
생성형 AI는 퍼스널 컴퓨팅 역사상 가장 중요한 트렌드 중 하나로, 게임, 창의성, 비디오, 생산성, 개발 등에 발전을 가져다줍니다.
그리고 Tensor Core라는 전용 AI 프로세서가 탑재된 GeForce RTX 및 NVIDIA RTX GPU는 1억 대 이상의 Windows PC 및 워크스테이션에 기본적으로 생성형 AI의 성능을 제공하고 있습니다.
오늘날 PC의 생성형 AI는 라마 2(Llama 2) 및 코드 라마(Code Llama)와 같은 최신 AI 대규모 언어 모델의 추론 성능을 가속화하는 오픈 소스 라이브러리인 Windows용 TensorRT-LLM을 통해 최대 4배까지 빨라지고 있습니다. 이는 지난 달 데이터센터용 TensorRT-LLM 발표에 이은 것입니다.
또한, 엔비디아는 개발자가 거대언어모델(LLM)을 가속화하는 데 도움이 되는 도구도 출시했는데, 여기에는 TensorRT-LLM으로 커스텀 모델을 최적화하는 스크립트, TensorRT에 최적화된 오픈 소스 모델, LLM 응답의 속도와 품질을 모두 보여주는 개발자 레퍼런스 프로젝트 등이 포함됩니다.
이제 널리 사용되는 웹 UI에서 안정적인 확산을 위해 TensorRT 가속을 Automatic1111 배포를 통해 사용할 수 있습니다. 이전 가장 빠른 구현보다 생성형 AI 확산 모델의 속도가 최대 2배까지 빨라집니다.
또한 RTX 비디오 슈퍼 해상도(VSR) 버전 1.5는 오늘 Game Ready 드라이버 릴리스의 일부로 제공되며, 다음 달 초에 출시될 다음 NVIDIA Studio 드라이버에서 사용할 수 있습니다.
TensorRT를 통한 LLM 개발 가속화
LLM은 채팅 참여, 문서 및 웹 콘텐츠 요약, 이메일 및 블로그 초안 작성 등 생산성을 높이고 있으며, 데이터를 자동으로 분석하고 방대한 콘텐츠를 생성할 수 있는 AI 및 기타 소프트웨어의 새로운 파이프라인의 핵심을 이루고 있습니다.
LLM 추론 가속화를 위한 라이브러리인 TensorRT-LLM은 이제 개발자와 최종 사용자에게 RTX 기반 Windows PC에서 최대 4배 더 빠르게 작동할 수 있는 LLM의 이점을 제공합니다.
배치 크기가 클수록 이러한 가속화는 한 번에 여러 개의 고유한 자동 완성 결과를 출력하는 작성 및 코딩 어시스턴트와 같이 보다 정교한 LLM 사용 환경을 크게 개선합니다. 그 결과 성능이 가속화되고 품질이 향상되어 사용자가 가장 좋은 것을 선택할 수 있습니다.
TensorRT-LLM 가속화는 LLM을 벡터 라이브러리 또는 벡터 데이터베이스와 결합하는 검색 증강 생성(RAG)과 같이 LLM 기능을 다른 기술과 통합할 때에도 유용합니다. RAG를 사용하면 LLM이 사용자 이메일이나 웹사이트의 기사 등 특정 데이터 집합을 기반으로 응답을 제공하여 보다 타겟팅된 답변을 제공할 수 있습니다.
이를 실제로 보여주기 위해 LLaMa 2 기본 모델에 “NVIDIA ACE는 감정적인 반응을 어떻게 생성하나요?”라는 질문을 던졌을 때 도움이 되지 않는 답변을 반환했습니다.
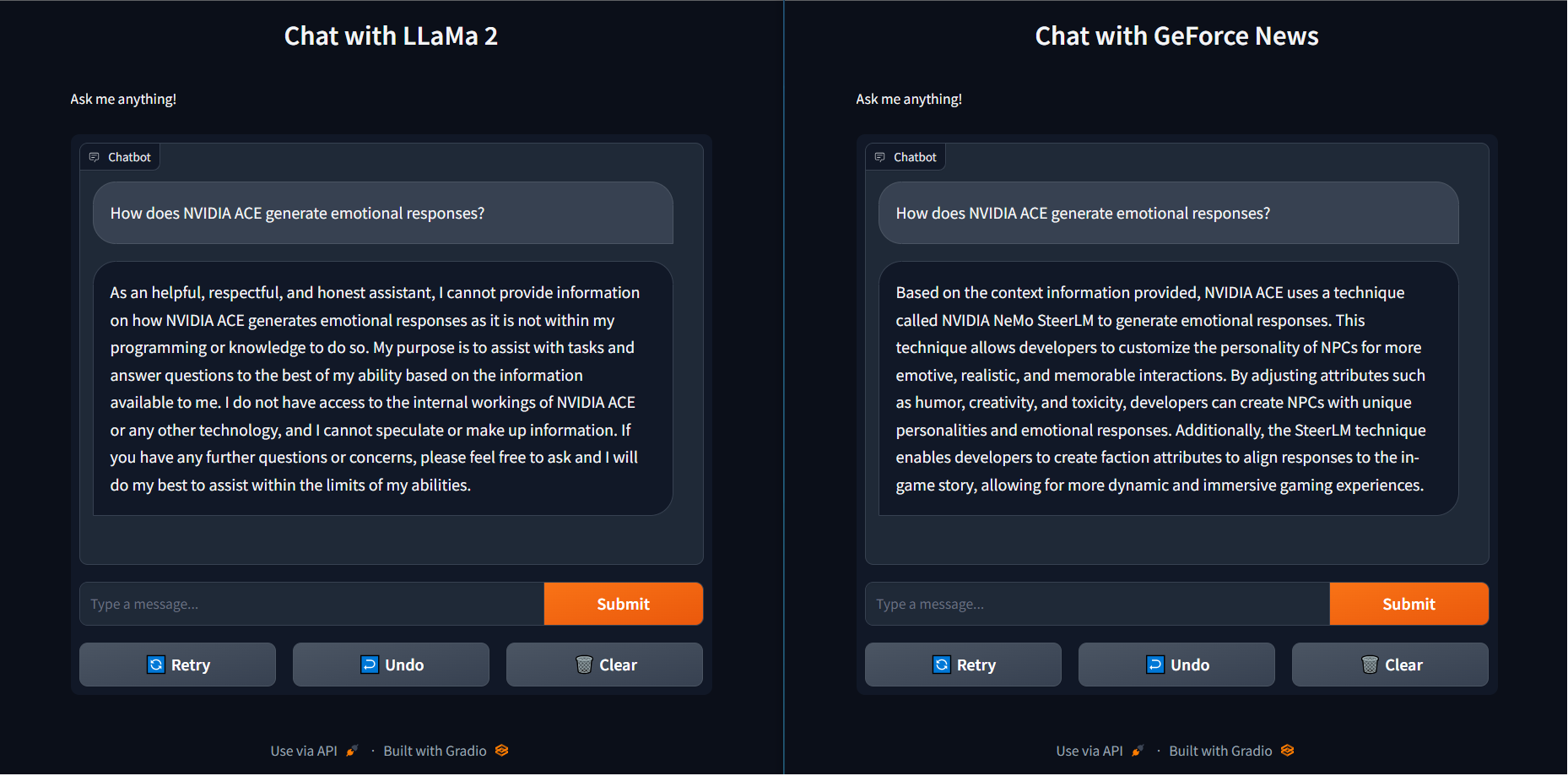
반대로, 벡터 라이브러리에 최신 GeForce 뉴스 기사를 로드하고 동일한 라마 2 모델에 연결하여 RAG를 사용하면 NeMo SteerLM을 사용하여 정답을 반환할 뿐만 아니라 TensorRT-LLM 가속화를 통해 훨씬 더 빠르게 응답을 반환할 수 있었습니다. 이러한 속도와 숙련도의 조합은 사용자에게 더 스마트한 솔루션을 제공합니다.
TensorRT-LLM은 곧 NVIDIA 개발자 웹사이트에서 다운로드할 수 있습니다. TensorRT에 최적화된 오픈 소스 모델과 샘플 프로젝트인 GeForce 뉴스가 포함된 RAG 데모는 ngc.nvidia.com 및 GitHub.com/NVIDIA에서 확인할 수 있습니다.
가속 자동화
스테이블 디퓨전과 같은 디퓨전 모델은 놀랍고 새로운 예술 작품을 상상하고 제작하는 데 사용됩니다. 이미지 생성은 완벽한 결과물을 얻기 위해 수백 번의 반복적인 과정을 거치는 과정입니다. 저성능 컴퓨터에서 이 반복 작업을 수행하면 대기 시간이 몇 시간까지 늘어날 수 있습니다.
TensorRT는 레이어 퓨전, 정밀 보정, 커널 자동 튜닝 및 추론 효율성과 속도를 크게 향상시키는 기타 기능을 통해 AI 모델을 가속화하도록 설계되었습니다. 따라서 실시간 애플리케이션과 리소스 집약적인 작업에 없어서는 안 될 필수 요소입니다.
그리고 이제 TensorRT는 안정적 확산 속도를 두 배로 높였습니다.
가장 널리 사용되는 배포판인 Automatic1111의 WebUI와 호환되는 TensorRT 가속을 통한 Stable Diffusion은 사용자가 더 빠르게 반복하고 컴퓨터에서 대기하는 시간을 줄여 최종 이미지를 더 빨리 전달할 수 있도록 도와줍니다. GeForce RTX 4090에서는 Apple M2 Ultra가 탑재된 Mac의 최고 구현보다 7배 빠르게 실행됩니다. 확장 프로그램은 오늘 다운로드할 수 있습니다.
안정적 확산 파이프라인의 TensorRT 데모는 개발자에게 확산 모델을 준비하고 TensorRT를 사용하여 가속화하는 방법에 대한 참조 구현을 제공합니다. 확산 파이프라인을 터보차징하고 애플리케이션에 초고속 추론을 적용하는 데 관심이 있는 개발자를 위한 출발점입니다.
최고의 비디오
AI는 모든 사용자의 일상적인 PC 환경을 개선하고 있습니다. YouTube, Twitch, Prime Video, Disney+ 등 거의 모든 소스의 비디오 스트리밍은 PC에서 가장 인기 있는 활동 중 하나입니다. AI와 RTX 덕분에 이미지 품질이 또 한 번 업그레이드되었습니다.
RTX VSR은 비디오 압축으로 인한 아티팩트를 줄이거나 제거하여 스트리밍된 비디오 콘텐츠의 품질을 개선하는 획기적인 AI 픽셀 처리 기술입니다. 또한 가장자리와 디테일을 선명하게 처리합니다.
현재 사용 가능한 RTX VSR 버전 1.5는 업데이트된 모델을 통해 시각적 품질을 더욱 개선하고, 기본 해상도로 재생되는 콘텐츠의 아티팩트를 제거하며, 전문가용 RTX 및 GeForce RTX 20 시리즈 GPU 모두에 대한 NVIDIA Turing 아키텍처 기반의 RTX GPU 지원을 추가합니다.
VSR AI 모델을 재학습하여 미묘한 디테일과 압축 아티팩트 간의 차이를 정확하게 식별하는 방법을 학습했습니다. 그 결과, AI로 강화된 이미지는 업스케일링 과정에서 디테일을 더욱 정확하게 보존합니다. 미세한 디테일이 더 잘 보이고 전체적인 이미지가 더 선명하고 또렷하게 보입니다.

버전 1.5의 새로운 기능은 디스플레이의 기본 해상도로 재생되는 비디오의 아티팩트 제거 기능입니다. 기존 버전은 업스케일링된 비디오만 향상시켰습니다. 이제 예를 들어 1080p 해상도 디스플레이로 스트리밍되는 1080p 비디오는 무거운 아티팩트가 줄어들어 더 부드럽게 보입니다.

RTX VSR 1.5는 오늘 모든 RTX 사용자가 최신 Game Ready 드라이버에서 사용할 수 있습니다. 다음 달 초에 출시될 예정인 NVIDIA Studio 드라이버에서 사용할 수 있습니다.
RTX VSR은 위에서 언급한 소프트웨어, 도구, 라이브러리 및 SDK를 비롯하여 DLSS, Omniverse, AI 워크벤치 등 400개 이상의 AI 지원 앱과 게임을 소비자에게 제공하는 데 기여한 엔비디아 소프트웨어, 도구, 라이브러리 및 SDK 중 하나입니다.
AI 시대가 다가오고 있습니다. 그리고 RTX는 모든 단계에서 진화의 속도를 높이고 있습니다.