다. 베를린에서 도쿄에 이르는 여러 도시에 거주하는 팀원들은 24시간 내내 Slack 메시지를 주고 받았습니다.
샌디에고에 있는 팀원인 Chris Deotte는 “저희는 쉬지 않고 일했습니다. 정말 흥미진진했죠.”라고 회상하고 있습니다.
다른 이름의 제품
세 가지 과제 중 마지막 과제가 가장 어려웠습니다.
참가자들은 검색 세션의 데이터를 기반으로 사용자가 어떤 제품을 구매할지 예측해야 했습니다. 하지만 훈련 데이터에는 선택 가능한 많은 브랜드 이름이 포함되어 있지 않았습니다.
“처음부터 매우 어려운 테스트가 될 것이라는 것을 알고 있었습니다.”라고 Gilberto “Giba” Titericz는 말했습니다.
구조에 나선 KGMON 팀
브라질 쿠리타바에 있는 Titericz 는 데이터 사이언스 분야의 온라인 올림픽인 Kaggle 대회에서 그랜드 마스터로 선정된 4명의 팀원 중 한 명입니다. 이들은 수십 개의 대회에서 우승한 머신 러닝 닌자 팀의 일원이기도 합니다. 엔비디아 젠슨 황 CEO는 이들을 포켓몬에 빗대어 KGMON(엔비디아의 캐글그랜드마스터)이라고 부른답니다^^
Titericz는 수십 번의 실험을 통해 대규모 언어 모델(LLM)을 사용하여 제품 이름을 예측하는 생성형 AI를 구축했지만 모두 실패했습니다.
그러던 중 Titericz의 팀은 순식간에 그 해결 방법을 발견했습니다. 새로운 하이브리드 순위/분류기 모델을 사용한 예측이 적중했습니다.
마지막 순간까지
대회 마지막 몇 시간 동안, 팀은 최종 제출을 위해 모든 모델을 패키징하기 위해 경쟁했습니다. 그들은 40대에 달하는 컴퓨터에서 밤새 실험을 진행했습니다.
도쿄에 있는 KGMON의 Kazuki Onodera는 이때 불안한 마음이 들었다고 해요. “실제 점수가 우리가 예상한 것과 일치할지 정말 알 수 없었습니다.”라고 그는 그때를 회상했습니다.

KGMON이기도 한 Deotte는 “100개의 서로 다른 모델이 하나의 결과물을 만들기 위해 함께 작업하는 것 같았습니다… 저희는 결국 리더보드에 제출했죠!”라고 당시를 기억했습니다.
이 팀은 결국 사진 마무리에 해당하는 AI 부문에서 가장 근접한 라이벌을 앞질렀습니다.
전이 학습의 힘
또 다른 과제에서 팀은 영어, 독일어, 일본어로 된 대규모 데이터 집합에서 얻은 교훈을 프랑스어, 이탈리아어, 스페인어로 된 10분의 1 크기의 빈약한 데이터 집합에 적용해야 했습니다. 이는 다른 많은 기업들인 전 세계로 디지털 입지를 확장하면서 직면하게 되는 현실적인 과제이기도 합니다.
파리 외곽에 거주하는 3번의 Kaggle 그랜드마스터인 Jean-François Fouzet는 전이 학습에 대한 효과적인 접근법을 알고 있었습니다. 그는 사전 학습된 다국어 모델을 사용하여 제품 이름을 인코딩한 다음 인코딩을 미세 조정했습니다.
“전이 학습을 사용함으로써 리더보드 점수가 엄청나게 향상되었습니다.”라고 그는 말했습니다.
기술 노하우와 스마트한 소프트웨어의 결합
KGMON의 노력은 직관과 반복을 결합하는 추천 시스템이라는 분야가 때때로 과학이라기 보다는 예술에 가깝다는 것을 보여줍니다.
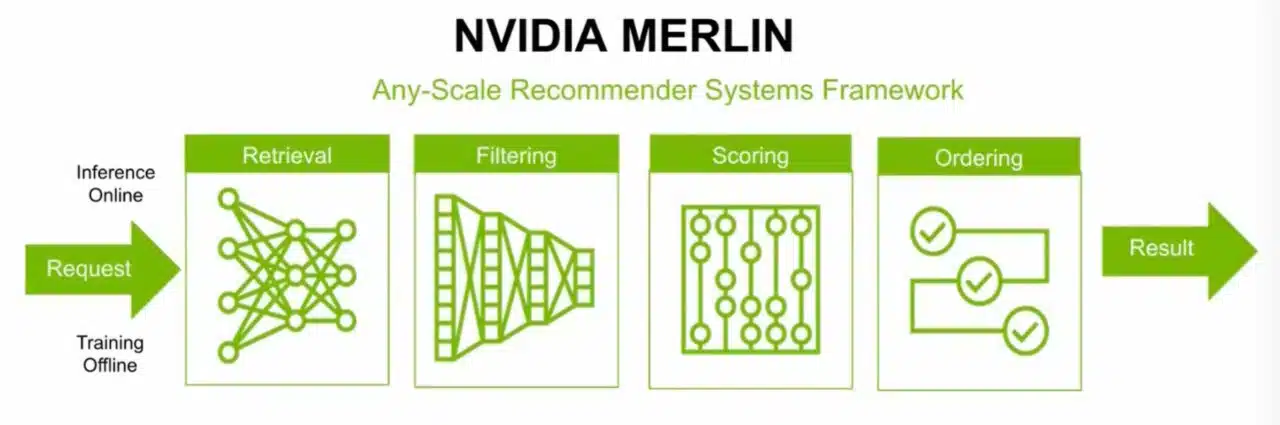
이러한 전문성은 사용자가 자신만의 추천 시스템을 빠르게 구축할 수 있도록 지원하는 프레임 워크인 엔비디아 멀린(NVIDIA Merlin)과 같은 소프트웨어 제품에 내재되어 있습니다.
베를린에 있는 팀원으로서 멀린(Merlin) 설계를 도운 Benedikt Schifferer는 이 소프트웨어를 사용하여 변압기 모델을 훈련시켰는데, 이 모델은 경쟁사의 추천 시스템 과제의 성능을 압도했습니다.
“멀린은 훌륭한 결과를 제공했을 뿐만 아니라 유연한 설계 덕분에 특정 과제에 맞게 모델을 커스터마이징할 수 있었습니다.”라고 그는 소감을 밝혔습니다.
RAPIDS 활용하기
팀원들과 마찬가지로 그 역시 GPU에서 데이터 사이언스를 가속화하기 위한 오픈 소스 라이브러리 세트인 래피즈(RAPIDS)를 사용했답니다.
예를 들어, Deotte는 가속화된 소프트웨어를 위한 엔비디아의 허브인 NGC의 코드에 액세스했습니다. DASK XGBoost라고 불리는 이 코드는 크고 복잡한 작업을 8개의 GPU와 그 메모리로 분산하는 데 도움이 되었습니다.
또한 Titericz는 cuML이라는 래피즈 라이브러리를 사용하여 수백 만 개의 제품 비교를 몇 초 만에 검색했습니다.
이 팀은 여러 사용자들의 방문 데이터가 필요하지 않은 세션 기반 추천에 집중했습니다. 이는 많은 사용자가 개인 정보를 보호하기 위해 근래 권장되고 있는 모범 사례이기도 합니다.
엔비디아의 추천 시스템에 대해 아래 링크를 통해 보다 자세히 확인해보세요:
- 멀린(Merlin)으로 세션 기반 추천 시스템을 구축하는 방법에 대한 GTC 세션을 시청하세요.
- 엔비디아 딥 러닝 인스티튜드(DLI)의 추천 시스템 강의를 수강해보세요.
- 비즈니스에 필요한 보안 및 지원 기능을 갖춘 완벽한 소프트웨어 제품군인 엔비디아 AI 엔터프라이즈(NVIDIA AI Enterprise)에서 다음 아이템 예측 워크플로우를 확인해 보세요.
- 그리고 아래 동영상을 시청하세요.