AI는 초인적인 수준으로 듣고 보고 이해하고 분석하여 현명한 결정을 내리는 머신들로 4차 산업혁명을 견인하고 있습니다. 하지만 AI의 유효성은 결국 기본 모델의 품질이 좌우하죠. 그러므로 다양한 파라미터를 가진 모델을 신속하게 구축하고, 사용자의 솔루션에 가장 효과적인 모델을 규명하는 작업은 학술적 연구와 데이터 사이언스 모두에서 매우 중요합니다.
이번 포스팅에서는 NVIDIA GPU 기반 아마존 웹 서비스(AWS) 인스턴스에서 파이토치 라이트닝(PyTorch Lightning)으로 음성 모델을 구축하는 방법을 소개하겠습니다.
파이토치 라이트닝 + 그리드.ai: 규모별 모델의 신속한 구축
파이토치 라이트닝은 고성능 AI 연구를 위한 경량 파이토치 래퍼(wrapper)입니다. 라이트닝으로 파이토치 코드를 조직하면 다중의 GPU와 TPU, CPU에서 원활한 훈련이 가능합니다 또한 체크포인팅(checkpointing)과 로깅(logging), 샤딩(sharding), 혼합 정밀도(mixed precision) 등 우수하지만 구현이 어려운 기법도 활용할 수 있게 됩니다. NGC 카탈로그에서 파이토치 라이트닝 컨테이너와 개발자 환경을 사용할 수 있습니다.
그리드(Grid)는 코드를 따로 수정할 필요 없이 사용자의 랩톱에서 클라우드로 훈련을 스케일링(scaling)하게 해줍니다. AWS 등의 클라우드 서비스에서 실행되며 라이트닝뿐 아니라 사이 키트(Sci Kit), 텐서플로(TensorFlow), 케라스(Keras), 파이토치 같은 기존의 머신 러닝 프레임워크 일체를 지원합니다. 그리드를 사용해 NGC 카탈로그 모델의 훈련을 스케일링할 수 있습니다.
NGC: GPU 최적화 AI 소프트웨어를 위한 허브
NGC 카탈로그는 AI/머신 러닝 컨테이너와 사전 훈련된 모델을 비롯해 온프레미스, 클라우드, 엣지, 하이브리드 환경 전반에 간편히 배포되는 SDK 등 GPU 최적화 소프트웨어를 위한 허브입니다. 커스텀 데이터로 모델을 재훈련하게 지원하는 NVIDIA TAO Toolkit와 CPU, GPU 기반 시스템에서 예측을 수행하는 NVIDIA Triton Inference Server를 제공합니다.
지금부터는 NGC 카탈로그의 모델과 NVIDIA NeMo 프레임워크로 자동 음성 인식(ASR) 모델을 훈련하면서 파이토치 라이트닝을 활용하는 방법을 소개하겠습니다. 다음의 튜토리얼은 ASR with NeMo 튜토리얼에 기초합니다.
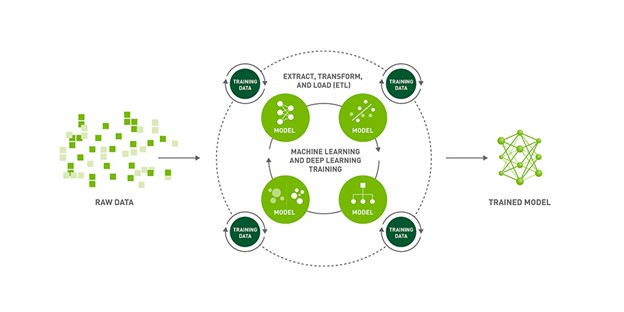
그리드 세션과 파이토치 라이트닝, NVIDIA NeMo로 NGC 모델 훈련하기
음성 언어를 텍스트로 변환하는 ASR은 음성 텍스트 변환(Speech to Text) 시스템의 핵심입니다. ASR 모델 훈련의 목표는 주어진 오디오 인풋에서 텍스트를 생성할 시, 전사된 음성의 단어 오류율(WER)을 최소화하는 것입니다. NGC 카탈로그에는 ASR용으로 사전 훈련된 최첨단 모델이 포함돼 있습니다.
이제부터 그리드 세션(Session)과 NVIDIA NeMo, 파이토치 라이트닝을 사용해 AN4 데이터세트에서 ASR 모델을 미세 조정하는 방법을 살펴보겠습니다.
일명 알파벳-숫자(Alphanumeric) 데이터세트로도 불리는 AN4 데이터세트는 카네기멜론대학(Carnegie Mellon University)이 수집, 발표했습니다. 개별 주소와 성명, 전화번호 등의 철자를 하나씩 풀어 말하는 인간 음성과 해당 내용의 전사로 구성돼 있죠.
Step 1: 파이토치 라이트닝과 사전 훈련 NGC 모델에 최적화된 그리드 세션 생성하기
그리드 세션은 스케일링이 필요한 하드웨어에서 곧바로 실행되는 한편 사전 설정된 환경을 제공해 머신 러닝 프로세스 연구 단계의 반복 작업을 가속합니다. 세션들은 깃허브(GitHub)에 링크되고 주피터허브(JupyterHub)로 로드됩니다. 또한 SSH와 사용자가 선택한 IDE를 통해 액세스되어 설정 작업을 따로 진행할 필요가 없습니다.
세션을 사용할 때 기본 운영에 필요한 컴퓨팅 비용만 지불한 다음, 그리드 런(run)을 통해 사용자의 작업을 클라우드로 스케일링합니다. 그리드 세션은 파이토치 라이트닝, 그리고 NGC 카탈로그에 호스팅된 모델에 최적화돼 있습니다. 전문적으로 거래가를 책정하는 서비스도 함께 제공됩니다.
자세한 설명은 그리드 세션 둘러보기(Grid.ai 계정 필요)를 참고하세요.

Step 2: ASR 데모 리포 복제하고 튜토리얼 노트북 열기
이로써 파이토치 라이트닝에 최적화된 개발자 환경이 구축됐습니다. 다음 단계는 NGC-Lightning-Grid-Workshop 리포(repo)를 복제하는 것입니다.
그리드 세션의 터미널에서 다음 명령을 사용하여 복제 작업을 직접 수행할 수 있습니다.
git clone https://github.com/aribornstein/NGC-Lightning-Grid-Workshop.git리포를 복제한 뒤 노트북을 열면 NeMo와 파이토치 라이트닝으로 NGC 모델을 미세 조정하는 작업에 사용할 수 있습니다.
Step 3: NeMo ASR 종속성 설치하기
먼저 세션 종속성(dependencies)을 모두 설치합니다. 파이토치 라이트닝과 NeMo 등의 툴을 실행하고, 이를 위해 AN4 데이터세트를 처리합니다. 튜토리얼 노트북의 첫 번째 셀을 실행하세요. 다음의 배시(bash) 명령이 실행되면서 종속성을 설치합니다.
## Install dependencies
!pip install wget
!sudo apt-get install sox libsndfile1 ffmpeg -y
!pip install unidecode
!pip install matplotlib>=3.3.2
## Install NeMo
BRANCH = 'main'
!python -m pip install --user git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all]
## Grab the config we'll use in this example
!mkdir configs
!wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/$BRANCH/examples/asr/conf/config.yamlStep 4: AN4 데이터세트의 변환과 시각화
AN4 데이터세트는 원시 Sof 오디오 파일로 제공되지만, 모델 대부분의 프로세스는 멜 스펙트로그램(mel spectrogram)으로 진행됩니다. NeMo 오디오 프로세싱을 사용할 수 있도록 원래의 Sof 파일을 Wav 형식으로 변환합니다.
import librosa
import IPython.display as ipd
import glob
import os
import subprocess
import tarfile
import wget
# Download the dataset. This will take a few moments...
print("******")
if not os.path.exists(data_dir + '/an4_sphere.tar.gz'):
an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz'
an4_path = wget.download(an4_url, data_dir)
print(f"Dataset downloaded at: {an4_path}")
else:
print("Tarfile already exists.")
an4_path = data_dir + '/an4_sphere.tar.gz'
if not os.path.exists(data_dir + '/an4/'):
# Untar and convert .sph to .wav (using sox)
tar = tarfile.open(an4_path)
tar.extractall(path=data_dir)
print("Converting .sph to .wav...")
sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True)
for sph_path in sph_list:
wav_path = sph_path[:-4] + '.wav'
cmd = ["sox", sph_path, wav_path]
subprocess.run(cmd)
print("Finished conversion.\n******")
# Load and listen to the audio file
example_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav'
audio, sample_rate = librosa.load(example_file)
ipd.Audio(example_file, rate=sample_rate)그런 다음 오디오 예제를 오디오 파형의 이미지로 시각화할 수 있습니다. Figure 3은 오디오 내 각 문자에 상응하는 파형의 움직임을 보여줍니다. 이 예제의 화자는 발음이 꽤 분명한 편입니다!
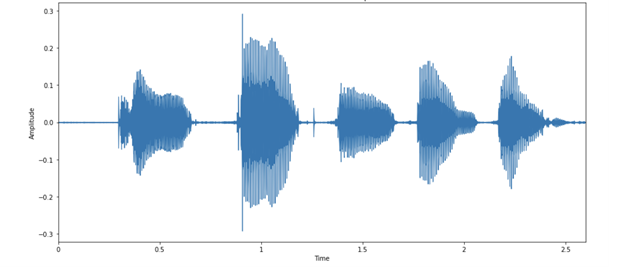
발화된 문자 각각은 서로 다른 “형태”를 가집니다. 여기서 흥미로운 점은 마지막 부분의 두 파형이 비교적 유사하다는 것입니다. 이는 충분히 예상이 가능한 일인데요. 둘 모두 알파벳 N에 해당하기 때문이죠.
스펙트로그램
오디오 모델링은 시간의 경과에 따른 음향 주파수라는 맥락으로 접근하면 한결 쉬워집니다. 이 경우 원래 시퀀스 값인 57,330보다 훌륭한 표현형을 얻을 수도 있습니다. 스펙트로그램은 오디오 내 다양한 주파수의 세기가 시간의 경과에 따라 달라지는 모습을 시각화하기에 좋은 방법입니다. 이를 위해 신호를 더 작게, 대개는 서로 중첩되는 형태의 조각으로 나눈 다음 각각에 국소 푸리에 변환(STFT)을 수행합니다.
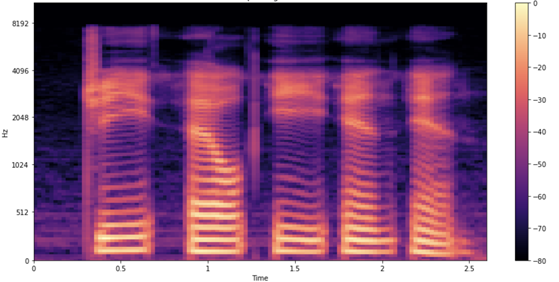
Figure 4는 해당 샘플의 스펙트로그램입니다.
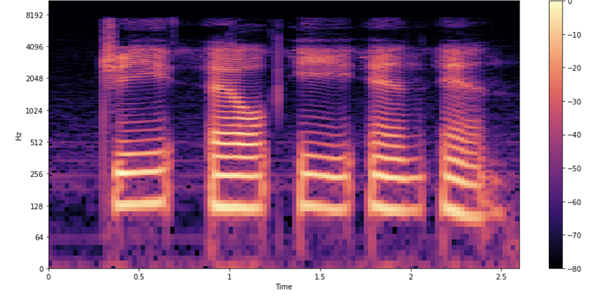
오디오 파형과 마찬가지로 스펙트로그램에서도 각 문자의 발음 상황이 확인됩니다. 이때 각 형태와 색깔은 무엇을 의미할까요? 오디오 파형도와 마찬가지로 x축(총 2.6초 분량의 오디오)은 시간의 경과를 뜻합니다. 그러나 y축의 경우 주파수 변화를 의미하죠(로그 스케일 적용). 색깔은 특정 시점에서 특정 주파수의 세기를 나타냅니다.
멜 스펙트로그램
아직 끝이 아닙니다. 멜 스펙트로그램으로 데이터를 시각화하면 보다 훌륭한 결과를 얻을 수 있습니다. 주파수의 척도를 선형(또는 로그)에서 멜 척도로 변경하는 것인데요. 멜 척도는 인간의 청각이 인식 가능한 음조를 더 훌륭히 표현합니다. 직관적으로 보더라도 멜 스펙트로그램은 ASR에 유용합니다. 인간의 음성을 처리하고 전사하는 과정에서 모델에 영향을 미칠 수 있는 배경 잡음을 멜 스펙트로그램이 줄여주기 때문입니다.
Step 5: NGC가 제공하는 사전 훈련 쿼츠넷 모델의 로드와 추론
이제 AN4 데이터세트의 로드와 이해를 마쳤으므로 NGC를 사용해 ASR 모델을 로드하고 파이토치 라이트닝으로 미세 조정하는 방법을 살펴보겠습니다. NeMo ASR 컬렉션의 경우, 다양한 빌딩 블록을 비롯해 훈련과 평가에 사용 가능한 완성형 모델이 함께 제공됩니다. 모델에 따라서는 사전 훈련된 가중치(weights)가 포함되기도 합니다.
본 포스팅의 데이터 모델링에는 NGC Model Hub에서 쿼츠넷(QuartzNet)이라 불리는 재스퍼(Jasper) 아키텍처를 사용합니다. 재스퍼 아키텍처는 1차원 합성곱(convolution)을 써서 스펙트로그램 데이터를 모델링하는 반복적 블록 구조로 구성됩니다(Figure 6).
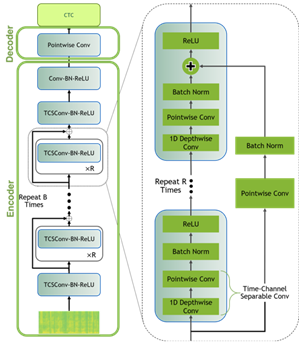
쿼츠넷은 시간-채널 분리형 1차원 합성곱을 사용한다는 점에서 재스퍼보다 우수합니다. 이를 통해 유사한 정확도를 유지하면서 가중치의 수를 크게 줄일 수 있습니다.
다음의 명령은 사전 훈련된 쿼츠넷15×5 모델을 NGC 카탈로그에서 다운로드하고 인스턴스화합니다.
tgmuartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="QuartzNet15x5Base-En")Step 6: 파이토치 라이트닝으로 모델 미세 조정하기
모델이 확보되면 다음의 과정에 따라 파이토치 라이트닝으로 미세 조정을 진행할 수 있습니다.
import pytorch_lightning as pl
from omegaconf import DictConfig
trainer = pl.Trainer(gpus=1, max_epochs=10)
params['model']['train_ds']['manifest_filepath'] = train_manifest
params['model']['validation_ds']['manifest_filepath'] = test_manifest
first_asr_model = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer)
# Start training!!!
trainer.fit(first_asr_model)이 라이트닝 트레일러(Lightning Trainer)는 모델의 체크포인팅과 로깅을 기본으로 사용하는 등의 이점을 제공합니다. 또한 모델의 코드를 수정하지 않고도 50가지 이상의 우수 기법들을 활용할 수 있죠. 여기에는 다중 GPU 훈련, 모델 샤딩, 딥 스피드(deep speed), 양자화 인식 훈련(quantization-aware training), 조기 종료, 혼합 정밀도, 그래디언트 클리핑(gradient clipping), 프로파일링 등이 포함됩니다.

Step 7: 추론과 배포
이제 기본 모델이 확보됐으므로 추론을 실행합니다.
Step 8: 세션 일시 중지
모델의 훈련이 완료됐다면, 세션을 일시 중지하더라도 필요한 파일 일체가 유지됩니다.
일시 중지된 세션에는 요금이 부과되지 않으며, 필요한 경우 다시 시작할 수 있습니다.
결론
지금까지 파이토치 라이트닝과 NGC, 그리드를 자세히 탐구하는 시간을 가졌습니다. NGC NeMo 모델을 미세 조정하고 그리드 런으로 최적화하는 방법을 살펴봤는데요. 그리드와 NGC를 활용한 여러분의 다음 도전이 무척 기대됩니다.