AI 머신 러닝은 온라인의 제품 추천 시스템, 이미지 분류, 챗봇, 각종 예측, 제조 과정에서의 품질 검사 등 여러 분야에서 애플리케이션의 혁신을 주도하고 있습니다. AI는 크게 훈련(training)과 추론(inference)의 두 부분으로 구성됩니다.
추론은 AI의 프로덕션 단계에 해당합니다. 훈련을 마친 모델과 관련 코드는 데이터센터나 공용 클라우드, 또는 엣지단에 배포되어 예측 업무를 수행하죠. 추론 서빙(inference serving)이라 불리는 이 프로세스는 다음과 같은 이유로 복잡성을 띕니다.
- 다중의 모델 프레임워크: 데이터 사이언티스트와 연구자들은 모델의 구축에 TensorFlow, PyTorch, TensorRT, ONNX Runtime 등의 AI와 딥 러닝 프레임워크를 활용합니다. 또는 기본적인 형태의 Python만을 사용하는 경우도 있죠. 이러한 프레임워크 각각에는 프로덕션 환경에서 모델을 구동하게 해줄 실행용 백엔드가 필요합니다.
- 다양한 유형의 추론 쿼리: 추론 서빙(inference serving)에서는 실시간 온라인 예측, 오프라인 배치(batch), 스트리밍 데이터, 다중 모델의 복잡한 파이프라인 등 여러 유형의 추론 쿼리를 처리하게 됩니다. 이들 각각은 추론을 위한 특별한 프로세스를 요구합니다.
- 진화를 거듭하는 모델: 모델들은 새로운 데이터와 알고리즘을 바탕으로 재훈련과 업데이트를 거듭합니다. 따라서 프로덕션 환경에서의 모델은 서버 재시작이나 다운타임없이 지속적인 업데이트를 수행할 수 있어야 합니다. 하나의 애플리케이션이 다양한 모델을 사용하는 경우가 있기 때문에 스케일이 복합되기도 합니다.
- 다양한 CPU와 GPU: 모델들은 CPU 또는 GPU를 기반으로 실행될 수 있으며, CPU와 GPU에는 다양한 종류가 있습니다.
기업들은 각 모델과 프레임워크, 애플리케이션별로 서로 다른 다중의 추론 서빙(inference serving) 솔루션을 확보해 사용하곤 합니다.
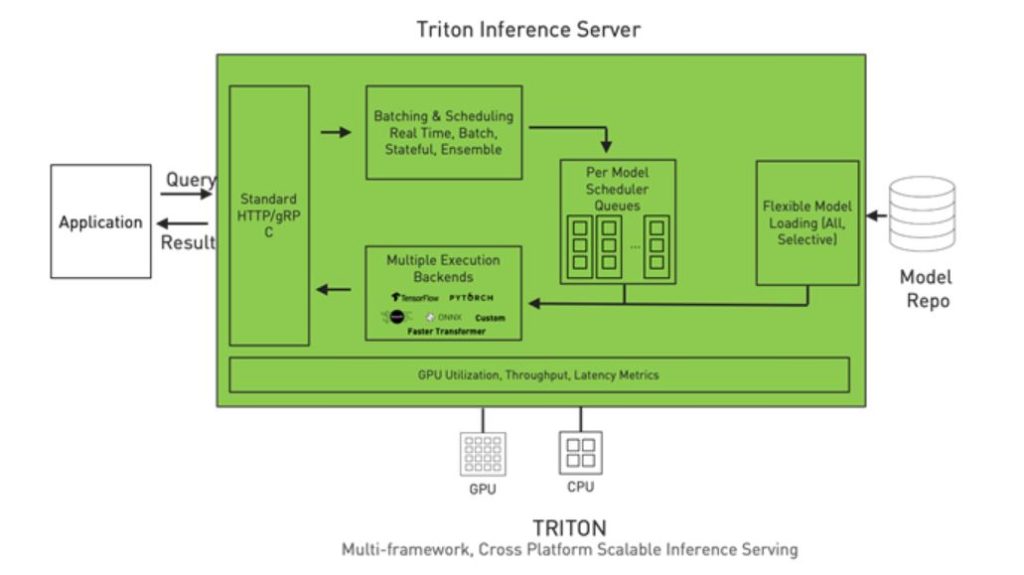
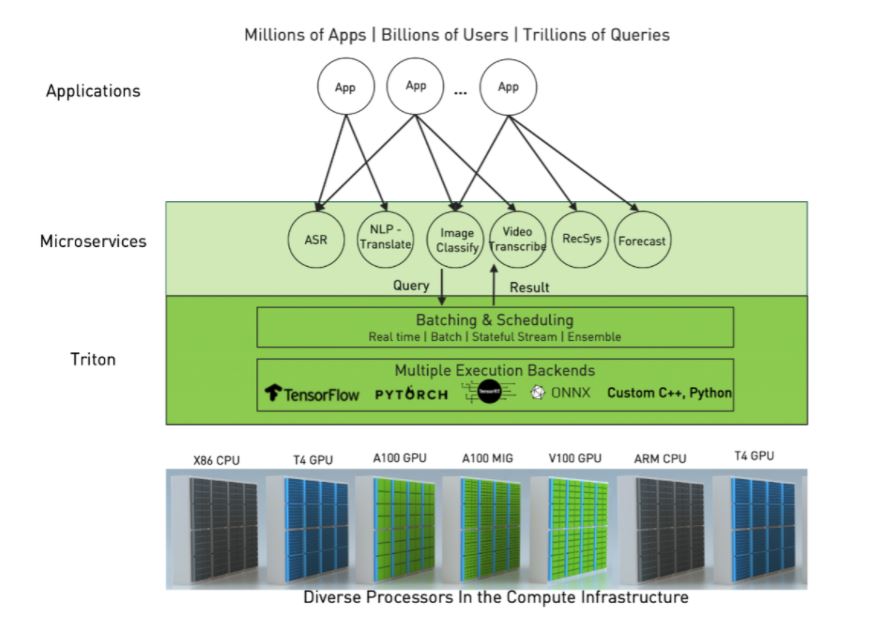
NVIDIA Triton Inference Server는 오픈 소스 소프트웨어로 위에서 언급한 복잡성 문제를 해결하여 기업의 추론 서빙(inference serving)을 간소화합니다. 단일화되고 표준화된 추론 플랫폼을 제공하여, CPU와 GPU상의 다중 프레임워크 모델과 데이터센터, 클라우드, 임베디드 디바이스, 가상 환경 등 다양한 배포 환경에서의 추론을 지원합니다.
Triton은 TensorFlow와 PyTorch, ONNX Runtime, Python 등 다중의 프레임워크 백엔드와 더불어 사용자 지정 백엔드까지도 네이티브로 지원합니다. 고급 배칭(batching)과 스케줄링 알고리즘으로 다양한 유형의 추론 쿼리를 지원하고, 실시간 모델 업데이트를 제공하며, CPU와 GPU 모두에서 모델을 구동합니다. Triton은 또한 모델의 동시 실행과 동적 배칭을 통한 하드웨어 활용 극대화로 추론 성능을 높이도록 고안됩니다. 동시 실행 기능은 특정 모델의 여러 복사본과 서로 다른 복수의 모델들을 동일한 GPU에서 병렬로 실행할 수 있게 해줍니다. 동적 배칭은 Triton이 서버 측에서의 추론 요청을 동적으로 그룹화하도록 하여 성능을 극대화합니다.
모델의 자동 변환과 배포
Triton Inference Server 2.9에는 프로덕션에서의 모델 배포 프로세스를 더욱 간소화하기 위한 기능들이 새롭게 추가됐습니다. 훈련을 마친 모델은 대개 프로덕션 배포를 위한 최적화가 되어 있지 않습니다. 그러므로 사용자가 구체적으로 목표하는 환경에 맞춰 변환과 최적화를 진행해야만 하죠. 다음의 프로세스는 단일 GPU상에서 Triton을 활용하여 TensorRT를 배포하는 과정을 보여줍니다. 이는 CPU 또는 GPU상에 배포되는 모든 추론 프레임워크에 적용됩니다.
- 서로 다른 프레임워크(TensorFlow, PyTorch)의 모델을 TensorRT로 변환하여 최상의 성능을 달성합니다.
- 정밀도 등의 최적화 여부를 확인합니다.
- 최적화된 모델을 생성합니다.
- 변환 후 모델의 정확도를 검증합니다.
- 서로 다른 모델 구성(model configuration)들을 수동으로 테스트하여 배치 사이즈, GPU당 동시 실행이 가능한 모델 인스턴스의 개수 등 성능을 극대화하는 구성을 찾습니다.
- Triton에 맞춰 모델 구성과 저장소를 준비합니다.
- (선택 사항) 쿠버네티스에 Triton을 배포하기 위한 헬름 차트(Helm chart)를 준비합니다.
앞서 살펴본 바와 같이 이 프로세스에는 상당한 시간과 노력이 소요됩니다.
Triton의 새로운 기능인 Model Navigator는 이 프로세스를 자동화합니다. 현재 제공 중인 알파 버전은 프레임워크의 종류(이번 릴리스에서는 TensorFlow와 PyTorch가 지원됩니다)와 상관없이 입력 모델을 TensorRT로 변환하고 그에 따른 정확도를 검증하며, 최적의 모델 구성을 자동으로 찾고 생성합니다. 또한 모델 배포를 위한 repo 구조도 생성합니다. 모델의 유형에 따라 때로는 수일이 걸리기도 하는 작업을 이제 단 몇 시간이면 완료할 수 있습니다.
모델 성능의 최적화
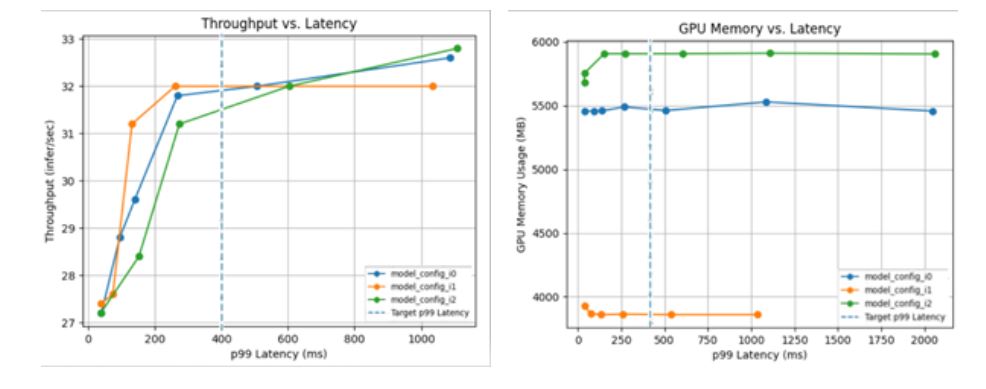
효율적인 추론 서빙(inference serving)을 위해서는 배치 사이즈와 동시 실행 모델의 개수 등 최적의 모델 구성을 파악해야 합니다. 처리량, 지연 시간, 메모리 활용 요구 사항을 감안하여 최적의 구성을 찾으려면 서로 다른 조합들을 수동으로 확인해야 하죠.
Triton Model Analyzer는 이 선택을 자동화하는 최적화 툴입니다. 모델이 최고의 성능을 달성할 수 있는 최선의 구성을 자동으로 찾아주죠. 지연 시간 제한, 목표 처리량, 메모리 풋프린트(memory footprint)와 같은 성능 요구 사항의 지정이 가능합니다. Triton Model Analyzer는 다양한 모델 구성을 검색하여 사용자의 제약 조건 하에서 최상의 성능을 구현하는 구성을 찾습니다. 상위권에 속하는 모델 구성들의 성능을 시각적으로 보여줄 수 있도록 차트가 포함된 요약 보고서를 제공합니다(Figure 2).
모델의 최적화에 도달하는 과정이 복잡하다는 이유로 최적화 측면에서 뒤쳐지는 추론 서비스에 안주할 필요가 없습니다. Triton을 활용해 가장 효율적인 추론에 손쉽게 도달할 수 있습니다.
Triton과 거대 모델의 추론
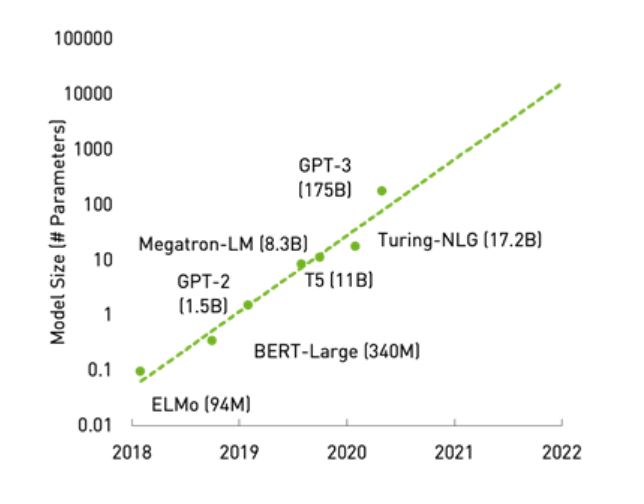
모델들은 특히 자연어 처리 분야에서 급격한 성장을 거듭하고 있습니다. 예를 들어 GPT-3 모델의 경우 어느 정도의 능력까지 발휘할 수 있는지에 대한 탐구가 여전히 계속되고 있습니다. 지금까지 밝혀진 바에 따르면 텍스트의 독해와 요약, Q&A, 인간과 유사한 챗봇, 소프트웨어 코드 생성 등의 유스 케이스(use case)에 효과적입니다.
이번 포스팅에서는 언어 모델들을 깊이 들여다보는 대신 이러한 거대 모델들의 비용 효율적 추론에 대해 살펴보겠습니다. GPU가 이 워크로드에 적합한 컴퓨팅 리소스인 것은 당연한 얘기지만, 모델이 너무 거대한 경우 단일 GPU에 맞지 않기도 합니다. 다중 GPU, 다중 노드 시스템 상에서 거대 모델을 훈련하는 프레임워크와 관련한 더 자세한 정보는 ‘자연어 처리 혁신 모델훈련 프레임워크 NVIDIA Megatron 완전 해부’ 블로그에서 확인하세요.
추론 작업을 위해서는 모델을 보다 작은 다수의 파일로 분할한 다음 각 파일을 별도의 GPU에 로드해야 합니다. 모델의 분할에는 일반적으로 두 가지 접근법이 사용됩니다.
- 파이프라인 병렬화는 레이어(layer) 경계에 모델을 수직으로 나누고 파이프라인의 다중 GPU에서 이 레이어들을 실행합니다.
- 텐서(Tensor) 병렬화는 모델을 수평으로 자르고, GPU 전반에 개별 레이어를 분할합니다.
Triton의 사용자 지정 백엔드 기능을 활용해 다중 GPU, 다중 노드 백엔드를 실행할 수 있습니다. 또한 Triton은 파이프라인 병렬화에 사용이 가능한 모델 앙상블 기능을 가지고 있습니다.
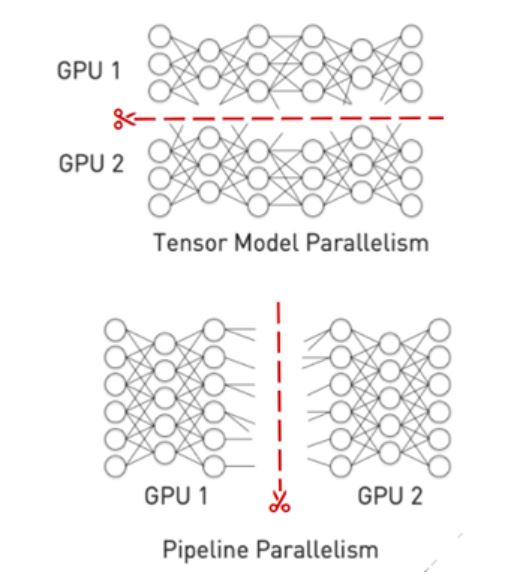
거대 모델들은 아직 개발의 초기 단계에 있습니다. 그러나 오래지 않아 다중의 거대 모델을 사용하는 프로덕션 AI가 다양한 사례에 활용되는 날이 올 것입니다.
생태계의 통합
추론 서빙(inference serving)은 프로덕션 활동에 해당하며 여러 생태계의 소프트웨어나 툴과 통합이 필요할 수 있습니다. 정기적으로 생태계를 추가하며 통합을 지원하는 Triton은 이제 다음과도 원활히 통합됩니다.
- 프레임워크 백엔드: Triton은 TensorFlow와 PyTorch, ONNX RT 등 즉각적인 편의성을 보장하는 주요 딥 러닝 프레임워크의 실행용 백엔드 일체를 지원합니다. C++와 Python의 사용자 지정 백엔드 또한 원활히 통합될 수 있도록 해줍니다. 21.03 릴리스의 일환으로 Triton에서 OpenVINO 백엔드의 베타 버전을 사용할 수 있게 되어 인텔 플랫폼 상에서의 고성능 CPU 추론이 가능해졌습니다.
- 쿠버네티스 생태계:Triton의 디자인은 확장성을 보장합니다. Triton은 마이크로소프트 AKS, 아마존 EKS, 구글 GKE 등 클라우드 상의 주요 쿠버네티스 플랫폼과 더불어 Red Hat OpenShift를 비롯한 온프레미스 환경과도 통합됩니다. Triton은 Kubeflow 프로젝트에도 포함되어 있습니다.
- 클라우드 AI 플랫폼과 MLOPs 소프트웨어: MLOps는 AI의 개발과 배포 워크플로우에 자동화와 거버넌스를 구현하는 프로세스입니다. Triton은 Azure ML 등의 클라우드 AI 플랫폼에 통합되어 있으며, Google CAIP와 Amazon SageMaker에 커스텀 컨테이너로 배포가 가능합니다. KFServing, Seldon Core, Allegro ClearML과도 통합됩니다.
고객 활용 사례 연구
Triton은 컴퓨터 비전, 자연어 처리, 금융 서비스 등을 위한 애플리케이션 일체의 프로덕션에서 대⋅소규모 고객사가 모두 사용할 수 있는 모델들을 제공합니다. 다양한 유스 케이스의 몇 가지 사례를 소개합니다.
컴퓨터 비전
- 미국 우체국(USPS): USPS 유통 센터 192곳의 배달물을 분석하는 마이크로서비스 아키텍처에 Triton을 활용합니다. 다중의 이미지 모델이 Triton으로 연간 수십억 개의 배달물을 처리합니다. 더 자세한 내용은 GTC 21의 Deploying State-of-the-Art Machine Learning Algorithms at Scale to the Edge: A Case Study(발표: Accenture Federal Services) 세션을 확인하세요.
- 폭스바겐 스마트 랩(Volkswagen Smart Lab): 폭스바겐 컴퓨터 비전 워크벤치(Volkswagen Computer Vision Workbench)에 Triton을 통합하여 사용자는 자신이 구축한 모델의 기반 프레임워크(ONNX나 PyTorch, 또는 TensorFlow)에 구애받지 않고 해당 모델을 Model Zoo에 제출할 수 있습니다. 폭스바겐 그룹의 파비앙 보만(Fabian Bormann) AI 엔지니어는 GTC 21의 Taming the Computer Vision Zoo with NVIDIA Triton for an easy scalable eco system 세션에서 Triton이 구현하는 모델 관리와 배포의 간소화야말로 새롭고 흥미로운 환경의 AI 모델을 제공하는 자사 업무의 핵심이라고 밝힌 바 있습니다.
자연어 처리
- 세일즈포스(Salesforce): 최첨단 트랜스포머 모델 개발에 Triton을 사용합니다. 더 자세한 정보는 GTC 21의 Benchmarking Triton Inference Server 세션을 확인하세요.
- 라이브퍼슨(LivePerson): 챗봇 애플리케이션을 위한 표준화 플랫폼으로 Triton을 사용하여 CPU 기반의 다양한 프레임워크에서 구축된 자연어 처리 모델을 지원합니다.
금융 서비스
- 인텔리전트 보이스(Intelligent Voice): Triton을 사용하여 감정 분석과 금융 사기 방지를 위한 음성과 언어 모델을 배포합니다. 더 자세한 내용은 GTC 21의 Detecting Deception and Tackling Insurance Fraud with GPU-Powered Conversational AI(발표: Intelligent Voice) 세션을 확인하세요.
- 앤트 그룹(Ant Group): Triton을 표준화 플랫폼으로 사용하여 AntChain, 저작권 관리 플랫폼, 금융 사기 방지 등의 다양한 애플리케이션을 위한 모델을 제공합니다.
프로덕션 배포에 Triton을 사용하는 고객사와 관련한 보다 자세한 내용은 다음주 블로그에 올라갈 NVIDIA Triton Tames the Seas of AI Inference를 참고하세요.
결론
NVIDIA Triton은 데이터센터와 클라우드, 임베디드 디바이스 일체에 표준화되고 확장 가능한 프로덕션 AI를 제공합니다. 다중의 프레임워크를 지원하고, CPU와 GPU 모두에서 모델을 실행하며, 다양한 유형의 추론 쿼리를 처리하고, 쿠버네티스, MLOPs 플랫폼과 통합됩니다.
지금 NGC에서 Triton을 Docker 컨테이너로 다운로드하고, GitHub repo의 triton-inference-server에 포함되어 있는 documentation을 확인하세요. 더 자세한 정보는 NVIDIA Triton Inference Server의 제품 페이지를 참고하세요.