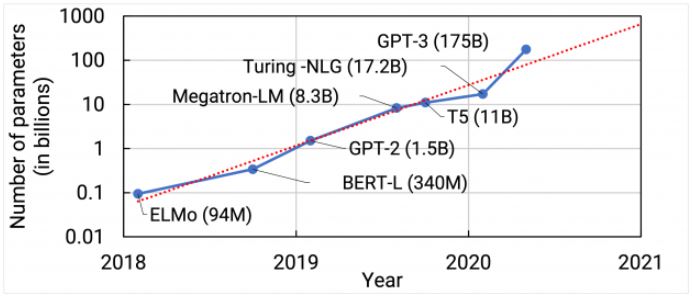
자연어 처리(NLP, Natural Language Processing)는 최근 몇 년간 대규모 계산이 쉽게 이뤄지고 데이터세트 용량이 커지면서 빠르게 발전했습니다. 최근 연구에 따르면 대규모 언어 모델은 추가 미세 조정이 없이도 높은 정확도를 지닌 여러 NLP 데이터세트로 퓨샷 러닝(Few-Shot Learning)을 할 수 있는데요. 그 결과 최신 NLP 모델이 기하급수적으로 성장했죠(그림 1). 그렇지만 이런 모델 훈련에는 다음과 같은 두 가지 이유 때문에 문제가 발생합니다.
- 아무리 가장 큰 GPU에 있는 메인 메모리라도 모델 매개변수(parameter)를 담지 못합니다.
- 호스트와 장치 메모리 간에 매개변수를 교체하는 식으로 모델을 단일 GPU에 맞추더라도, 수많은 컴퓨팅 작업이 요구되기 때문에 병렬처리(parallelization)를 하지 않으면 훈련시간이 비현실적으로 길어질 수 있습니다. 예를 들어, 1,750억개의 매개변수를 둔 GPT-3 모델을 훈련하면 8개의 V100 GPU로 36년 걸리거나 512개의 V100 GPU로는 7개월이 걸립니다.
이전에 게재된 Megatron 글에서 텐서 (intralayer) 모델 병렬처리가 이러한 한계점들을 어떻게 극복하여 사용될 수 있는지 확인한 바 있습니다. 이 접근 방식은 DGX A100 서버 (8개의 A100 GPU)에서 최대 200억개의 매개변수 크기의 모델에서는 적합했지만, 더 큰 모델에서는 잘 작동하지 않습니다. 더 큰 모델은 여러 개의 DGX A100 서버로 분할시켜야 하므로 다음과 같은 두 가지 문제점이 발생합니다.
- 텐서 모델 병렬처리에 필요한 올-리듀스 통신(all-reduce communication)은 DGX A100 서버에서 사용할 수 있는 고대역폭 NVLink 링크보다 느린 서버간 링크를 거쳐야 합니다.
- 모델 병렬처리 수준이 높으면 GEMM이 작아져 GPU 활용률이 축소될 수 있습니다.
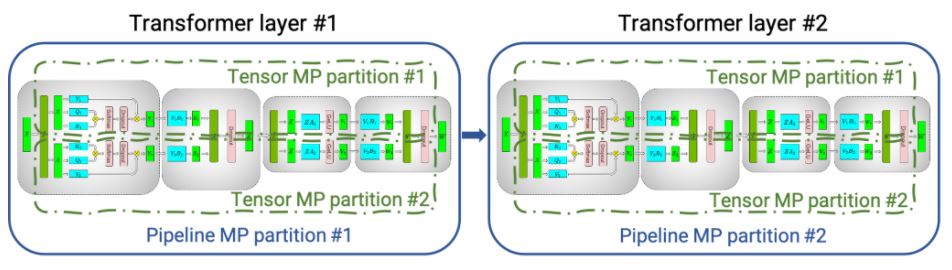
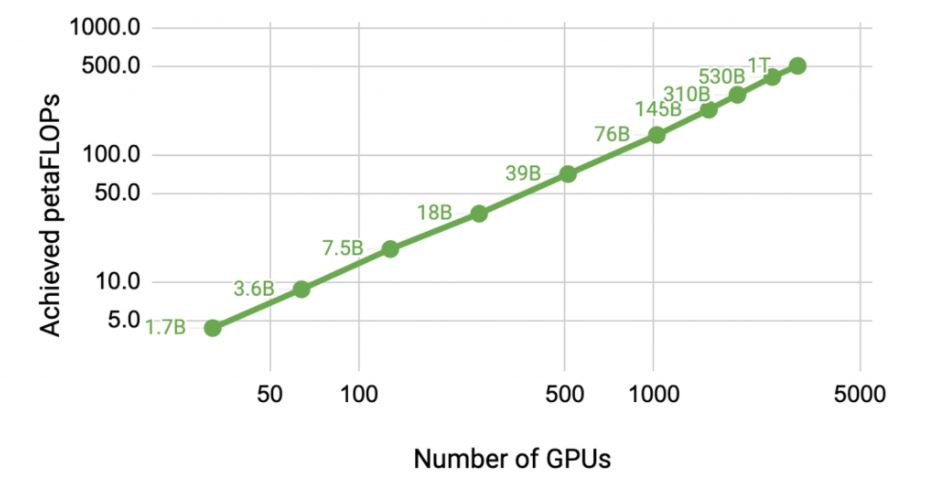
이러한 한계를 해결하기 위해 NVIDIA는 텐서 모델 병렬처리를 파이프라인 (interlayer) (모델) 병렬처리와 결합했습니다. 파이프라인 병렬처리는 처음에 PipeDream과 GPipe에서 사용됐지만, 현재는 DeepSpeed와 같은 시스템에서도 사용할 수 있습니다. DGX A100 서버 내부에서는 텐서 모델 병렬처리를 사용하고 DGX A100 서버 간에는 파이프라인 병렬처리를 사용했습니다. <그림 2>는 텐서와 파이프라인 모델 병렬처리를 이렇게 결합한 것입니다. 이 두 형태의 모델 병렬처리를 데이터 병렬처리와 결합하면, NVIDIA Selene 슈퍼컴퓨터에서 1조개의 매개변수가 있는 모델로 확장할 수 있습니다(그림3). 본 글에 소개된 모델들은 컨버전스로 훈련하지 않았습니다. 수백 번의 이터레이션(iteration)만을 수행해 이터레이션당 시간을 측정했습니다.
32개의 GPU에서 약 10억개의 매개변수가 있는 모델을 3,072개의 A100 GPU에서 약 1조개의 매개변수가 있는 모델로 바꿔 사용하면 총 처리량이 114배 향상됩니다. 1,024개의 A100 GPU에서 8-웨이(way) 텐서 병렬처리와 8-웨이 파이프라인 병렬처리를 사용하면 1,750억개의 매개변수를 둔 GPT-3 모델을 한 달 만에 훈련시킬 수 있습니다. 1조개의 매개변수를 둔 GPT 모델에서 GPU 당 엔드-투-엔드 처리량 163 테라플롭스(통신 포함)를 달성했습니다. 이는 장치 처리량 최대치 (312 테라플롭스(TFLOPs))의 52%이자, 3,072개의 A100 GPU에서의 총 처리량 502 페타플롭스에 해당합니다.
본 실험은 NVIDIA/Megatron-LM GitHub 저장소에서 오픈소스에서 확인하실 수 있습니다! 본 글에서는 이런 실험결과를 이끌어낸 기술을 설명하겠습니다. 자세한 내용은 NVIDIA 논문 “GPU 클러스터로 효율적인 대규모 언어모델 훈련”에서 확인하세요.
파이프라인 병렬처리 (Pipeline parallelism)
파이프라인 병렬처리를 통해 모델 레이어는 여러 장치로 분할됩니다. 반복적인 트랜스포머(repetitive transformer) 기반 모델에서 사용하면 각 장치에는 트랜스포머 레이어가 동일한 수로 할당됩니다. 배치(batch)는 마이크로배치(microbatch)로 나뉩니다. 명령은 파이프라인으로 연결된 마이크로배치들을 거쳐 수행됩니다. 바닐라 옵티마이저 시매틱스(vanilla optimizer semantics)를 유지하기 위해 옵티마이저 단계가 장치 간에 동기화되도록 주기적으로 파이프라인 플러시(pipeline flush)가 적용됩니다. 모든 배치의 시작과 끝에는 장치가 유휴 상태로 머무는 시간이 있습니다. 이 유휴 시간을 파이프라인 버블(pipeline bubble)이라고 부르는데 이 유휴시간은 최대한 줄이는 게 좋지요.
여러 장치에서 마이크로배치를 순방향과 역방향으로 스케줄링(scheduling)하는 방법은 여러가지가 있는데요. 각 접근 방식은 파이프라인 버블 크기, 통신량, 메모리 풋프린트 면에서 각기 다른 장단점이 있습니다. 여기서는 두 가지 방식에 대해 설명하겠습니다.
기본 스케줄 (Default schedule)
GPipe는 배치 안의 모든 마이크로배치에 대해서 순방향 패스으로 먼저 진행한 이후에 모든 마이크로 배치에 대해 역방향 패스로 진행하는 방식으로 스케줄링합니다. <그림 4>는 이런 기본 스케줄을 보여줍니다. 이 방식은 배치 내의 모든 마이크로배치에 대해 저장된 중간 활성화(stashed intermediate activation) (또는 활성화 재계산을 사용하는 경우 각 파이프라인 단계에 대한 입력 활성화)가 필요하기 때문에 메모리 풋프린트가 큽니다. 배치 규모가 큰 경우에는 일반적으로 파이프라인 버블 비용을 줄이는 노력이 필요한데, 이 기본 스케줄은 메모리 풋프린트가 높아 실용성이 떨어지게 됩니다.
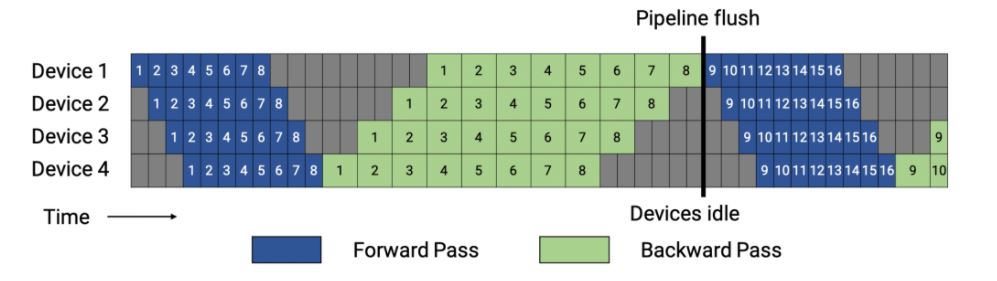
<그림 4>에서는 단순하게 역방향 패스가 순방향 패스보다 시간이 두 배 더 오래 걸린다고 가정했습니다(wgrad, dgrad). 파이프라인 스케줄의 효율성은 이 비율과는 상관없습니다. 위 예시에 나온 각 배치는 8개의 마이크로배치로 구성되며 각 상자에 붙여진 번호는 마이크로배치에 부여된 고유 식별번호입니다. 옵티마이저는 단계적으로 진행되고 파이프라인 플러시에서 가중치(weight) 매개변수가 업데이트됩니다.
이제는 PipeDream-Flush 스케줄을 적용해보겠습니다. PipeDream-Flush 스케줄은 먼저 워밍업 단계로 시작됩니다(그림 5). 이 스케줄에서는 인-플라이트(in-flight) 마이크로배치의 개수(역방향 패스가 진행중이고 활성화가 유지돼야 하는 상황에서의 마이크로배치 개수)가 배치 안의 마이크로배치 개수에 연동되는 것이 아니라 파이프라인 깊이에 따라 연동됩니다. 워밍업 단계를 마치면 작업자는 한번은 순방향 패스를, 그 다음 한번은 역방향 패스(1F1B)를 하는 일반적인 상태로 넘어갑니다. 마지막으로, 배치를 끝낼 때 남은 모든 인-플라이트 마이크로 배치는 역방향 패스로 완료됩니다.
파이프라인 버블 크기(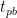


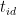
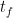
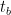

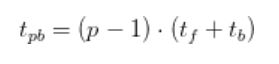
배치의 이상적인 처리 시간은 다음과 같습니다.
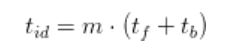
그렇다면 파이프라인 버블에 소요된 총시간은 다음처럼 계산할 수 있습니다.
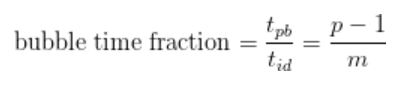
버블 시간 비율을 줄이려면 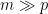
인터리브드 스케줄(Interleaved schedule)
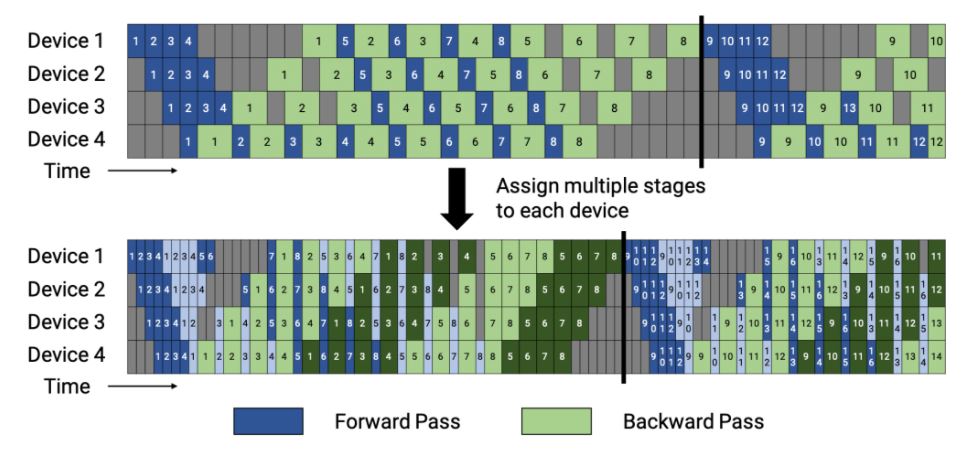
파이프라인 버블 크기를 줄이기 위해 각 장치는 한 개의 연속 레이어 세트가 아닌, ‘모델 청크(model chunk)’라고 부르는 여러 개의 레이어 서브세트로 계산할 수 있습니다. 예를 들어, 각 장치에서 4개의 레이어로 계산하면, 각 장치에 연속된 레이어 세트를 두는 대신, 각각 2개의 레이어가 있는 2개의 모델 청크로 나뉠 수 있습니다(장치 1에 레이어 1~4, 장치 2에 레이어 5~8 등등). 이런 체계로 파이프라인의 각 장치에는 여러 단계가 할당됩니다.
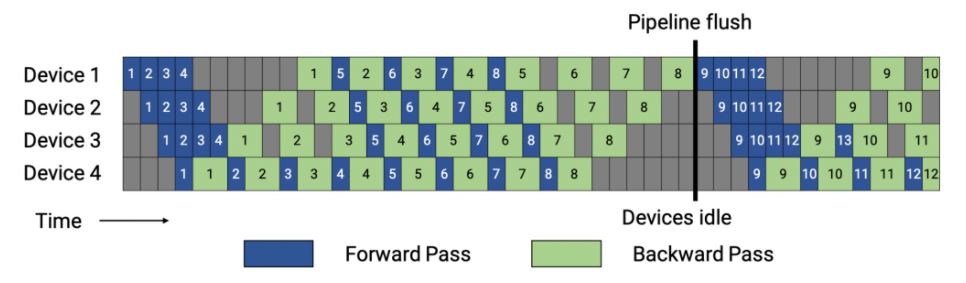
앞서 소개한 스케줄처럼 이 스케줄도 모두 순방향 패스와 모두 역방향 패스로 진행할 수 있지만 그렇게 되면 메모리 풋프린트가 높아집니다. 그런 점을 보안하기 위해, 메모리 효율적인 1F1B 방식으로 이 인터리브드 스케줄이 개발됐는데요. <그림 6>이 바로 인터리브드 스케줄입니다. 이는 배치 안의 마이크로배치의 개수가 파이프라인 병렬처리 수준의 정수 곱이 됩니다(파이프라인의 장치 개수). 예를 들어 장치가 4개인 경우 배치 안의 마이크로배치 개수는 4의 배수가 됩니다.
<그림 6>에서 볼 수 있듯이 동일한 배치 크기에 대해 파이프라인 플러시는 이 새로운 스케줄에서 더 빨리 발생합니다. 각 장치에 단계 (모델 청크)가 있다고 하면 각 단계에 대한 마이크로배치의 순방향과 역방향 시간은 각각 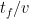
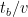
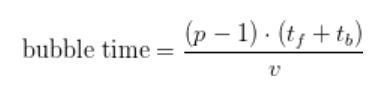
그러나 이렇게 파이프라인 버블 크기를 줄이는 데는 또 다른 노력이 필요한데요. 바로 추가로 통신이 요구되는 것이죠. 양적으로 봤을 때, 통신량은 