
오픈AI(OpenAI)와의 협력을 바탕으로 NVIDIA GPU에서 오픈AI의 새로운 오픈오픈 소스인 gpt-oss 모델을 최적화했습니다. 이를 통해 클라우드부터 PC까지 빠르고 스마트한 추론이 가능해졌죠. 새로운 추론 모델은 웹 검색, 심층 연구 등 다양한 에이전틱 AI 애플리케이션을 지원합니다.
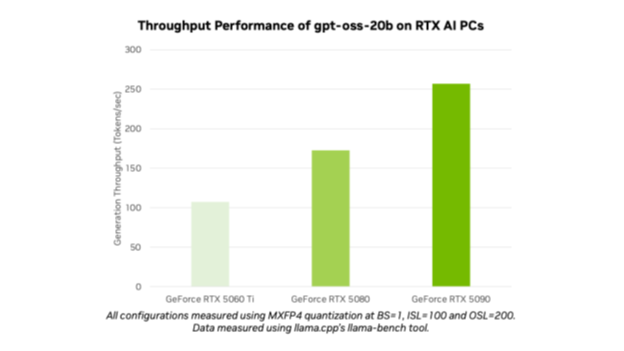
오픈AI는 gpt-oss-20b와 gpt-oss-120b를 출시해 수백만 명의 사용자에게 최첨단 모델을 공개했습니다. AI 애호가와 개발자는 올라마(Ollama), 라마.cpp(llama.cpp), 마이크로소프트 AI 파운드리 로컬(Microsoft AI Foundry Local) 등 인기 도구와 프레임워크를 통해, NVIDIA RTX AI PC와 워크스테이션에서 최적화된 모델을 사용할 수 있죠. 이와 함께 NVIDIA GeForce RTX 5090 GPU에서 초당 최대 256개 토큰의 성능을 경험할 수 있습니다.
NVIDIA 창립자 겸 CEO 젠슨 황(Jensen Huang)은 “오픈AI는 NVIDIA AI를 기반으로 무엇을 구축할 수 있는지 세상에 보여줬습니다. 그리고 이제 오픈소스 소프트웨어 분야에서의 혁신을 이끌고 있죠. gpt-oss 모델은 전 세계 개발자들이 최첨단 오픈소스 기반 위에 구축할 수 있도록 지원하고, 세계 최대 규모의 AI 컴퓨팅 인프라를 기반으로 미국의 AI 기술 리더십을 강화할 것”이라고 말했습니다.
이번 모델 출시는 훈련부터 추론, 클라우드부터 AI PC에 이르는 NVIDIA의 AI 리더십을 보여줍니다.
모두에게 오픈
gpt-oss-20b와 gpt-oss-120b는 사고 사슬(chain-of-thought) 기능을 갖추고 있습니다. 그리고 널리 사용되는 전문가 혼합 방식(mixture-of-experts, MoE) 아키텍처를 활용해 추론 강도를 조절할 수 있는 유연한 오픈 웨이트(open-weight) 추론 모델이죠. 이 모델은 지시 이행(instruction-following), 도구 사용(tool use)과 같은 기능을 지원하도록 설계됐으며, NVIDIA H100 GPU에서 훈련됐습니다. AI 개발자는 NVIDIA 테크니컬 블로그에서 자세한 내용을 알아보고 지침을 참조해 시작할 수 있습니다.
이 모델은 로컬 추론에서 가장 긴 수준인 최대 131,072 컨텍스트 길이를 지원합니다. 따라서 컨텍스트 기반 문제를 추론할 수 있어 웹 검색, 코딩 지원, 문서 이해, 심층 연구와 같은 작업에 이상적이죠.
또한, 이 오픈AI 개방형 모델은 NVIDIA RTX에서 지원되는 최초의 MXFP4 모델입니다. MXFP4는 높은 모델 품질을 유지하면서도 다른 정밀도 유형 대비 적은 리소스를 사용해 빠르고 효율적인 성능을 제공합니다.
올라마로 NVIDIA RTX에서 오픈AI 모델 실행하기
새로운 올라마 앱은 VRAM 24GB 이상의 GPU를 갖춘 RTX AI PC에서 이 오픈AI 모델을 테스트할 수 있는 가장 쉬운 방법입니다. 올라마는 손쉬운 통합으로 AI 애호가와 개발자에게 인기를 끌고 있죠. 또한, 새로운 사용자 인터페이스(UI)는 오픈AI의 오픈 웨이트 모델을 기본적으로 지원합니다. 올라마는 RTX에 완전히 최적화돼 개인용 AI를 PC나 워크스테이션에서 경험하고자 하는 사용자에게 이상적입니다.
올라마를 설치하면 모델과 빠르고 쉽게 대화할 수 있는데요. 드롭다운 메뉴에서 모델을 선택하고 메시지를 보내기만 하면 됩니다. 올라마는 RTX에 최적화돼 있으므로, 지원되는 GPU에서 최상의 성능을 내기 위해 별도의 설정이나 명령어가 필요하지 않습니다.

올라마의 새로운 앱에는 PDF나 텍스트 파일을 채팅 내에서 간편하게 지원하는 기능, 적용 가능한 모델에서 사용자가 프롬프트에 이미지를 포함할 수 있게 하는 멀티모달 지원, 대용량 문서나 채팅 작업 시 쉽게 조절 가능한 컨텍스트 길이 등 다양한 새로운 기능이 포함돼 있습니다.
개발자는 명령줄 인터페이스(CLI)나 앱의 소프트웨어 개발 키트(SDK)로 올라마를 사용해 애플리케이션과 워크플로우를 실행할 수 있습니다.
RTX에서 신규 오픈AI 모델을 사용하는 또 다른 방법
AI 애호가와 개발자는 최소 16GB VRAM이 탑재된 GPU에서 RTX로 구동되는 다양한 애플리케이션과 프레임워크를 통해 RTX AI PC에서 gpt-oss 모델을 사용해 볼 수 있습니다.
NVIDIA는 RTX GPU 성능을 최적화하기 위해 라마.cpp와 GGML Tensor 라이브러리 모두에서 오픈 소스 커뮤니티와 지속적으로 협력하고 있습니다. 최근에는 오버헤드를 낮추기 위해 CUDA Graphs를 도입하고 CPU 오버헤드 감소 알고리즘을 추가하는 등 다양한 성과가 있었죠. 이는 라마.cpp 깃허브(GitHub) 리포지토리를 확인해 시작할 수 있습니다.
윈도우(Windows) 개발자는 현재 공개 프리뷰 중인 마이크로소프트 AI 파운드리 로컬을 통해 오픈AI의 새 모델에 접근할 수 있습니다. 파운드리 로컬은 명령줄, SDK, 애플리케이션 프로그래밍 인터페이스(API)를 통해 워크플로우에 통합되는 온디바이스 AI 추론 솔루션입니다. 파운드리 로컬은 CUDA를 통해 최적화된 ONNX 런타임(ONNX Runtime)을 사용하며, 가까운 시일 내로 RTX용 NVIDIA TensorRT를 지원할 예정입니다. 시작 방법은 간단합니다. 파운드리 로컬을 설치하고 “Foundry model run gpt-oss-20b”을 터미널에 입력하면 되죠.
이번 오픈 소스 모델의 출시는 AI 가속 윈도우 애플리케이션에 추론 기능을 추가하려는 AI 애호가와 개발자들의 차세대 AI 혁신을 이끕니다.
매주 RTX AI Garage 블로그 시리즈에서는 커뮤니티가 주도하는 AI 혁신과 콘텐츠를 통해, NIM 마이크로서비스와 AI Blueprint에 대해 자세히 알아보고 있습니다. 또한, AI PC와 워크스테이션에서 AI 에이전트, 크리에이티브 워크플로우, 디지털 휴먼, 생산성 앱 등을 구축하려는 사람들을 위한 정보를 제공합니다.
RTX AI PC 뉴스레터를 구독하거나 페이스북(Facebook), 인스타그램(Instagram), 틱톡(TikTok), X 채널을 구독해 최신 소식을 받아볼 수 있습니다. NVIDIA의 디스코드(Discord) 서버에 참여하면 커뮤니티 개발자, AI 애호가와 함께 RTX AI의 가능성을 토론해 볼 수 있습니다.
NVIDIA Workstation의 링크드인(LinkedIn), X 채널에서도 관련 소식을 확인할 수 있습니다.
소프트웨어 제품 정보에 대한 안내를 확인할 수 있습니다.