
편집자 노: 본 게시물은 ‘Think SMART’ 시리즈의 일부로, 선도적인 AI 서비스 제공업체, 개발자 및 기업이 NVIDIA의 풀스택 추론 플랫폼 최신 기술을 활용해 여 추론 성능과 투자 수익률을 높이는 방법에 초점을 맞추고 있습니다.
최근 세미애널리시스(SemiAnalysis)가 실시한 독립형 인퍼런스MAX(InferenceMAX) v1 벤치마크에서 실행된 테스트에 따르면, NVIDIA Blackwell은 모든 모델과 활용 사례 전반에 걸쳐 가장 높은 성능과 효율성, 그리고 가장 낮은 총소유비용(total cost of ownership, TCO)을 제공하고 있습니다.
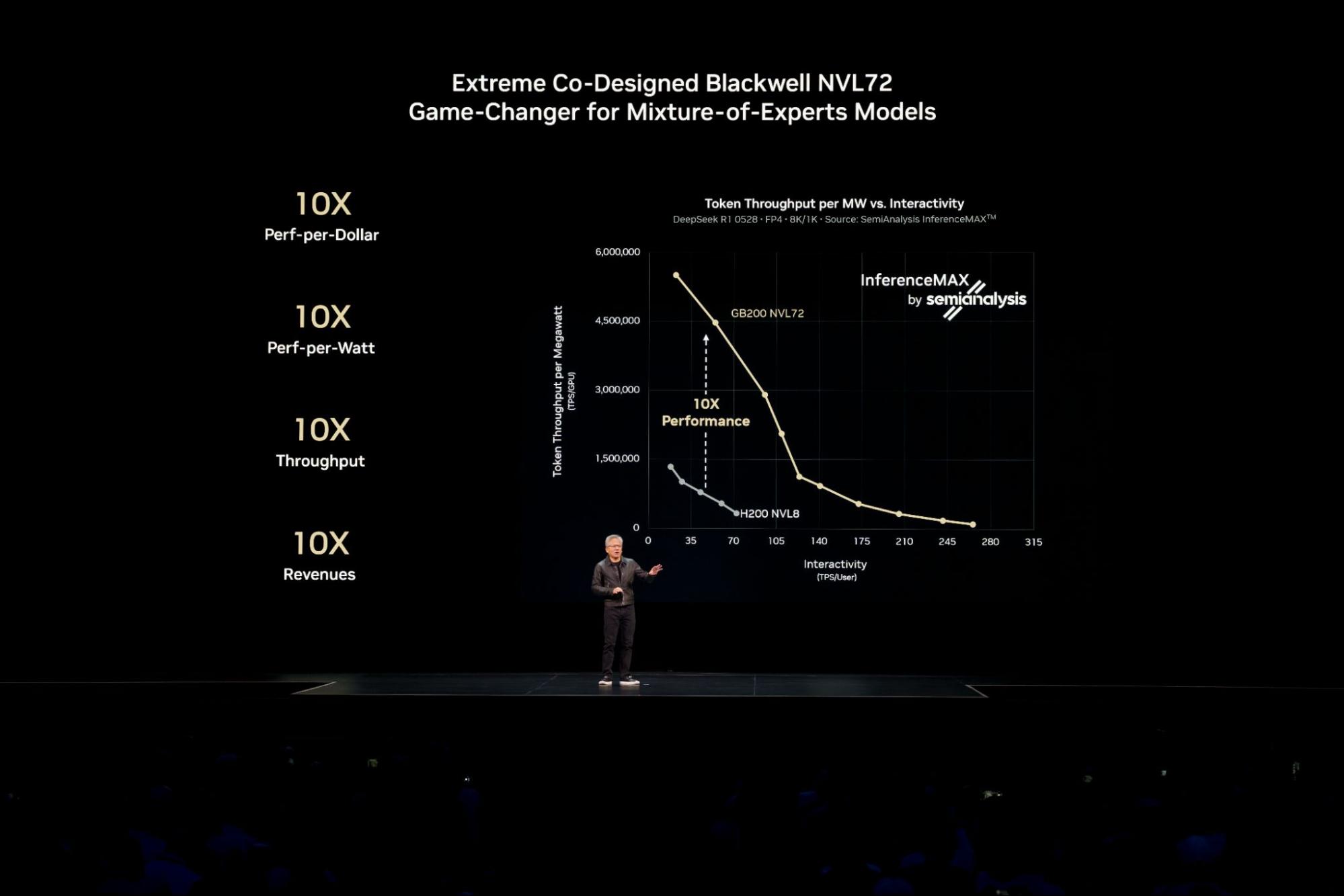
대규모 전문가 혼합 방식(mixture-of-experts, MoE) 모델과 같은 오늘날 가장 복잡한 AI 모델에서 이러한 업계 최고 수준의 성능을 달성하려면, 수백만 명의 동시 사용자에게 서비스를 지원하고 더 빠른 응답을 제공하기 위해 추론 작업을 여러 서버(노드)로 분산시켜야 하는데요.
NVIDIA Dynamo 소프트웨어 플랫폼은 이러한 강력한 멀티 노드 기능을 프로덕션 환경에서 지원해, 기업이 기존 클라우드 환경 전반에서도 동일한 벤치마크 최고 수준의 성능과 효율성을 달성할 수 있습니다.
최적화된 성능을 위한 분산 추론 활용
단일 GPU 또는 서버에 탑재 가능한 AI 모델의 경우, 개발자들은 높은 처리량을 제공하기 위해 여러 노드에 걸쳐 동일한 모델 복제본을 병렬로 실행하는 경우가 많습니다. 시그널65(Signal65) 수석 애널리스트인 Russ Fellows는 최근 발표한 논문에서 이 접근법이 72개의 NVIDIA Blackwell Ultra GPU를 활용해 110만 토큰 처리 속도(TPS)라는 업계 최초의 기록적인 처리량을 달성했다고 밝혔죠.
AI 모델을 확장해 다수의 동시 사용자를 실시간으로 지원하거나, 입력 시퀀스가 긴 고난도 워크로드를 처리할 때, 분산형 서빙(disaggregated serving) 기술을 활용하면 성능과 효율성을 더욱 향상시킬 수 있습니다.
AI 모델 서비스는 입력 프롬프트를 처리하는 프리필(prefill)과 출력을 생성하는 디코드(decode) 두 단계로 구성됩니다. 기존 방식에서는 두 단계 모두 동일한 GPU에서 실행됐는데, 이로 인해 비효율성과 리소스 병목 현상을 유발할 수 있었는데요.
분산형 서빙은 이러한 문제를 각각 독립적으로 최적화된 GPU로 작업을 지능적으로 분산함으로써 해결합니다. 이를 통해 워크로드의 각 부분이 해당 작업에 가장 적합한 최적화 기법을 활용해 실행되도록 보장해 전체 성능을 극대화하죠. 딥시크-R1(DeepSeek-R1)과 같은 최신 대규모 AI 추론과 MoE 모델에서는 분산 서비스가 필수입니다.
NVIDIA Dynamo는 이러한 분산형 서빙 기능을 GPU 클러스터 전반에서 프로덕션 규모로 손쉽게 구현할 수 있도록 합니다.
이미 그 가치가 입증되고 있습니다.
예를 들어, 베이스텐(Baseten)은 NVIDIA Dynamo를 활용해 장문 코드 생성을 위한 추론 서비스 속도를 2배 가속화하고 처리량을 1.6배 증가시켰는데요. 바로 추가 하드웨어 비용 없이 이뤄졌죠. 이러한 소프트웨어 기반의 성능 향상은 AI 제공업체가 인텔리전스를 생산하는 비용을 크게 절감할 수 있도록 합니다.
클라우드 환경에서 분산 추론 확장하기
대규모 AI 훈련에서 그랬던 것처럼, 컨테이너화된 애플리케이션 관리의 업계 표준인 쿠버네티스(Kubernetes)는 엔터프라이즈 규모의 AI 배포를 위해 수십 개 또는 수백 개의 노드에 걸쳐 분산형 서빙을 확장하는 데 최적화돼 있습니다.
현재 NVIDIA Dynamo가 주요 클라우드 제공업체의 관리형 쿠버네티스 서비스에 통합됨에 따라, 고객은 GB200, GB300 NVL72를 포함한 NVIDIA Blackwell 시스템 전반에서 멀티 노드 추론을 확장할 수 있는데요. 엔터프라이즈 AI 배포에 요구되는 성능, 유연성, 안정성을 제공합니다.
- 아마존웹서비스(Amazon Web Services, AWS): NVIDIA Dynamo와 아마존 EKS를 통합해 고객의 생성형 AI 추론을 가속화합니다.
- 구글 클라우드(Google Cloud): AI 하이퍼컴퓨터(Hypercomputer)에서 엔터프라이즈 규모의 거대 언어 모델(LLM) 추론을 최적화하기 위해 Dynamo 레시피를 제공합니다.
- 마이크로소프트 애저(Microsoft Azure): 애저 쿠버네티스 서비스에서 NVIDIA Dynamo와 ND GB200-v6 GPU를 활용한 멀티 노드 LLM 추론을 지원합니다.
- 오라클 클라우드 인프라스트럭처(Oracle Cloud Infrastructure, OCI): OCI 슈퍼클러스터(OCI Superclusters)와 NVIDIA Dynamo를 활용한 멀티 노드 LLM 추론을 지원합니다.
대규모 멀티 노드 추론을 실현하려는 움직임은 하이퍼스케일러(hyperscalers)를 넘어 확장되고 있습니다.
예를 들어, 네비우스(Nebius)는 NVIDIA 가속 컴퓨팅 인프라를 기반으로 대규모 추론 워크로드를 처리할 수 있는 클라우드를 설계하고 있으며, NVIDIA Dynamo와 생태계 파트너로서 협력하고 있죠.
NVIDIA Dynamo의 NVIDIA Grove로 쿠버네티스 추론 간소화
분산형 AI 추론은 프리필, 디코드, 라우팅(routing) 등 서로 다른 요구사항을 가진 특수 구성 요소들을 조율해야 하는데요. 쿠버네티스가 직면한 과제는 더 많은 모델 복제본을 병렬로 실행하는 것이 아니라, 이 다양한 구성 요소들을 하나의 통합된 고성능 시스템으로 능숙하게 운영하는 것입니다.
NVIDIA Grove는 NVIDIA Dynamo에서 사용 가능한 API(application programming interface)로, 사용자에게 전체 추론 시스템을 설명하는 단일 고수준 사양을 제공합니다.
예를 들어, 사용자는 단일 사양 안에서 “프리필에는 GPU 노드 3개, 디코드에는 GPU 노드 6개가 필요하며, 가능한 가장 빠른 응답을 위해 단일 모델 복제본의 모든 노드가 동일한 고속 인터커넥트에 배치돼야 한다”고 간단히 요구할 수 있죠.
해당 사양을 기반으로 그로브는 모든 복잡한 조율 작업을 자동으로 처리합니다. 이때, 관련 구성 요소를 정확한 비율과 종속성을 유지한 채 함께 확장하고, 올바른 순서로 실행하며, 빠르고 효율적인 통신을 위해 클러스터 전반에 전략적으로 배치합니다.
AI 추론이 점점 더 분산됨에 따라, 쿠버네티스, NVIDIA Dynamo, NVIDIA Grove의 조합은 개발자가 지능형 애플리케이션을 구축하고 확장하는 방식을 간소화합니다.
NVIDIA의 대규모 AI 시뮬레이션(AI-at-scale simulation)을 통해 하드웨어와 배포 방식 선택이 성능, 효율성, 사용자 경험에 미치는 영향을 확인할 수 있습니다. 테크니컬 블로그에서 분산형 서빙에 대한 자세한 내용과 Dynamo, NVIDIA GB200 NVL72 시스템이 어떻게 협력해 추론 성능을 향상시키는지 알아보세요.
NVIDIA Think SMART 뉴스레터를 구독하고, 월간 소식을 확인해 보세요.