DGX A100 InfiniBand 네트워킹 카드를 통한 노드간 통신 최적화
파이프라인 설정에서 텐서는 순방향이나 역방향 병렬로 송수신돼야 합니다. 각 DGX A100에는 8개의 InfiniBand (IB) 네트워킹 카드가 장착돼 있는데요. 안타깝게도 송수신은 점대점 방식(point-to-point)으로, 두 서버의 GPU 간에서만 이뤄집니다. 이로 인해 단일 통신 통화(communication call)에서는 8개의 카드를 모두 활용하기가 어렵습니다.
그러나 노드 간 통신이라는 오버헤드를 줄이기 위해서 텐서 모델 병렬처리와 파이프라인 모델 병렬처리를 모두 활용하는 방법이 있습니다. 각 트랜스포머 레이어의 출력은 텐서-병렬 랭크(rank)에 걸쳐 복제됩니다( Megatron 논문의<그림 4>). 결과적으로 텐서 모델 병렬처리를 수행하는 두 개의 연속 파이프라인 단계에서의 랭크는 정확히 동일한 텐서 세트를 송수신합니다.
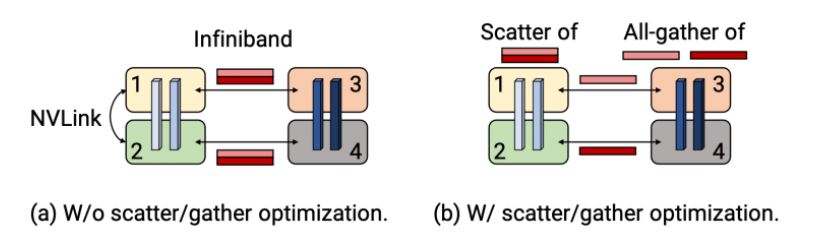
충분히 큰 모델에는 텐서-모델-병렬(tensor-model-parallel) 크기 8을 사용했습니다. 이는 동일한 텐서 세트를 인접한 다중 GPU 서버에서 해당 GPU 간에 8번 전송한다는 뜻입니다. 이러한 중복성을 줄이기 위해, 우린 송신 측의 텐서를 동일한 크기의 청크로 분할한 다음, 해당 랭크의 전용 IB 카드를 사용해 다음 노드에 있는 해당 랭크로 청크를 보냈습니다. 8개의 텐서-모델-병렬 랭크를 사용하면 각 청크는 8배 더 작아집니다.
수신기 측에서는 전체 텐서를 다시 구체화(re-materialize)하기 위해 NVLink에 걸쳐 모두 취합했는데, 이는 IB 상호연결보다 훨씬 빠릅니다(그림 7). 이를 ‘확산(scatter)/취합(gather) 통신 최적화’라고 부릅니다. 이 최적화는 DGX A100 서버에서 여러 IB 카드의 활용도를 높이며 인터리브드 스케줄처럼 통신이 많이 필요한 스케줄(communication-intensive schedule)에도 도움이 됩니다. 여기에 사용된 청킹 최적화(chunking optimization)는 ZeRO와 DeepSpeed의 메모리 풋프린트와 파이프라인 병렬 통신을 줄이기위한 활성화 파티셔닝(activation partitioning) 기술과 비슷합니다.
파이프라인 병렬처리에 대한 성능 마이크로벤치마크
이번 섹션에서는 이런 파이프라인 병렬처리 체계의 계산 성능을 평가해봅니다. 데이터 병렬처리는 이번 섹션에서 다루지 않았지만 글 후반부에서 데이터 병렬처리와 모델 병렬처리 결과 모두를 보여드리겠습니다.
파이프라인 병렬처리의 윅-스케일링 (Weak-scaling)
먼저 128개의 어텐션 헤드(attention head), 히든 사이즈(hidden size) 20480, 마이크로배치 크기 1로 GPT 모델을 사용해 ‘기본 비-인터리브 파이프라인 병렬처리 스케줄(default non-interleaved pipeline-parallel schedule)’의 윅-스케일링 성능을 평가해봤습니다.
파이프라인 단계 수를 늘렸기 때문에 그에 비례해 모델의 레이어 수를 늘려 모델의 크기도 늘렸습니다. 가령, 파이프라인 병렬 크기가 1인 경우엔 3개의 트랜스포머 레이어와 약 150억개의 매개변수가 있는 모델을 사용했습니다. 파이프라인 병렬 크기가 8인 경우엔 24개의 트랜스포머 레이어와 약 1,210억개의 매개변수가 있는 모델을 썼습니다. 모든 구성에 대해 텐서 병렬 크기는 8로 사용했고, A100 GPU를 총 8개에서 64개 사이로 다양하게 사용했습니다.
<그림 8>은 서로 다른 크기의 두 개의 배치에 따른 GPU 1개의 처리량을 보여줍니다. A100 GPU의 최대 장치 처리량은 312 테라플롭스입니다. 예상한대로 배치 크기가 높을수록 파이프라인 버블이 더 많은 마이크로배치(이 경우는 배치 크기와 동일)에 걸쳐 분산되기(amortized) 때문에 확장력이 더 높습니다.
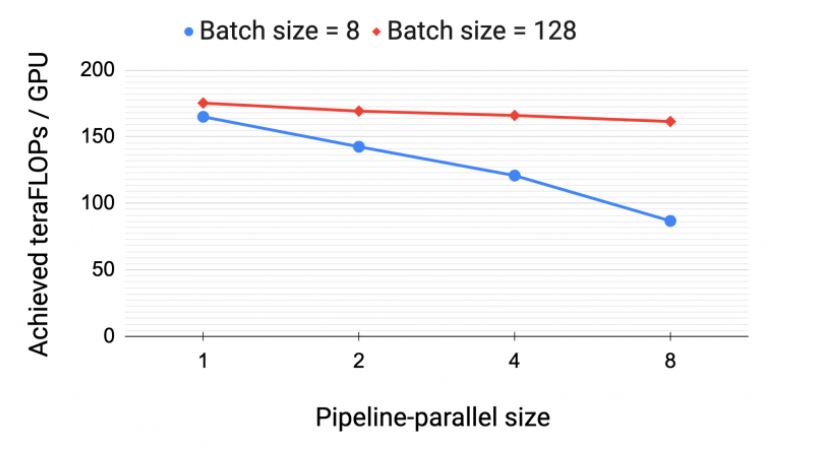
부동 소수점 연산(처리량의 분자) 수는 활성화 재계산(activation recomputation)을 고려해 모델 아키텍처를 기반으로 분석적으로 계산됩니다.
텐서 vs. 파이프라인 병렬처리
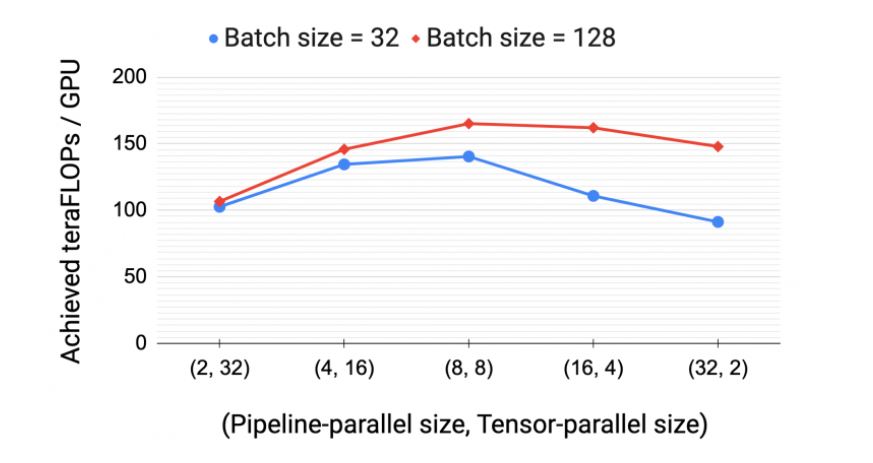
이 외에도, 병렬처리 구성이 모델과 배치 크기에 성능에 어떤 영향을 주는지 평가해봤습니다. <그림 9>의 실험 결과에 따르면, 161억개 매개변수를 둔 GPT 모델(트랜스포머 레이어 32, 어텐션 헤드 128, 히든 사이즈 20,480)을 훈련할 때는 텐서와 파이프라인 모델 병렬처리를 모두 함께 사용하는 것이 통신 오버헤드를 낮추고, 컴퓨팅 자원 활용률을 높이기 때문에 중요하다는 점을 보여줍니다. 하나의 노드(DGX A100 서버) 내부에서는 텐서 모델 병렬처리 하는 것이 고비용의 올-리듀스(All-Reduce) 통신 때문에 최고의 선택이 됩니다.
반면에 파이프라인 모델 병렬처리는 계산 전체에 걸쳐 병목현상을 일으키지 않으면서도 노드 간에 이뤄지는 점대점(point-to-point) 통신 비용이 훨씬 저렴합니다. 그러나 파이프라인 병렬 처리는 파이프라인 버블에서 걸리는 시간이 상당히 클 수 있습니다. 따라서 파이프라인의 마이크로배치 개수가 파이프라인 단계 개수를 적절히 곱한 값이 되도록 파이프라인 단계의 총 개수를 제한해야 합니다. 결과적으로, 텐서-병렬 크기가 단일 노드에서 GPU 개수와 같을 때(가령, (DGX A100 노드가 있는 Selene에서 GPU 가 8개인 경우) 최고의 성능을 보였습니다.
확산-취합 통신 최적화 (Scatter-gather optimization for communication)
<그림 10>은 1,750억개 매개변수가 있는 GPT 모델(어텐션 헤드 96개, 히든 사이즈 12,288, 트랜스포머 레이어 96개)에 대한 확산/취합 통신 최적화를 포함한 경우와 포함하지 않은 경우(즉, 최적화하지 않은 경우) GPU 당 처리량을 보여줍니다. 통신이 많이 필요한 스케줄(인터리빙이 있는 대규모 배치 크기)의 경우 종단간(end-to-end) 처리량이 최대 11%까지 향상됩니다. 이는 대형 모델에 대한 높은 훈련 처리량을 달성하는 데 DGX A100 IB 8개 카드가 중요하다는 점을 확실히 보여줍니다.
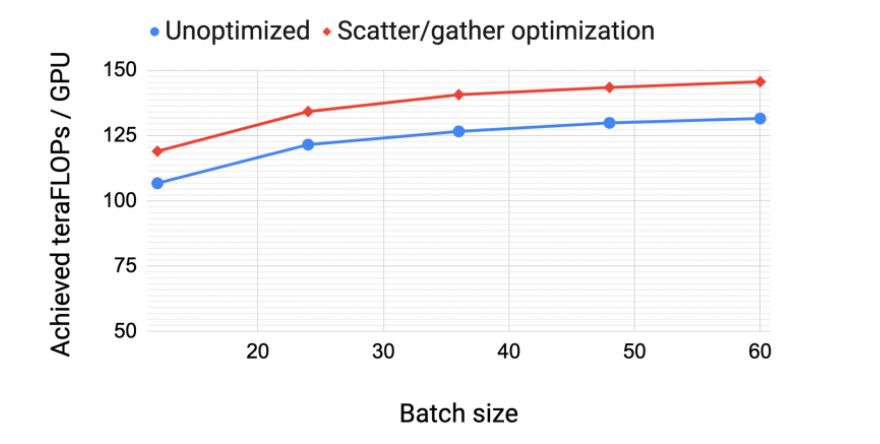
인터리브드 vs. 넌-인터리브드 스케줄
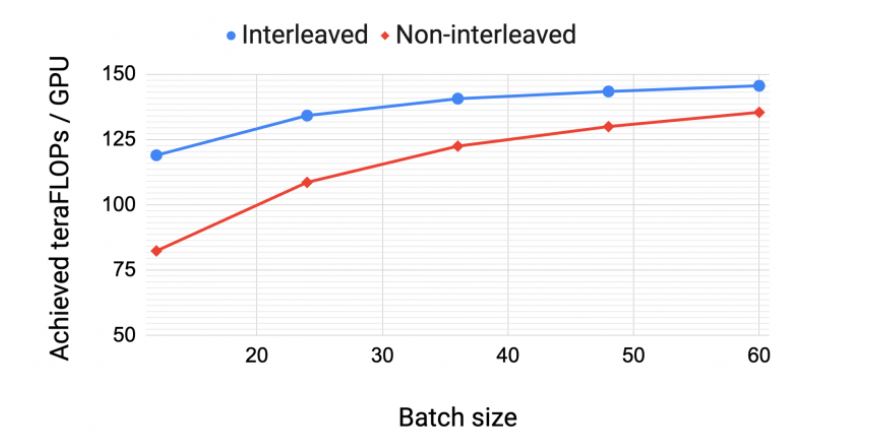
<그림 11>은 1,750억개의 매개변수를 둔 동일한 GPT 모델에서 인터리브드와 넌-인터리브 스케줄에 대한 GPU 당 처리량을 보여줍니다. 확산/취합 통신 최적화를 한 인터리브드 스케줄은 넌-인터리브드 (기본) 스케줄보다 계산 성능이 더 높습니다. 이 성능 차이는 배치 크기가 증가하면서 줄어드는데 그건 다음과 같은 두 가지 이유 때문입니다.
- 배치 크기가 증가하면 기본 스케줄의 버블 크기가 감소합니다.
- 파이프라인 내의 점대점 통신량은 배치 크기에 비례합니다. 결과적으로 넌-인터리브드 스케줄은 통신량이 증가하면서 인터리브드 스케줄 성능을 따라잡습니다.
확산/취합 최적화를 하지 않은 기본 스케줄(default schedule)은 더 큰 배치 크기에서 인터리브드 스케줄보다 수행성능이 높습니다(그래프엔 표시되지 않음).
모델과 데이터 병렬처리를 사용한 종단간 스케일링 (End-to-end scaling)
매개변수가 10억개에서 1조개에 이르는 GPT 모델에서 Megatron의 윅-스케일링 성능을 생각해봅시다. 확산/취합 최적화를 한 상태에서 텐서, 파이프라인, 데이터 병렬처리, 인터리브드 파이프라인 스케줄을 사용해봤습니다. 모든 모델에 단어(vocabulary) 크기 51,200개(1024의 배수)와 시퀀스 길이 2,048을 사용했습니다. 특정 모델 크기에 맞추기 위해 히든 사이즈, 어텐션 헤드 개수, 레이어 개수를 변경했습니다. 모델 크기가 증가하면 배치 크기와 GPU 개수도 늘렸습니다.
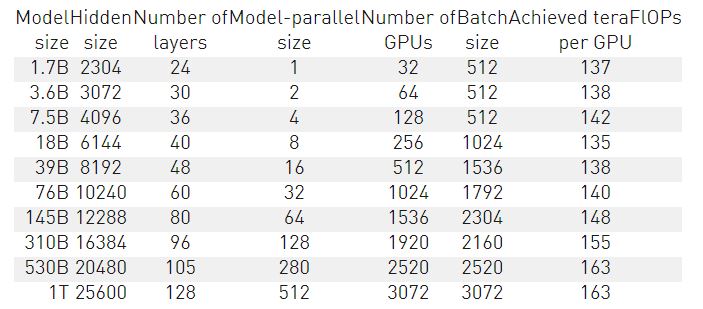
<표 1>은 다양한 모델 구성에 따라 달성된 초당 플롭스(GPU 1개 및 모든 GPU에 대한 합계)를 보여줍니다. <그림 1>에서 볼 수 있듯이 초당 플롭스는 3,072개의 A100 GPU (384개의 DGX A100 노드)까지 거의 완벽한 선형 관계에 있음을 확인했습니다. 처리량은 종단간 훈련(데이터 로딩, 최적화, 로깅을 포함한 모든 작업)에 대해 측정됩니다. 가장 큰 처리량의 경우는 플롭스의 이론적 최대치에 52%를 달성합니다.
마지막으로 <표 1>의 측정된 처리량을 기반으로 훈련 시간을 추정할 수 있습니다. GPU 당 처리량이 



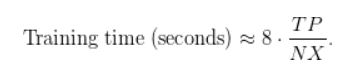
1조개의 매개변수 모델의 경우, 모델 훈련에 약 4,500억개의 토큰이 필요하다고 가정해봅시다. GPU 1개당 연산성능이 163테라플롭스인 A100 GPU를 3072개 사용하면 다음과 같은 훈련 시간이 필요합니다.
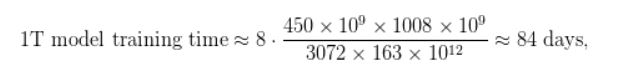
위와 같은 조건으로 걸리는 훈련시간은 84일로, 3개월이 채 되지 않습니다. 1,750억개의 매개변수를 둔 GPT-3 모델로는 1,024개의 A100 GPU를 사용해 훈련하면 한 달 남짓 걸리죠. 이러한 결과는 이 시스템으로는 이런 대형 모델을 현실적인 시간 내에 훈련하는 게 가능하다는 걸 보여줍니다. 더 자세한 내용은 다음 논문 “GPU 클러스터로 효율적인 대규모 언어 모델 훈련”을 참조하세요.
요약
본 글에서는 다양한 병렬처리 전략을 스마트하게 결합해, 최대 1조개의 매개변수로 자연어 처리(NLP) 모델을 더욱 빠르게 훈련시킬 수 있는 여러 기술을 설명했습니다.
- 노드간 텐서 모델 병렬처리
- 노드간 파이프라인 모델 병렬처리
- 데이터 병렬처리
앞으로도 파이프라이닝 스케줄(pipelining schedule)을 더욱 최적화할 계획입니다. 예를 들어, 텐서를 일찍 업스트림으로 전송하면 파이프라인 플러시 비용이 줄기 때문에 가중치 기울기(weight gradient)보다 데이터 기울기(data gradient)를 먼저 계산한다면, 처리량이 향상될 것으로 예상합니다. 그 외에도, 마이크로배치 크기, 글로벌 배치 크기, 처리량에 대한 활성화 재계산 정도와 같은 하이퍼파라미터 간의 관계를 다양하게 시도하며 최적의 조합을 탐색해보고 자합니다. 마지막으로, 모델을 컨버전스 하도록 훈련시킬 계획이며, 완화된 가중치 업데이트 시맨틱스(relaxed weight update semantics)가 있는 PipeDream-2BW처럼, 파이프라인 플러시가 없는 스케줄을 사용하는 것의 함의를 더 살펴볼 계획입니다.