
엔비디아의 AI 플랫폼은 최신 MLPerf 업계 벤치마크에서 AI 트레이닝 및 고성능 컴퓨팅의 기준을 높였습니다.
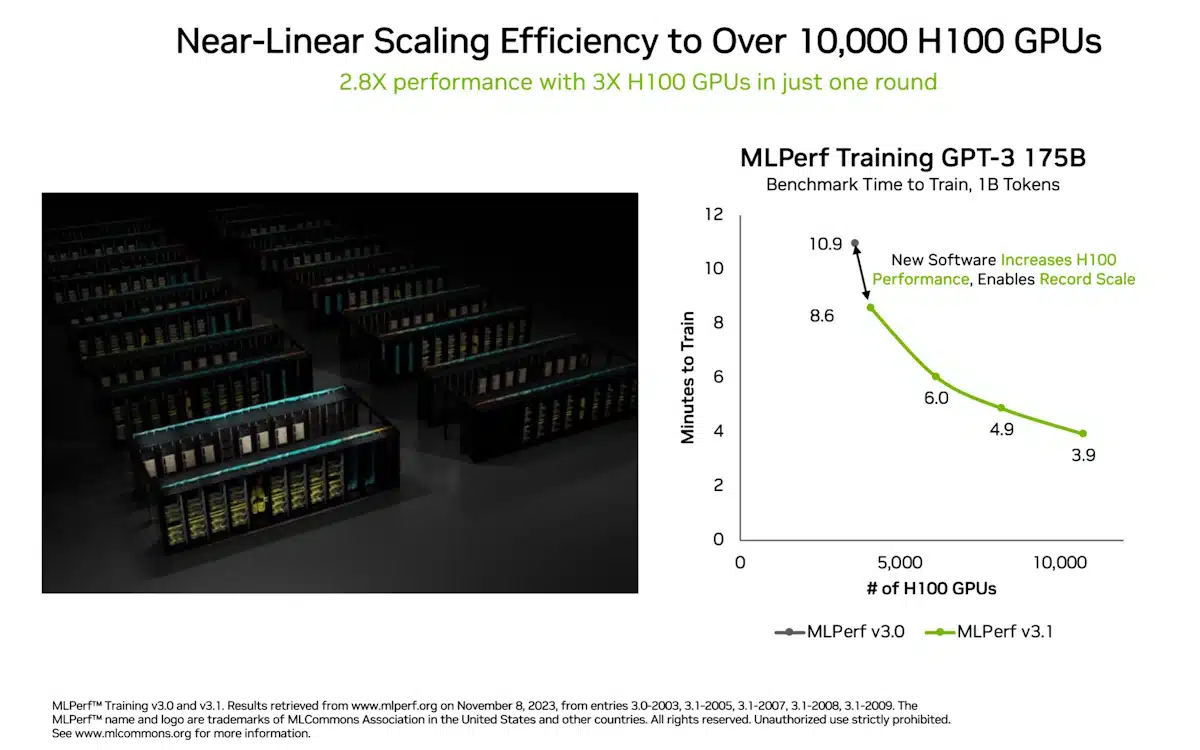
많은 새로운 기록과 이정표 중에서도 주목할 만한 것은 생성형 AI 분야입니다: 무려 10,752개의 NVIDIA H100 Tensor 코어 GPU와 NVIDIA Quantum-2 InfiniBand 네트워킹으로 구동되는 AI 슈퍼컴퓨터인 NVIDIA Eos는 10억 개의 토큰에 대해 1,750억 개의 파라미터를 훈련하는 GPT-3 모델을 기반으로 한 훈련 벤치마크를 단 3.9분 만에 완료했습니다.
이는 6개월 전 이 테스트를 도입했을 때 엔비디아가 세운 기록인 10.9분에서 거의 3배 가까이 향상된 속도입니다.

이 벤치마크는 인기 있는 ChatGPT 서비스의 전체 GPT-3 데이터 세트의 일부를 사용하며, 추정에 따르면 Eos는 이제 512개의 A100 GPU를 사용하는 이전 최첨단 시스템보다 73배 빠른 단 8일 만에 트레이닝할 수 있습니다.
트레이닝 시간이 단축됨에 따라 비용이 절감되고 에너지가 절약되며 출시 기간이 단축됩니다. 또한 대규모 언어 모델을 광범위하게 사용할 수 있어 모든 기업이 LLM 커스터마이징을 위한 프레임워크인 NVIDIA NeMo와 같은 도구를 사용하여 이를 채택할 수 있습니다.
이번 새로운 생성형 AI 테스트에서 1,024개의 NVIDIA Hopper 아키텍처 GPU는 2.5분 만에 Stable Diffusion 텍스트-이미지 모델 기반 트레이닝 벤치마크를 완료하여 이 새로운 워크로드에 대한 높은 기준을 세웠습니다.
생성형 AI는 우리 시대의 가장 혁신적인 기술인 만큼, MLPerf는 이 두 가지 테스트를 채택함으로써 AI 성능 측정을 위한 업계 표준으로서의 리더십을 강화했습니다.
시스템 확장성 급증
최신 결과는 부분적으로는 MLPerf 벤치마크에 역대 가장 많은 가속기가 사용되었기 때문입니다. 10,752개의 H100 GPU는 3,584개의 Hopper GPU를 사용했던 6월의 AI 트레이닝 확장을 훨씬 뛰어넘는 수치입니다.
GPU 수의 3배 확장은 부분적으로 소프트웨어 최적화 덕분에 2.8배의 성능과 93%의 효율을 제공했습니다.
LLM은 매년 엄청난 규모로 성장하고 있기 때문에 효율적인 확장은 생성형 AI의 핵심 요건입니다. 최신 결과는 세계 최대 규모의 데이터센터에서도 이 전례 없는 과제를 해결할 수 있는 NVIDIA의 능력을 보여줍니다.
이러한 성과는 Eos와 Microsoft Azure가 최신 라운드에서 사용한 가속기, 시스템 및 소프트웨어의 혁신으로 구성된 풀 스택 플랫폼 덕분입니다.
Eos와 Azure는 각각 10,752개의 H100 GPU를 사용했습니다. 두 제품은 동일한 성능에서 2% 이내의 차이를 보이며 데이터센터 및 퍼블릭 클라우드 배포에서 NVIDIA AI의 효율성을 입증했습니다.

NVIDIA는 다양한 중요 작업에 Eos를 사용합니다. 최첨단 컴퓨터 그래픽을 위한 AI 기반 소프트웨어인 NVIDIA DLSS와 같은 이니셔티브와 차세대 GPU를 설계하는 데 도움이 되는 생성형 AI 도구인 ChipNeMo와 같은 NVIDIA 연구 프로젝트를 발전시키는 데 도움이 됩니다.
워크로드 전반의 발전
엔비디아는 이번 라운드에서 생성형 AI의 발전과 더불어 여러 가지 새로운 기록을 세웠습니다.
예를 들어, H100 GPU는 사용자가 온라인에서 원하는 것을 찾는 데 널리 사용되는 이전 라운드의 트레이닝 추천 모델보다 1.6배 더 빨랐습니다. 컴퓨터 비전 모델인 RetinaNet의 성능은 1.8배 향상되었습니다.
이러한 성능 향상은 소프트웨어의 발전과 확장된 하드웨어의 조합으로 이루어졌습니다.
엔비디아는 다시 한 번 모든 MLPerf 테스트를 실행한 유일한 기업이었습니다. H100 GPU는 9개의 벤치마크 각각에서 가장 빠른 성능과 가장 큰 확장을 보여주었습니다.

속도 향상은 대규모 LLM을 트레이닝하거나 비즈니스의 특정 요구 사항에 맞게 NeMo와 같은 프레임워크로 커스터마이징하는 사용자의 시장 출시 시간 단축, 비용 절감 및 에너지 절약으로 이어집니다.
이번 라운드에는 ASUS, Dell Technologies, Fujitsu, GIGABYTE, Lenovo, QCT 및 Supermicro를 포함한 11개 시스템 제조업체가 출품작에 NVIDIA AI 플랫폼을 사용했습니다.
NVIDIA 파트너들은 MLPerf가 AI 플랫폼과 벤더를 평가하는 고객에게 유용한 도구라는 것을 알고 있기 때문에 MLPerf에 참여하고 있습니다.
HPC 벤치마크 확장
슈퍼컴퓨터에서 AI 지원 시뮬레이션을 위한 별도의 벤치마크인 MLPerf HPC에서 H100 GPU는 지난 HPC 라운드에서 NVIDIA A100 Tensor 코어 GPU보다 최대 2배의 성능을 제공했습니다. 결과는 2019년 첫 번째 MLPerf HPC 라운드 이후 최대 16배의 향상을 보여주었습니다.
이 벤치마크에는 아미노산 서열로부터 단백질의 3D 구조를 예측하는 모델인 OpenFold를 훈련하는 새로운 테스트가 포함되었습니다. OpenFold는 연구자들이 몇 주 또는 몇 달이 걸리던 의료 분야의 중요한 작업을 몇 분 만에 수행할 수 있습니다.
대부분의 약물은 많은 생물학적 과정을 제어하는 세포 기계인 단백질에 작용하기 때문에 단백질의 구조를 이해하는 것은 효과적인 약물을 빠르게 찾는 데 핵심입니다.
MLPerf HPC 테스트에서 H100 GPU는 7.5분 만에 OpenFold를 훈련시켰습니다. 오픈폴드 테스트는 2년 전 128개의 가속기를 사용해 11일이 걸렸던 전체 알파폴드 훈련 과정의 대표적인 부분입니다.
오픈폴드 모델과 이를 훈련하는 데 사용된 엔비디아의 소프트웨어 버전은 곧 신약 개발을 위한 생성형 AI 플랫폼인 NVIDIA BioNeMo에서 사용할 수 있게 될 예정입니다.
이번 공모에는 여러 파트너가 NVIDIA AI 플랫폼에 대한 제안서를 제출했습니다. 여기에는 Dell Technologies와 Clemson University의 슈퍼컴퓨팅 센터, Texas Advanced Computing Center, 그리고 Hewlett Packard Enterprise(HPE)의 지원을 받은 Lawrence Berkeley 국립 연구소가 포함되었습니다.
폭넓은 지원을 받는 벤치마크
2018년 5월에 시작된 이래 MLPerf 벤치마크는 업계와 학계 모두로부터 폭넓은 지지를 받고 있습니다. 이를 지원하는 조직에는 Amazon, Arm, Baidu, Google, Harvard, HPE, Intel, Lenovo, Meta, Microsoft, NVIDIA, Stanford University 및 Toronto University가 포함됩니다.
MLPerf 테스트는 투명하고 객관적이므로 사용자는 결과를 바탕으로 정보에 입각한 구매 결정을 내릴 수 있습니다.
NVIDIA가 사용한 모든 소프트웨어는 MLPerf 리포지토리에서 사용할 수 있으므로 모든 개발자가 동일한 세계 최고 수준의 결과를 얻을 수 있습니다. 이러한 소프트웨어 최적화는 GPU 애플리케이션을 위한 NVIDIA의 소프트웨어 허브인 NGC에서 사용할 수 있는 컨테이너로 지속적으로 접혀집니다.