
생성형 AI는 사람들이 디지털 콘텐츠를 만들고, 상상하며, 상호작용하는 방식을 혁신적으로 바꾸고 있습니다.
하지만 지속적으로 AI 모델의 기능이 향상되고 복잡성이 증가하면서 더 많은 VRAM이 요구되고 있습니다. 예를 들어, 기본 스테이블 디퓨전 3.5 라지(Stable Diffusion 3.5 Large) 모델은 18GB 이상의 VRAM을 사용하므로 고성능 시스템이 아니면 실행이 어렵습니다.
이 모델에 양자화를 적용하면 중요하지 않은 레이어를 제거하거나 더 낮은 정밀도로도 실행할 수 있는데요. NVIDIA GeForce RTX 40 시리즈와 Ada Lovelace 세대 NVIDIA RTX PRO GPU는 FP8 양자화를 지원해 이러한 경량화된 모델을 실행할 있습니다. 또한 최신 NVIDIA Blackwell GPU는 FP4도 지원합니다.
스태빌리티 AI(Stability AI)와의 협력을 통해 최신 모델인 스테이블 디퓨전 3.5 라지를 FP8로 양자화하고 VRAM 사용량을 40%까지 줄였는데요. 여기에 NVIDIA TensorRT 소프트웨어 개발 키트(SDK)를 통한 최적화로 스테이블 디퓨전 3.5 라지와 미디엄 모델의 성능을 2배로 끌어올렸습니다.
또한, TensorRT가 RTX AI PC 환경을 위해 새롭게 설계됐습니다. 업계 최고 수준의 성능과 JIT(Just-In-Time), 온디바이스 엔진 구축 기능을 더하고 패키지 크기를 8배 줄여 1억 대 이상의 RTX AI PC에 AI를 원활하게 배포할 수 있게 됐죠. RTX용 TensorRT는 이제 개발자를 위한 독립형 SDK로 제공됩니다.
RTX 기반 AI 가속
세계에서 가장 인기 있는 AI 이미지 생성 모델 중 하나인 스테이블 디퓨전 3.5의 성능을 높이고 VRAM 요구 사항을 낮췄습니다. NVIDIA TensorRT 가속과 양자화 기술을 통해, 사용자는 NVIDIA RTX GPU에서 이미지를 더 빠르고 효율적으로 생성하고 편집할 수 있습니다.

스테이블 디퓨전 3.5 라지의 VRAM 한계를 해결하기 위해 이 모델은 TensorRT를 활용해 FP8로 양자화됐습니다. 그 결과, VRAM 요구량이 40% 줄어 11GB면 충분해졌죠. 즉, 단 한 대의 GPU가 아닌 다섯 대의 GeForce RTX 50 시리즈 GPU가 메모리에서 모델을 동시에 실행할 수 있게 됐습니다.
또한, 스테이블 디퓨전 3.5 라지와 미디엄 모델은 TensorRT를 통해 최적화되었는데요. TensorRT는 Tensor 코어를 최대한 활용할 수 있도록 설계된 AI 백엔드로, 모델의 가중치와 모델 실행을 위한 명령 체계인 그래프를 RTX GPU에 맞게 최적화합니다.
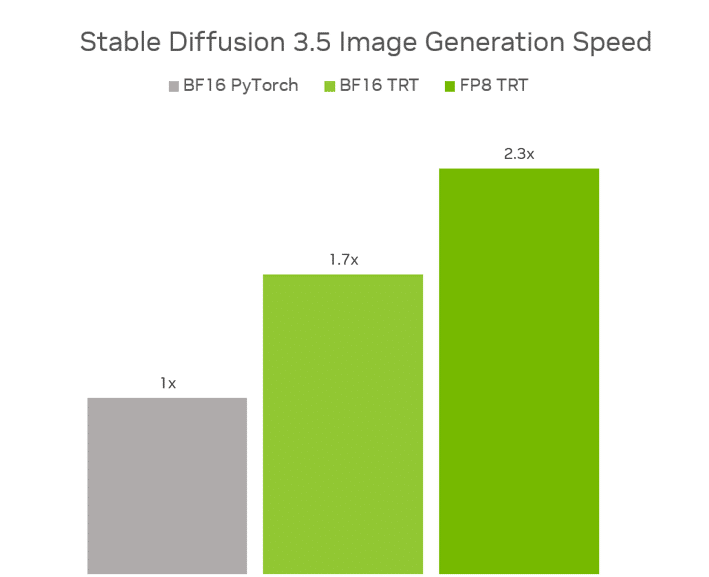
FP8 TensorRT를 적용한 결과, 스테이블 디퓨전 3.5 라지 모델은 BF16 파이토치(PyTorch)에서 실행했을 때보다 성능이 2.3배 향상되었고, 메모리 사용량은 40% 감소했죠. 스테이블 디퓨전 3.5 미디엄 모델도 BF16 TensorRT를 통해 BF16 파이토치 대비 1.7배 더 높은 성능을 발휘했습니다.
이처럼 최적화된 모델은 현재 스태빌리티 AI의 허깅페이스(Hugging Face) 페이지에서 이용할 수 있습니다.
또한, 스테이블 디퓨전 3.5 모델을 NVIDIA NIM 마이크로서비스 형태로도 출시할 계획입니다. 이를 통해 크리에이터와 개발자는 다양한 애플리케이션에서 보다 쉽게 모델을 접근하고 배포할 수 있게 되죠. 해당 NIM 마이크로서비스는 오는 7월 출시될 예정입니다.
RTX용 TensorRT SDK 출시
NVIDIA RTX용 TensorRT가 독립형 SDK로 새롭게 제공됩니다. 지난 마이크로소프트 빌드(Microsoft Build)에서 발표된 RTX용 TensorRT는 이미 새로운 윈도우 ML(Windows ML) 프레임워크의 일부로 프리뷰 버전으로 제공되고 있습니다.
기존에는 개발자가 각 GPU 클래스에 맞는 TensorRT 엔진을 미리 생성하고 패키징해야 했습니다. 이 과정은 GPU별 최적화가 가능하지만, 시간이 많이 소요되는 단점이 있었죠.
그러나 새로운 버전의 TensorRT를 사용하면 개발자는 단 몇 초 만에 디바이스에 최적화되는 범용 TensorRT 엔진을 생성할 수 있습니다. 이 JIT 컴파일 방식은 소프트웨어 설치 시 또는 기능을 처음 사용할 때 백그라운드에서 실행됩니다.
새로운 SDK는 통합이 간편해지고, 이전 대비 8배 더 작아졌습니다. 마이크로소프트의 새로운 AI 추론 백엔드인 윈도우 ML을 통해 쉽게 호출할 수 있죠. 새로운 독립형 SDK는 NVIDIA 개발자(NVIDIA Developer) 페이지에서 다운로드하거나, 윈도우 ML 프리뷰를 통해 테스트해볼 수 있습니다.
자세한 내용은 NVIDIA 테크니컬 블로그와 마이크로소프트 빌드 관련 블로그 게시글을 통해 확인할 수 있습니다.
NVIDIA GTC Paris
지난 주 프랑스 파리에서 열린 유럽 최대 규모의 스타트업, 기술 행사인 VivaTech 기간 중에 NVIDIA GTC Paris를 개최했습니다. 특히 NVIDIA 젠슨 황 CEO는 클라우드 AI 인프라, 에이전틱 AI, 물리 AI의 최신 혁신을 주제로 키노트를 진행했습니다.
이번 GTC Paris에서는 업계 리더들이 이끄는 실습 데모와 기술 세션이 다양하게 마련됐으며, 온라인과 오프라인으로 동시에 진행돼 많은 참가자들의 관심을 끌었습니다.
매주 RTX AI Garage 블로그 시리즈에서는 커뮤니티가 주도하는 AI 혁신과 콘텐츠를 통해, NIM 마이크로서비스와 AI Blueprint에 대해 자세히 소개합니다. 또한, AI PC와 워크스테이션에서 AI 에이전트, 크리에이티브 워크플로우, 디지털 휴먼, 생산성 앱 등을 구축하려는 사람들을 위한 정보를 제공합니다.
RTX AI PC 뉴스레터를 구독하거나 페이스북(Facebook), 인스타그램(Instagram), 틱톡(TikTok), X 채널을 구독해 최신 소식을 받아보세요. 그리고 NVIDIA Workstation의 링크드인(LinkedIn), X 채널에서도 관련 소식을 확인할 수 있습니다.
소프트웨어 제품 정보에 대한 안내를 확인하세요.