
코로나 팬데믹으로 인해 한 차례 연기되었던 ‘KISTI-NVIDIA GPU 해커톤’이 이번에는 온라인으로 개최됐습니다. AI 연구나 HPC 코드를 가속화할 수 있는 가능성을 높이기 위한 목적으로 진행된 이번 해커톤에서는 6개의 참가팀과 함께 KISTI, NVIDIA 및 OpenACC의 국내·외 전문가 멘토들이 NVIDIA GPU 병렬 컴퓨팅 기술을 통해 연구 문제를 해결하고 전문성을 키울 수 있는 기회를 제공했습니다.
그동안 대면으로만 이루어지던 해커톤이 온라인으로 개최되면서 참가자와 주최 측 모두에게 새로운 도전이 주어졌는데요. 이러한 온라인이라는 새로운 형식은 다양한 해커톤 참가자들을 이벤트에 불러모을 수 있었습니다. 총 6개의 팀은 3개의 HPC 분야 팀과 3개의 AI 분야 팀 또는 고등 교육 및 연구 분야(HER) 4개 팀과 산업 분야 2개 팀 등 다양한 구성을 가지고 있었습니다.
NVIDIA GPU 해커톤 팀에서는 이번 KISTI 해커톤이 참가자들에게 더욱 의미있고 성공적이었던 이유를 공개하였습니다.
멘토링
특정 영역이나 프로그래밍 언어에 대한 전문 지식을 바탕으로, 각 팀의 멘토들은 참가자들이 목표를 설정하고 다른 접근 방법으로 문제를 해결할 수 있도록 도왔습니다. 팀이 직면한 문제와 어려움에 대해서도 함께 해결하려고 노력했죠. 그리고 매일 멘토들끼리 각 팀에 대한 사안들을 공유하며 목표에 도달하기 위한 최고의 전략을 세울 수 있도록 함께 집중했습니다.
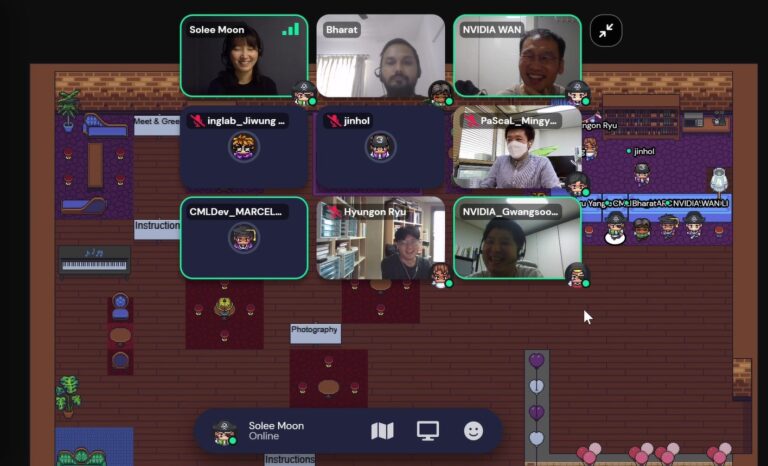
소셜 아워
사람들이 죽어라 일만 하고 놀지 않는다면 오히려 생산성이 떨어진다는 점을 알고 계신가요? 이번 해커톤에서는 참가자들과 멘토들을 위해 TGIF 소셜 아워 세션을 제공했습니다. 메타버스를 활용한 ‘게더 타운 스페이스(Gatter Town Space)’을 통해 프로젝트 수행 경험을 나누는 시간을 가졌는데요. 재충전의 기회 또는 앞으로 남은 활동에 대한 다짐의 시간을 가졌습니다.
기술 자원과 라이브 세미나
또 다른 성공 요소는 참가자들에게 전문적인 트레이닝 및 기술 리소스를 제공한 점입니다. 일례로, DLI 앰버서더이자 멘토는 CUDA C/C++를 주제로 한 NVIDIA DLI 워크숍을 해커톤 기간 내 라이브로 운영했습니다. 다른 멘토들은 프로파일링, 병렬 컴퓨팅, 최적화를 위한 TRT 및 NVIDIA Triton, OpenACC, Nsight 시스템에 중점을 둔 기술 세션을 팀 별로 진행했습니다.

참가자들의 성과
연세대의 PaScal팀은 난류의 열운동을 효율적으로 계산하는 코드를 개발하고 있습니다. 이번 행사를 통해 기존의 CPU 기반에서 제작된 코드를 OpenACC와 cuFFT Library를 통해 멀티 GPU 환경으로 변환했는데요. 결과적으로 계산 시간이 많이 소요되는 서브루틴 중 하나인 RHS를 4.84배 빠르게 계산 가능하도록 했습니다.
아모레퍼시픽의 Amore Opt팀은 DeepLab V3+ 세그멘테이션 모델의 GPU 최적화를 진행하고 있습니다. NVIDIA TensorRT 추론 최적화와 NVIDIA Triton 추론 서버에 대해 해커톤에서 배운 기법들을 적용하여 26배 빠른 추론 속도로 향상시켰습니다. 향후 피부 상태 분석을 위한 AI 모델에서 정확도를 유지하면서 대규모 고객 서비스를 위한 속도를 향상시키기 위해 이번 행사에 참가했죠.
Video 1. KISTI 해커톤에 참가한 TFC 팀의 인터뷰
서울대의 TFC팀은 CPU 기반의 포트란(Fortran) 인하우스 유체 계산 코드를 GPU를 사용하여 가속화하는 프로젝트를 가지고 참가했습니다. 계산 시간이 많이 소요되는 TDMA(Tri-Diagonal Matrix Algorithm)와 FFT(Fast Fourier Transform) 계산을 KISTI의 NVIDIA GPU를 통해 가속화했는데요. 단일 V100 GPU에서 11.15배 더 빠른 속도를 달성했습니다.
NVIDIA Inception 회원인 노타와 한양대학교의 NOTA-HYU팀은 INT4 양자화를 위해 NVIDIA Tensor Core GPU를 이용해서 노타 모델 압축 엔진을 최적화했습니다. NOTA-HYU팀은 NVIDIA 프로파일링 툴인 Nsight 시스템과 Nsight 컴퓨트 사용 방법에 대해 배웠습니다. 그리고 NVIDIA 라이브러리 CUTLASS를 적용해 CUDA를 최적화하여 레지듀얼 블록을 1.85배 가속화했습니다.
GPU 해커톤 및 향후 이벤트는 https://www.gpuhackathons.org/ 에서 확인할 수 있습니다.
또한, 9월 14일부터 15일까지 개최되는 OpenACC Summit 2021도 놓치지 마세요!